
Joined October 2023
- Tweets 2,528
- Following 404
- Followers 413
- Likes 3,994
407 Photos and videos












Pinned Tweet
Agenvoy mcp-server.
Give Claude Code, Codex, or any agent the power to build its own tools.
(Coming soon)
19
目前 twitter 覺得小弟我像是機器人🤖
所以限制我一個小時只能追蹤與按讚各一個,目前只有留言沒受限制
追蹤我的兄弟姐妹們,我會努力每個小時回追一個
按讚部分就先讓我略過(但一定會回覆)🙇♂️
38
A personal AI Agent that runs on your machine—builds tools, searches files, automates tasks, and learns from its mistakes.


1
3
80
後續的未來就是經驗為王的時代

海外网友扒了1680 份 Anthropic 工程师的简历,先说我觉得最反常识的几点:
第一,招的几乎全是搞 infra 的,不是 researcher。
第二,几乎不招初级员工。中位数的工作经验是12.2年。只有13%的人有博士学位。
第三,最大的人才来源不是OpenAI和DeepMind,而是Google和Meta。
第四,如果是 junior ,一个特别"干净"的典型画像是这样的:MIT,IOI 银牌,Codeforces 2900 。
一篇非常好的文章,作者是做招聘的,把当前雇主一栏写着 Anthropic 的 LinkedIn 主页全爬了下来,共 5306 人。从里面筛出 1680 个真正做工程的,再去翻他们进 Anthropic 之前写的 7986 段过往岗位描述。
可以一观Anthropic的人才构成。
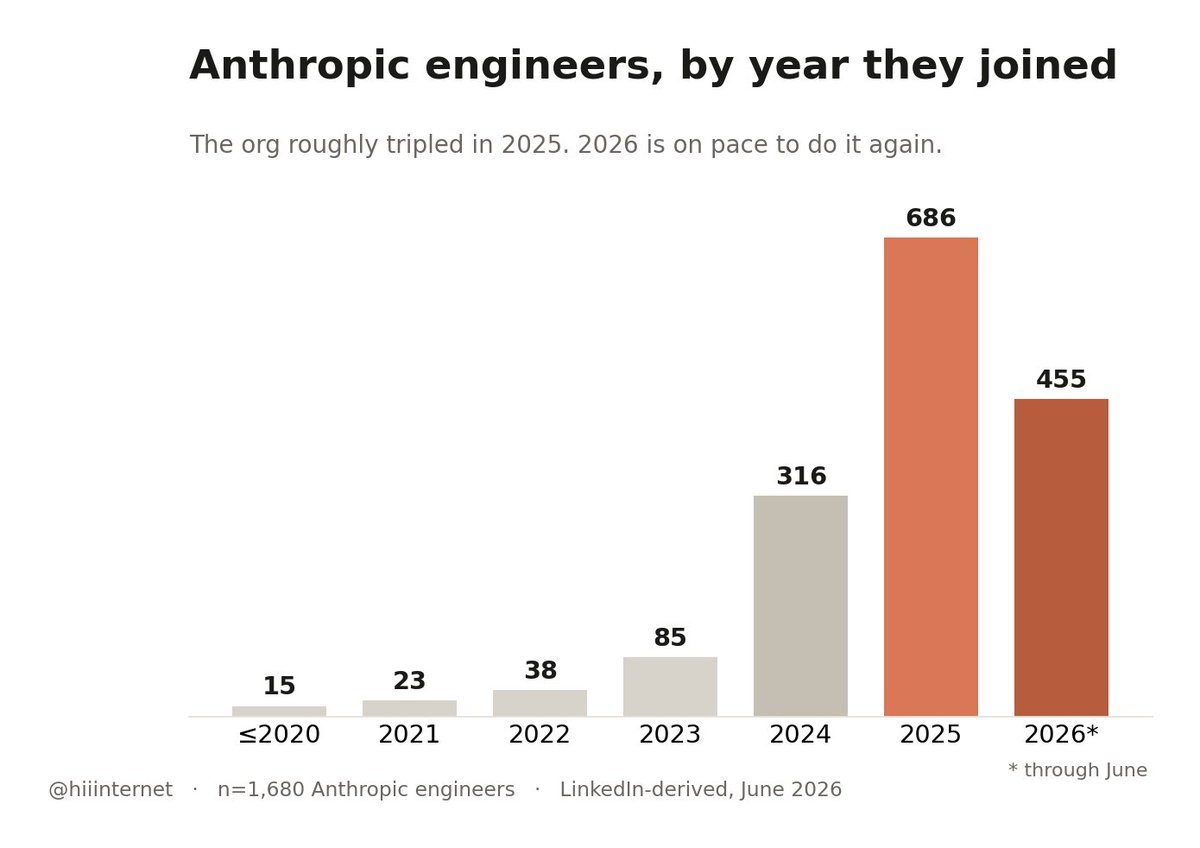
1、Anthropic几乎是一夜之间把团队搭起来
现在还在 Anthropic 的工程师里,2021 年之前就进来的,只有 15 个人。
真正的大扩张是在2025-2026年。2025 年一年,工程组织差不多扩了3倍,招了686个。2026 年看起来也会接近这个节奏:截至 6 月,已经招了455个。
现在团队里一半人入职还不到一年,过去 12 个月进来的占53%,在职时间中位数10个月。
也就是说,这是一个在大概 18 个月里,被非常快地搭起来的巨型团队。
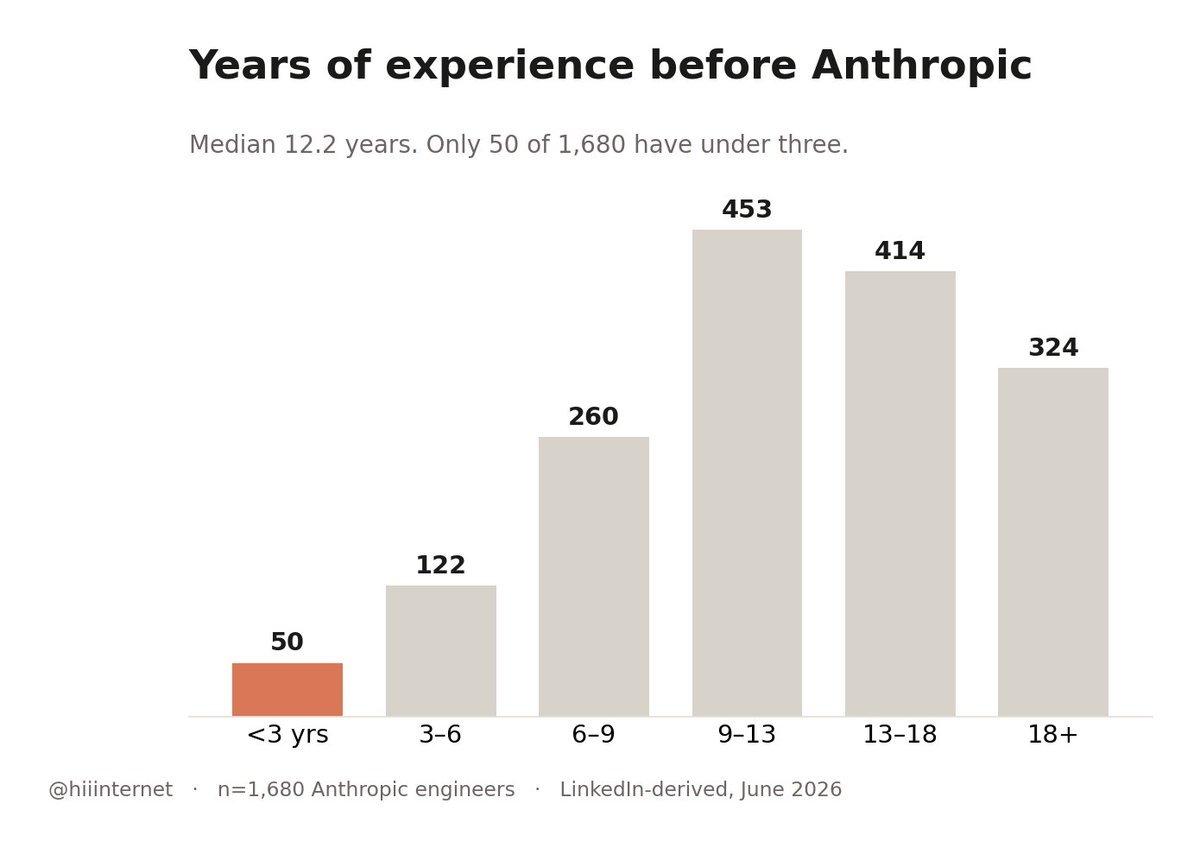
2、他们几乎只招资深工程师
这条我觉得最反常识。
进Anthropic之前,这些人的中位工作经验是12.2年。中间 50% 的人,经验8.8到16.5 年。
1680个人里,工作经验不到3年的只有 50 个;44%的人有 13 年以上。应届这块基本等于没有。
所以一个典型的 Anthropic 新人是这样的:已经工作 12 年,但进公司才 10 个月。
3、他们其实更看重 infra,不是我们以为的“搞研究”
40% 的人背景里出现了 infrastructure。
backend、distributed systems、databases、security 这几个方向,各自都在 20% 左右。
而reinforcement learning,只有3.3%人。
也就是说,典型的 Anthropic 工程师,过去十年更像是在 hyperscaler 或 infra-heavy startup 里搭大规模生产系统的人。
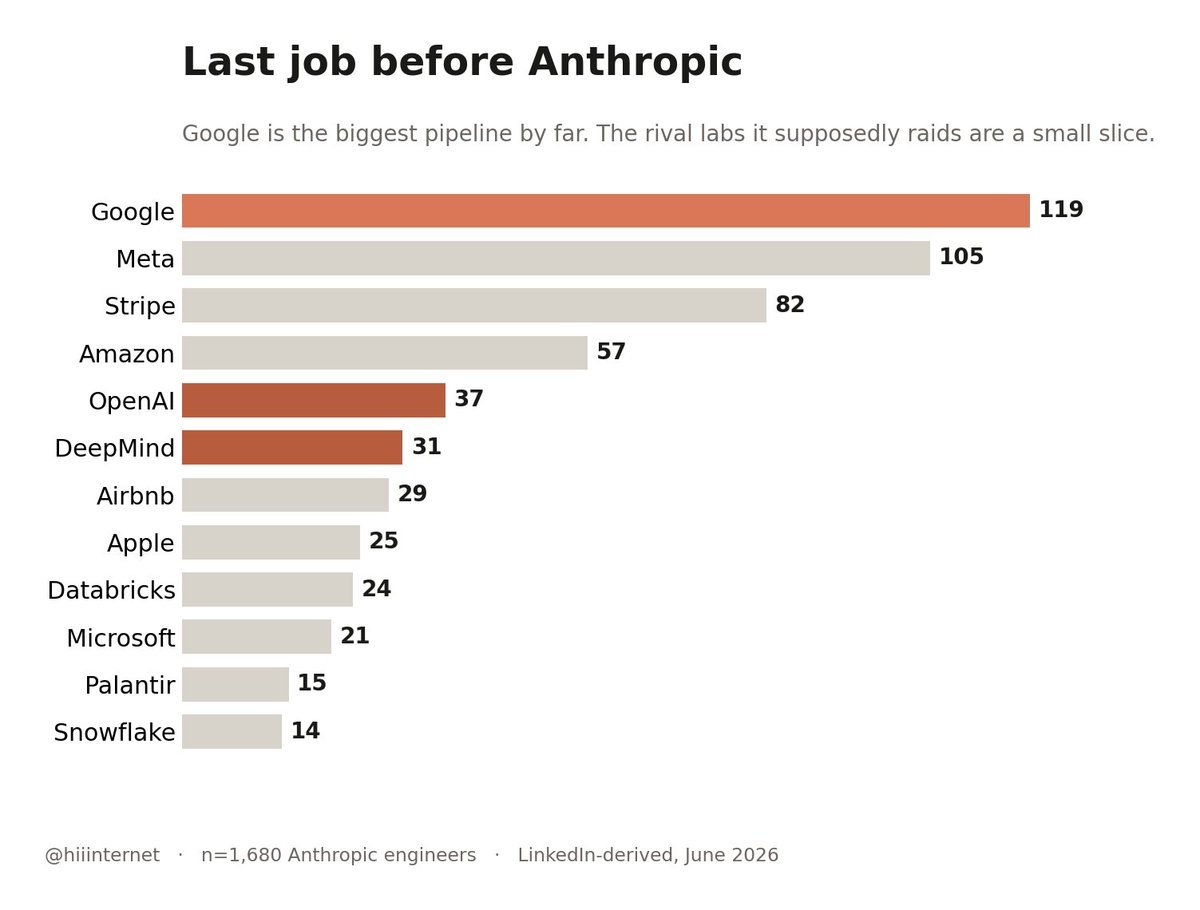
4、最大的人才来源不是 AI lab,是 Google
大家总觉得 Anthropic 很多人来自 OpenAI 和 DeepMind。
但实际上,它最大的人才管道是 Google,而且领先很多。
除了 Google,它明显还偏爱那些以工程严谨著称的地方:Stripe、Databricks、Snowflake、Palantir、Airbnb。

1
92
這種已經10:1的差距了,大家就別被騙關了



1
2
84
再說一次,只會用 ai 與會用 ai 是兩件事
撇除 ai 再厲害也就只是個會朗讀百科全書的工具這件事
當每個人都有 ai 了,你覺得只會用 ai 的人的優勢在哪?
沒有專業的人用 ai 就跟小學生用科學計算機一樣
只能用出少部分性能,並且沒有足夠知識拆解問題與問對問題

2
63
Agenvoy - An agent framework that writes its own tools and repairs itself.
Make AI actually work for you.
34

Jun 14
把「依據問題自動生成可復用工具」
做成 mcp 給 claude code / codex 任何你們熟悉的 agent 使用
讓你們熟悉的環境會自己長工具、且是在沙箱執行
你們會覺得方便嗎?
1
38
Jun 14
jarvis-alpha 分支
目前還是被我歸類為不太實用的功能,所以跟 linebot 一樣只放分支
(影片都有加速)
需解決兩個問題
1. 渲染速度
2. 7/24 的背景語音偵測
這兩件事都處理好我就會合併進主要功能
35
Jun 14
推上面有些人現在在推 fable 5 的提示詞給 opus 4.8 用就能達到 fable 5 的水準
相信的人是真的覺得雲端模型商花費那些電費在訓練都是笑話嗎?
這麼容易能做到,要不你來?
25
Jun 14
當你離開 x / threads 的演算法,你會發現身邊其實也沒多少人需要 ai
就算知道 ai 的人,多數也只停留在網頁版問問題,偶爾修改個文案或翻譯而已
26
Jun 14
這是在玩火,等下真的連 gpt 5.5 都被禁用就不好玩了

We've updated the Artificial Analysis Coding Agent Index, replacing SWE-Bench Pro with Datacurve's DeepSWE benchmark - the swap lifts Codex with GPT-5.5 (xhigh) above Claude Code with Opus 4.8 (max), while the newly released Claude Fable 5 (max) in Claude Code debuts at the top
DeepSWE, built by @datacurve, writes its tasks from scratch rather than adapting them from public GitHub issues or pull requests, so no model has seen the solutions during training. That matters because SWE-Bench Pro, the benchmark it replaces in our Coding Agent Index, had grown gameable, with some models recovering the fix from the repository's commit history instead of solving the task.
The swap reorders the index: Codex with GPT-5.5 (xhigh) rises from 65 to 76, overtaking Claude Code with Opus 4.8 (max) at 73. Claude Code with Fable 5 (max), which enters directly on the refreshed index, leads at 77. SWE-Bench Pro had been flattering some combinations and penalizing others.
More below.

39