
Maths, Research, and Domains.
Joined March 2007
- Tweets 124
- Following 267
- Followers 599
- Likes 2,075
1 Photos and videos


Oslo retweeted

Mar 16
Introducing 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔: Rethinking depth-wise aggregation.
Residual connections have long relied on fixed, uniform accumulation. Inspired by the duality of time and depth, we introduce Attention Residuals, replacing standard depth-wise recurrence with learned, input-dependent attention over preceding layers.
🔹 Enables networks to selectively retrieve past representations, naturally mitigating dilution and hidden-state growth.
🔹 Introduces Block AttnRes, partitioning layers into compressed blocks to make cross-layer attention practical at scale.
🔹 Serves as an efficient drop-in replacement, demonstrating a 1.25x compute advantage with negligible (<2%) inference latency overhead.
🔹 Validated on the Kimi Linear architecture (48B total, 3B activated parameters), delivering consistent downstream performance gains.
🔗Full report:
github.com/MoonshotAI/Attent…

334
2,048
13,474
5,065,734
Oslo retweeted

Feb 24
Mercury 2 is live 🚀🚀
The world’s first reasoning diffusion LLM, delivering 5x faster performance than leading speed-optimized LLMs.
Watching the team turn years of research into a real product never gets old, and I’m incredibly proud of what we’ve built.
We’re just getting started on what diffusion can do for language.
318
577
4,210
1,028,081

Oslo retweeted

12 May 2024
people don’t just want the point,
they want the poetry
19
58
455
32,296
Oslo retweeted

7 Oct 2025
This is insane.
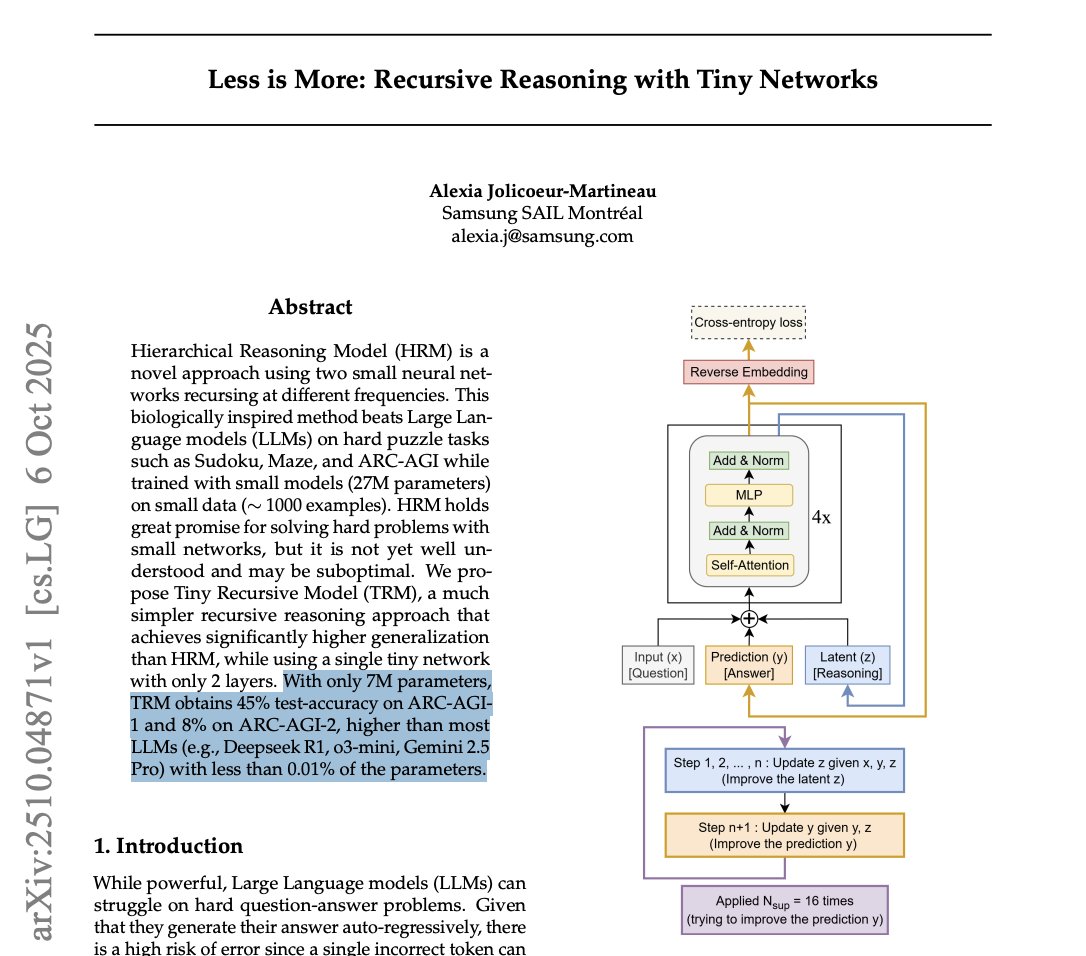
New AI model from Samsung, 10,000x smaller than DeepSeek and Gemini 2.5 Pro just beat them on ARC-AGI 1 and 2
Samsung’s Tiny Recursive Model (TRM) is about 10,000x smaller than typical LLMs yet smarter because it thinks recursively instead of just predicting text. It first drafts an answer, then builds a hidden "scratchpad" for reasoning, repeatedly critiques and refines its logic (up to 16 times), and produces improved answers each cycle.
This approach shows that architecture and reasoning loops (not just size), can drive intelligence. It enables powerful, efficient models that run cheaply, validate neuro symbolic ideas, and open highest quality reasoning to far more applications.
Acceleration is everywhere
7 Oct 2025

My brain broke when I read this paper.
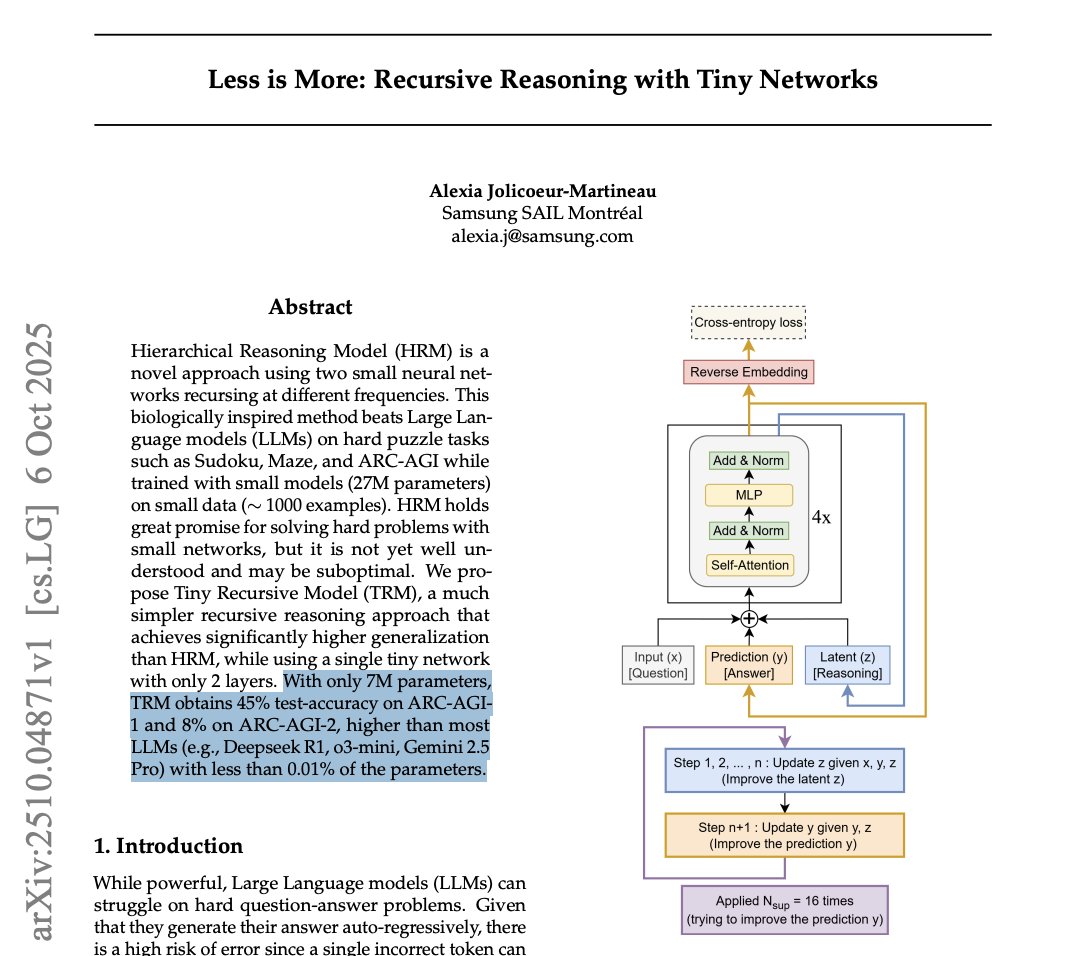
A tiny 7 Million parameter model just beat DeepSeek-R1, Gemini 2.5 pro, and o3-mini at reasoning on both ARG-AGI 1 and ARC-AGI 2.
It's called Tiny Recursive Model (TRM) from Samsung.
How can a model 10,000x smaller be smarter?
Here's how it works:
1. Draft an Initial Answer: Unlike an LLM that writes word-by-word, TRM first generates a quick, complete "draft" of the solution. Think of this as its first rough guess.
2. Create a "Scratchpad": It then creates a separate space for its internal thoughts, a latent reasoning "scratchpad." This is where the real magic happens.
3. Intensely Self-Critique: The model enters an intense inner loop. It compares its draft answer to the original problem and refines its reasoning on the scratchpad over and over (6 times in a row), asking itself, "Does my logic hold up? Where are the errors?"
4. Revise the Answer: After this focused "thinking," it uses the improved logic from its scratchpad to create a brand new, much better draft of the final answer.
5. Repeat until Confident: The entire process, draft, think, revise, is repeated up to 16 times. Each cycle pushes the model closer to a correct, logically sound solution.
Why this matters:
Business Leaders: This is what algorithmic advantage looks like. While competitors are paying massive inference costs for brute-force scale, a smarter, more efficient model can deliver superior performance for a tiny fraction of the cost.
Researchers: This is a major validation for neuro-symbolic ideas. The model's ability to recursively "think" before "acting" demonstrates that architecture, not just scale, can be a primary driver of reasoning ability.
Practitioners: SOTA reasoning is no longer gated behind billion-dollar GPU clusters. This paper provides a highly efficient, parameter-light blueprint for building specialized reasoners that can run anywhere.
This isn't just scaling down; it's a completely different, more deliberate way of solving problems.
218
1,256
8,285
1,121,448
Oslo retweeted

24 Sep 2025
Universities should abandon 4year degrees, and offer life-long learning programs.
283
175
2,087
108,642
Oslo retweeted

18 Sep 2025
Imagine having a vision so powerful that you are possessed by it for a decade.
Wrote down the first equations for a version of thermodynamic hardware 10 years ago.
Today did a first external demo with a portable room temperature prototype version of this vision.
Exponentials take a long time to start, but once they get going, they become unstoppable.
So excited for the next years as the world wakes up to the power of probabilistic silicon.
53
44
763
58,571
Oslo retweeted

12 Aug 2025
Chinese scientists have developed the best shortest-path algorithm in 41 years! A team from Tsinghua University has broken Dijkstra’s “sorting barrier” — the first improvement since 1984.
The new algorithm runs in O(m \log^{2/3} n) time. Potential applications? Faster shorter waits for route calculations, fewer traffic jams, cheaper deliveries, and more efficient computer networks. And, of course, a need to update computer science curricula :)

194
1,437
8,398
1,278,440

