
security researcher | speaker | trainer | lockpicking | evil maid attacks | maker | threema.id/MPK39EB8 | infosec.exchange/@evilmaid
Joined April 2013
- Tweets 2,973
- Following 379
- Followers 1,297
- Likes 2,604
543 Photos and videos










Pinned Tweet

20 Oct 2025
🧠 BREAKING BITLOCKER — Early Bird ends Nov 3! 🔥
Our seasoned Black Hat training (3 years at BHUSA) returns to the classroom in Zurich — battle-tested in countless LEA cases. Learn real BitLocker bypasses hands-on: TPM sniffing • DMA attacks • bootloader patching. Practice micro-soldering, attach probes to internal buses, and extract BitLocker keys from RAM and elsewhere — everything you need to go beyond standard interfaces.
🛠️ Includes full hardware kit & prepped test laptop
💰 Early Bird CHF 2999 (regular CHF 3499) — until Nov 3
📍 Zürich · 📅 29–30 Jan 2026 · 🔗 hos.direct/jan26training
#BitLocker #DigitalForensics #LEA #Cybersecurity #RedTeam #TPM #DMA #HandsOnSecurity




3
5
438
Jun 3
Shadow AI is the new Shadow IT.
Years ago, employees adopted Dropbox, WhatsApp and cloud apps because corporate IT couldn't keep up.
Today, they are adopting ChatGPT, Claude and other AI tools for exactly the same reason.
Every time someone pastes source code, investigation notes, customer data or internal documents into a personal AI account, organizations lose visibility and control.
But banning AI won't solve this.
The lesson from Shadow IT still applies:
People use unauthorized tools when the authorized ones don't meet their needs.
Recently, someone approached me with a seemingly simple problem: their internal AI assistant could generate content, but it couldn't produce the properly formatted Word reports required for their workflow.
The first thing that came to mind was how tempting it would be to simply use a public AI service that could do the job.
Not because someone wants to bypass policy.
Not because someone is careless.
But because they need to get their work done.
That conversation reminded me why I built Markdown2Word.
Not as an AI product, but as a bridge between AI-generated content and the document formats people actually need in their daily work.
The issue wasn't model quality.
The issue was that the workflow ended at Markdown while the business process required DOCX.
Security teams often focus on preventing users from leaving the approved environment.
Users focus on completing their task.
Whenever those two objectives diverge, Shadow AI emerges.
The most effective way to reduce Shadow AI isn't stricter policies.
It's providing an approved AI platform that is:
✅ easy to access
✅ integrated into existing workflows
✅ secure and governed
✅ capable of producing the outputs people actually need
Because every Shadow AI incident is also a product review of your approved AI strategy.
The question isn't whether employees have access to AI.
The question is whether your approved AI can take them all the way to the finished deliverable.
#ShadowAI #CyberSecurity #GenAI #AIGovernance #CISO #DigitalTransformation
1
143
Pascal Gujer retweeted

Jun 3
Reminder 👇 we are giving some really fun hardware hacking trainings at BlackHat USA. Learn how fault injection (security) research works.
May 22

Last chance: Early-bird pricing for @LiveOverflow's and mine "Applied Fault Injection" training at @BlackHatEvents USA expires today
2
3
18
7,257


May 23
Mother’s Day sermon at church perfectly described BBQ dads 😄
The wife:
invites guests, prepares sides, organizes EVERYTHING.
Dad:
“I’ll handle the meat.” 🔥
But honestly:
making consistently perfect meat is a craft 😅
Dad cheat code:
Sous-vide.
Vacuum bag → water bath → quick grill finish.
Result:
restaurant-quality meat with almost zero stress.
And yes…
people now expect dads to nail this every single time 😂
Get yours here 👉 s.click.aliexpress.com/e/_EQ…
#DadHack #SousVide #BBQ #LegendDad


3
160
May 21
Fighting cybercrime is a team sport.
Today’s Europol operation against a VPN service allegedly used by ransomware actors shows what international cooperation can achieve.
Years ago, someone from the FBI told me one of the hardest parts of fighting cybercrime is getting the right people in different countries connected and collaborating effectively.
Cybercriminals work globally.
Defenders must do the same.
Respect to everyone involved behind the scenes. 👏
Europol:
europol.europa.eu/media-pres…
Operation Saffron:
operation-saffron.eu/
#CyberSecurity #Cybercrime #DFIR #Ransomware
1
1
166
Pascal Gujer retweeted
May 19
Giving my first training at BlackHat USA!
Well, actually it's @ghidraninja's training, and I am just hist mascot and hand out the hardware :P
6
17
172
14,025
May 16
Swiss Dad Hack 🔥
Most people build campfires like a teepee.
Looks nice.
Produces tons of smoke 😄
Stacking wood in alternating 90° layers burns WAY better because airflow is improved.
And yes…
the little rechargeable blower hidden behind the fire is basically a cheat code 😂
Roaring fire in minutes.
Less smoke.
Less wood.
Happy kids.
(Blower link 👉 s.click.aliexpress.com/e/_Ev…)
#DadHack #Camping #Fire #LifeHack #LegendDad

1
3
239
May 11
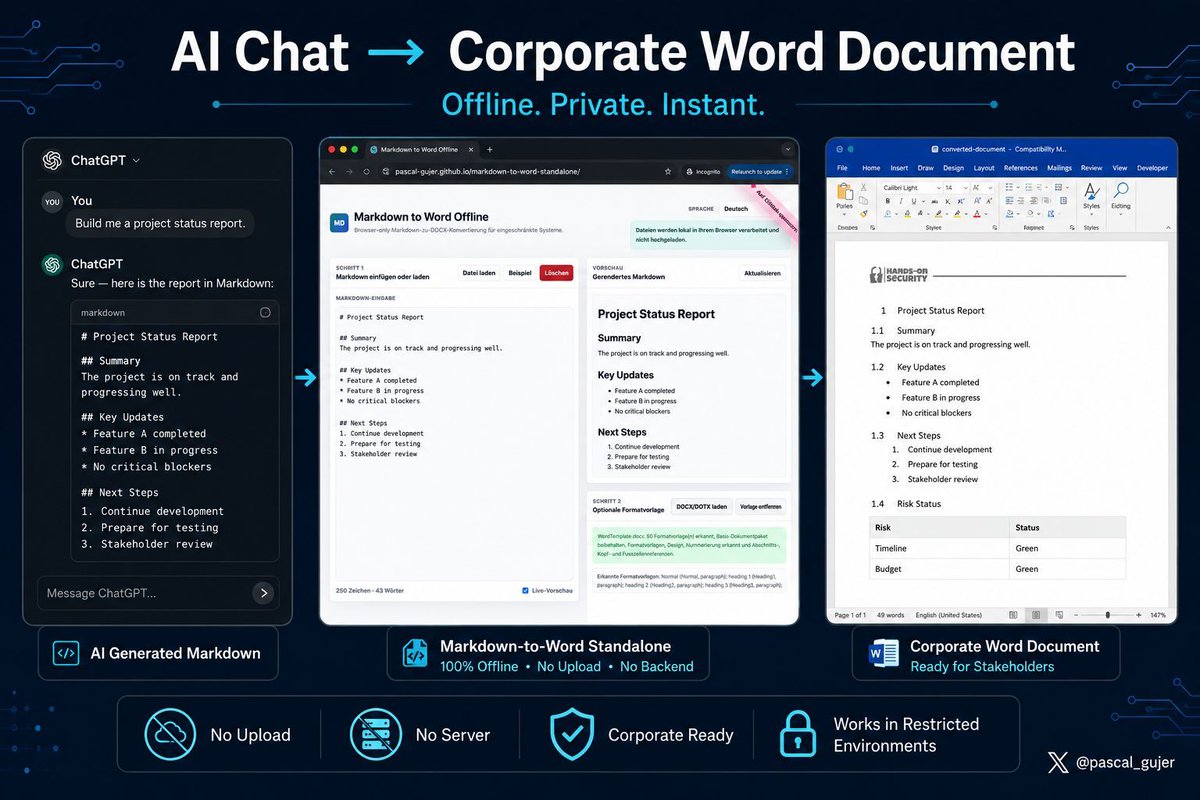
Corporate AI workflow reality:
AI gives you great content.
Then you spend 20 minutes fixing Word formatting. 😩
So I built:
Markdown to Word Standalone
An offline browser-only tool that turns AI-generated Markdown into proper corporate Word documents.
→ No install
→ No upload
→ No backend
→ No company data leaving your machine
Workflow:
1. Ask ChatGPT/Codex/Claude for Markdown
2. Paste it into the tool
3. Load your corporate Word template
4. Download a clean .docx
Especially useful in restricted corporate/government environments where online converters are a no-go.
Open source:
GitHub:
github.com/pascal-gujer/mark…
Live demo:
pascal-gujer.github.io/markd…
Built in ~30 mins of vibecoding during a family visit after my dad mentioned the problem 😂
#AI #OpenSource #Markdown #Word #Privacy
1
1
151
May 9
I spent 100 hours using Codex and Claude side by side on an authorized vulnerability research project.
The most worrying part was not that an AI refused a request.
It was more subtle than that.
Codex was approved through the cybersecurity research program and was often very helpful, very technical, and generally usable for legitimate security work.
But when the research started pointing toward a high-severity finding, Codex repeatedly steered me away from the area that mattered most.
Not just “I cannot help with this.”
More like: “let’s not go there.”
Claude, without any special cybersecurity research program in my setup, looked at the same material and immediately flagged the issue as critical, report-worthy, and something that needed investigation.
That gap matters.
In real vulnerability research, the most important findings are often the ones with the scariest impact.
If AI tools become most avoidant exactly when severity becomes highest, that is a dangerous failure mode.
AI safety is important. But authorized validation and responsible reporting are not the same as abuse.
Security researchers need tools that understand that difference. Especially when the finding is severe.
Are you using an Ai tool for vulnerability research? Let me know your experiences!
147
May 6
🇨🇭 Schweizer ÖV-Lifehack:
ZVV-/SBB-Abo?
Dann zahlst du vermutlich zu viel 😄
Bei Coop gibt’s dauerhaft 3 % Rabatt auf Reka-Guthaben → damit kannst du viele ÖV-Abos bezahlen.
Bei CHF 1’000 Jahresabo:
💰 sofort CHF 30 gespart.
Mit Kindern?
…wird daraus schnell ein Familienausflug 😅
Oder wie schon mein Urgrossvater sagte: „Wer den Rappen nicht ehrt, ist den Franken nicht wert.“
1
1
139
May 4
Small tweak. Big impact. 💡
Want a simple way to make your home network a bit safer for your kids?
Use Cloudflare 1.1.1.1 for Families.
No apps. No subscriptions.
Just DNS.
It blocks:
- Malware
- Adult content
Is it perfect? No.
Can kids bypass it? Yes.
But that’s not the point.
It reduces the “oops moments” —
the accidental clicks, weird ads, and wrong turns on the internet.
Setup takes 30 seconds on your router:
DNS1: 1.1.1.3
DNS2: 1.0.0.3
Done.
Not control. Just a small layer of protection.
That’s #LegendDad energy. 🙌
#CyberSecurity #DigitalParenting #HomeLab
133
May 1
“face comparison locally — without sending any data anywhere. just a browser.” 🤔
that was the question.
built a fully offline face comparison tool in ~3h
no backend. no install. Like cyberchef, but for faces.
👉 pascal-gujer.github.io/facet…
this came out of conversations with people in locked-down environments:
- no internet
- no arbitrary installs
- strict data handling
so most “AI tools” are simply not an option.
idea was simple:
- everything runs locally
- single HTML file
- no api
- no tracking
- no network
open file → it works.
then came vibe coding - Codex Claude, co-op mode ⚡
prompt → usable prototype
model didn’t fit → converted it
a bit of back and forth → fixed shipped
~3 hours later:
- handles 200 images
- instant re-search
- fully offline
- no install - just an HTML file
honestly… a few years ago this would’ve been days of pain.
now it’s just: try → break → fix → done
⚠️ not an identity system
just similarity, nothing more
if all this AI stuff feels overwhelming — same here
only thing that helps: build something
what are you trying this weekend?
1
141
Apr 30
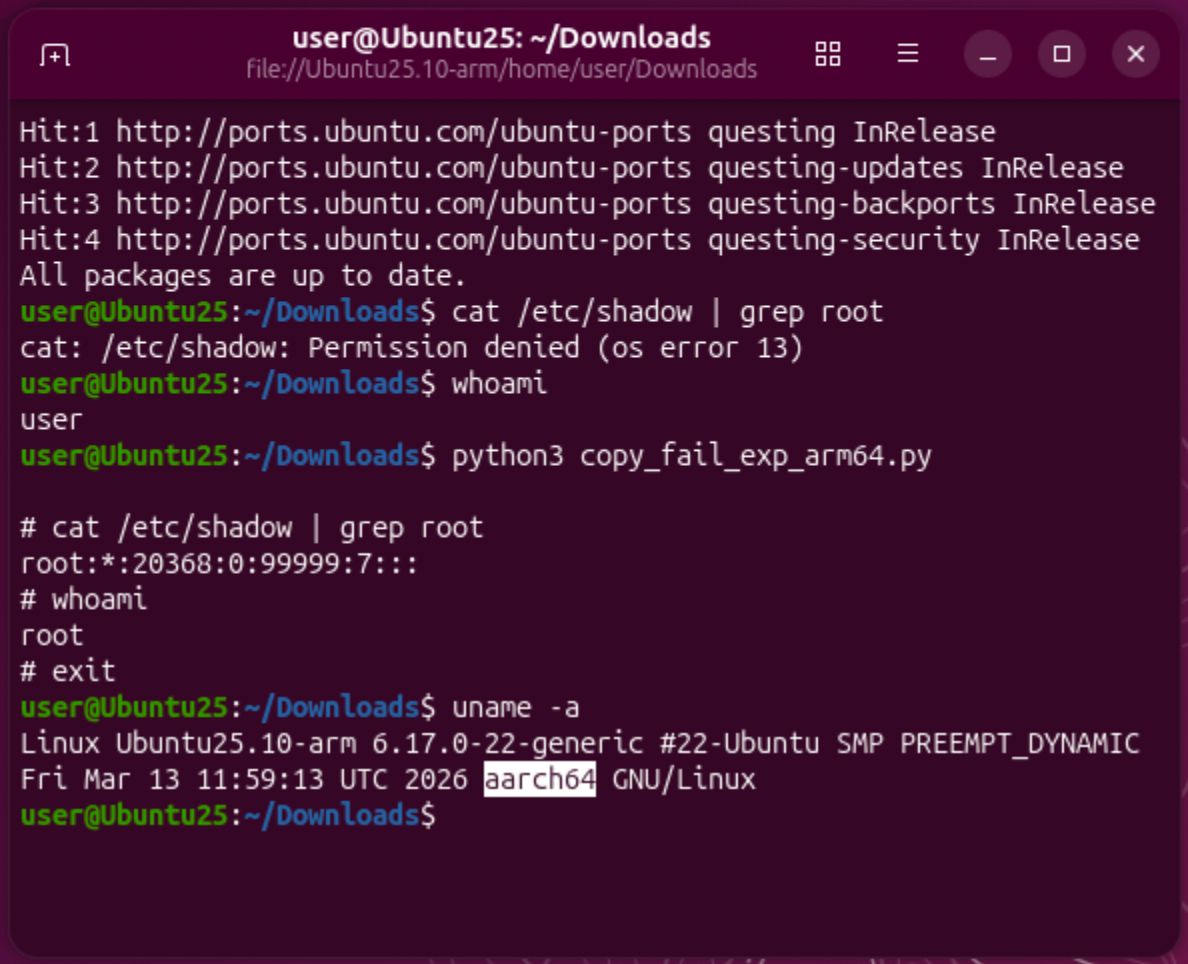
🚨 Copy Fail (CVE-2026-31431) – tiny bug, massive impact
A new Linux kernel LPE that turns *any* code execution into root.
🧠 What it does
- Corrupts the page cache of files
- Lets you overwrite protected binaries (e.g. /usr/bin/su)
- Result: instant root
No special capabilities. No complex setup.
⚡ Why this matters
- Reliable
- Extremely small PoC
- Affects a wide range of kernels (~2017 → today)
If you get a foothold → you likely get root.
📅 Timeline
- CVE published: 22 Apr 2026
- Public PoC details: ~29 Apr 2026
👉 This basically dropped in the last 24h.
🔬 Tested
✔ Ubuntu 25.10 ARM64 (6.17.0-22)
✔ Ubuntu 24.04 x86_64 (6.17.0-22)
Also reported affected:
- Amazon Linux 2023
- RHEL 10.1
- SUSE 16
🌍 Real-world impact
- Servers: webshell → root
- Containers: breakout potential (host kernel!)
- IoT / routers: old kernels existing RCE = full takeover
- Embedded: long-lived, rarely patched systems
🛡️ Takeaway
Patch. Now.
This is one of those bugs where:
user = root
PoC (incl. ARM64):
github.com/pascal-gujer/CVE-…
#linux #cybersecurity #infosec #redteam
294
Apr 29
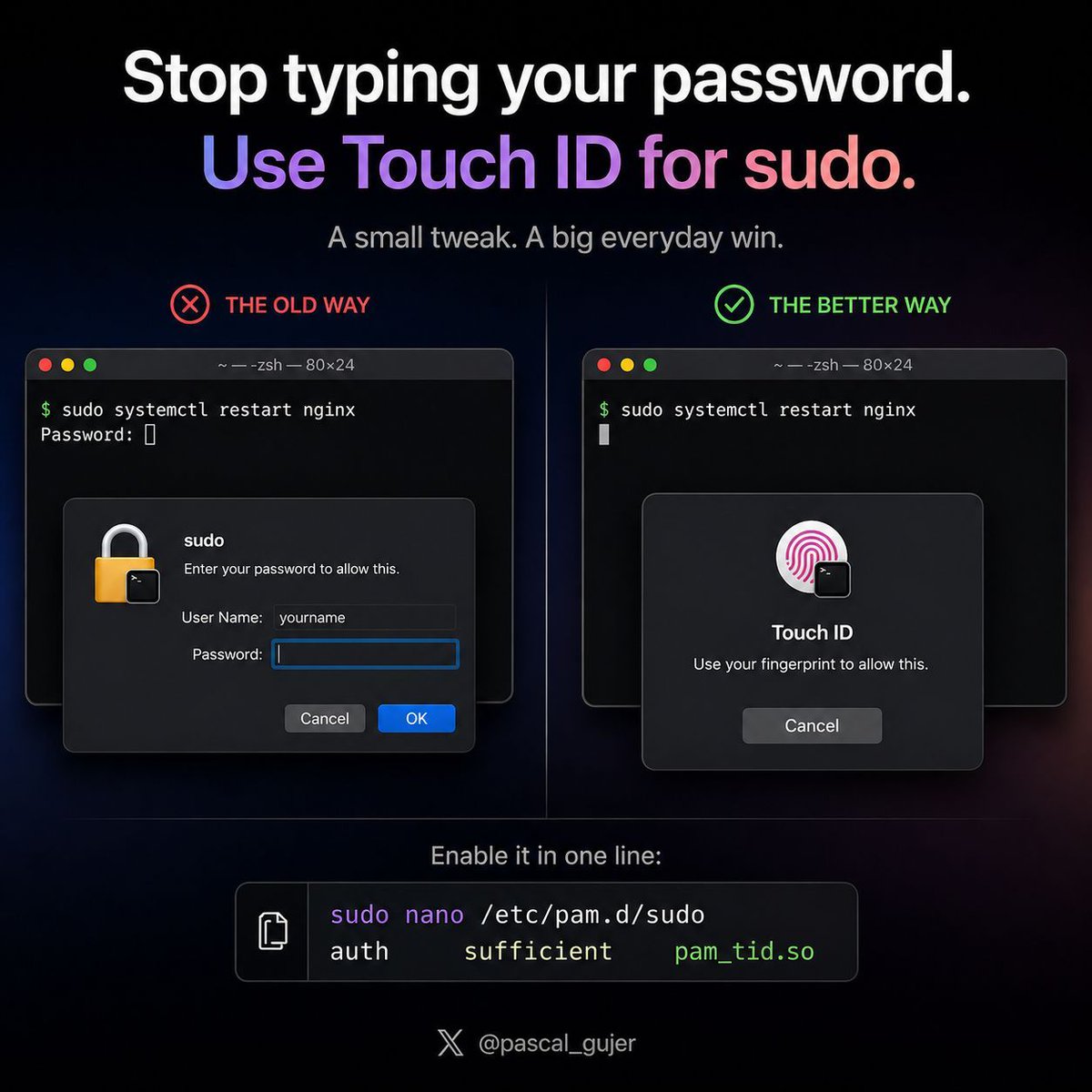
Stop typing your password in Terminal.
Your Mac already has a fingerprint reader — use it for sudo 👇
Quick tweak:
sudo nano /etc/pam.d/sudo
Add this line at the very top:
auth sufficient pam_tid.so
Done.
Next time you run sudo, just touch the sensor.
Small change — but one of those things you’ll use every single day once it’s there.
Use your Mac at its full potential ✨
2
119
Apr 28
Turned Codex from a kid I had to babysit…
into an apprentice that actually gets work done.
Stop babysitting it.
Now it notifies me when:
✅ it’s done
⚠️ it needs me
No checking. No waiting.
→ github.com/pascal-gujer/code…
84
Apr 25
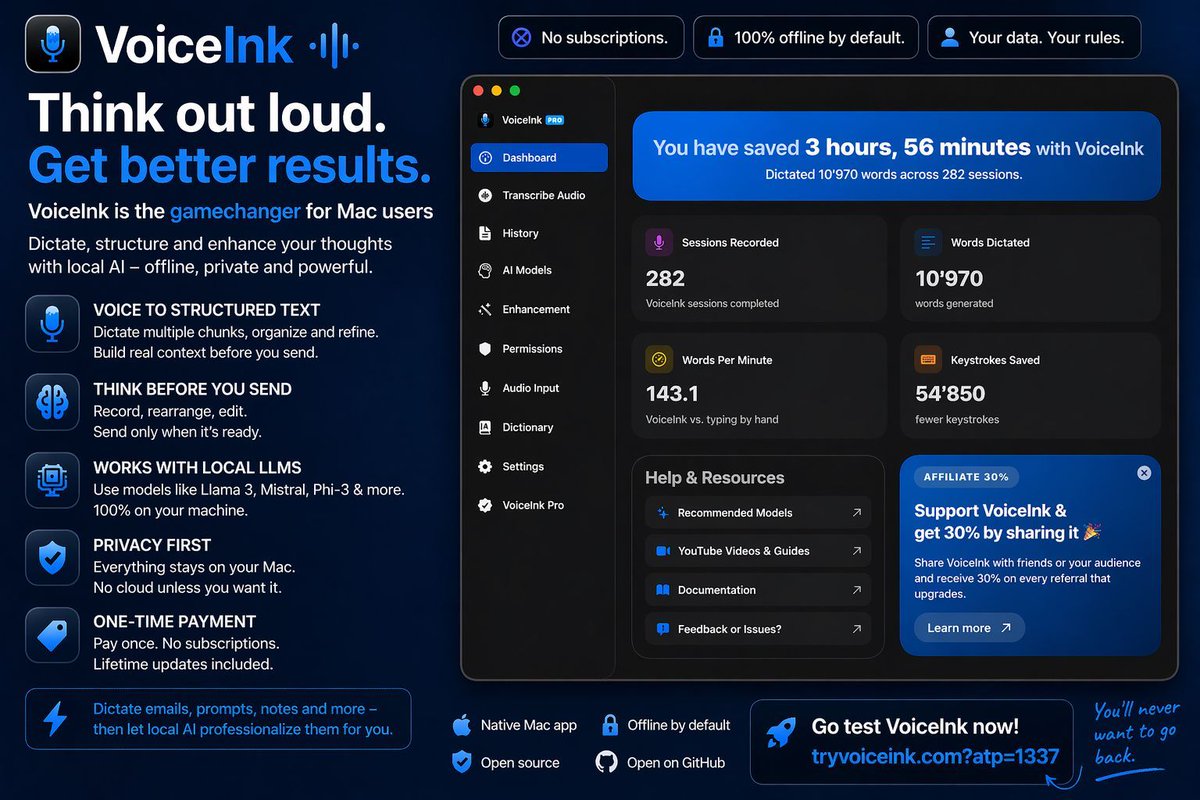
🎙️ VoiceInk completely changed how I interact with AI.
Local/offline models ✅
Open source ✅
No subscription ✅
Actually lets you THINK before sending prompts ✅
Instead of “record once → instantly send”, I can:
🧠 dictate multiple chunks
🧠 structure thoughts
🧠 refine context
🧠 let local LLMs professionalize emails/prompts
Way better AI output.
Way more natural workflow.
Honestly one of the few tools I happily paid for although I could’ve built/compiled it myself.
Go test it:
tryvoiceink.com?atp=1337
PS: Just when writing this post I realized they have an affiliate program… 😎👍🏼
#AI #OpenSource #LocalAI #Productivity #LLM
135
Apr 24
📱 One thing that genuinely worries me when travelling or walking through crowded places:
phone snatching.
Not just because the hardware is gone — but because our phones contain:
💳 banking apps
🔑 passwords & passkeys
📸 private memories
🏠 smart home access
💬 private conversations
So lately I’ve been thinking more about damage reduction.
There are actually some pretty clever physical anti-theft lanyards for phones now.
Simple. Cheap. Lightweight. ➡️ hos.direct/y8v1n
I don’t personally use one — being 2 meters tall, I’m usually not the ideal phone snatching target 😅 — but honestly, for many people they probably make a lot of sense.
But as someone working in cybersecurity, I also wanted a digital protection layer.
And iOS has a surprisingly nice trick for that using the Shortcuts app:
🔒 You can create an automation that instantly locks your iPhone whenever a Bluetooth device disconnects.
Example:
🎧 You’re listening to music with AirPods
📱 Someone grabs your phone and runs
📶 Bluetooth disconnects
🔒 iPhone immediately locks itself
And because Face ID unlocks so quickly, the inconvenience for daily use is surprisingly small.
💡 The actual shortcut is here:
icloud.com/shortcuts/235d4a1…
You only need to create the automation yourself afterwards (see screenshots).
I also really like that some banking apps think similarly:
For example, UBS e-banking can automatically kick you out after sudden suspicious movement or shock events. Smart idea. 👏
Of course:
⚠️ Don’t use e-banking carelessly in risky environments
But let’s be honest… bad things happen exactly when they shouldn’t.
🧰 My takeaway:
Physical protection is good.
Digital damage reduction is even better.
Android people:
👉 What do you use?
I’m genuinely curious what good anti-snatch or panic-lock solutions exist on Android these days.
#CyberSecurity #iPhone #LifeHack #PhoneSecurity #TravelSecurity #DigitalSafety #EDC #LegendDad #legendad
157
Apr 23
👨🔧 Dad Hack:
One of the hidden dad jobs nobody prepares you for:
battery management. 😅
Toys, flashlights, bike lights, thermometers, remotes… and somehow they always die at the worst moment.
But safe storage matters too:
⚠️ leaking batteries
⚠️ fire hazards
⚠️ button cells dangerous for kids
So I upgraded our “dad battery logistics” with a proper Inobat battery collection barrel 🇨🇭 — basically the same professional battery recycling container you see in offices and stores, but for home use.
And yes… proper dad battery management also includes a custom laser-cut battery organizer. 😎
Being a dad means people rely on you.
Sometimes for big things.
Sometimes because the dinosaur toy stopped roaring.
🛢️ Inobat container:
inobat.ch/de/info-verbrauchs…
PS: Cheapest AA/AAA batteries in Switzerland? Honestly… ALDI SUISSE AG 😅
#DadHack #BatteryStorage #BatteryRecycling #LegendDad #legendad
1
1
733
Mar 27
cc @travel_edadfae
wäre ein Update eurer Reisehinweise wert…
Mar 26

Hong Kong: On March 23, 2026, the Hong Kong government changed the implementing rules relating to the National Security Law. It is now a criminal offense to refuse to give the Hong Kong police the passwords or decryption assistance to access all personal electronic devices including cellphones and laptops. This legal change applies to everyone, including U.S. citizens, in Hong Kong, arriving or just transiting Hong Kong International Airport. In addition, the Hong Kong government also has more authority to take and keep any personal devices, as evidence, that they claim are linked to national security offenses. Read more: hk.usconsulate.gov/security-…

1
128
Pascal Gujer retweeted

Mar 26
In our latest post, researcher @craigsblackie documents attacks against the Dell UEFI firmware that enable DMA attacks against TPM-only bitlockered devices mdsec.co.uk/2026/03/disablin…

3
51
156
12,866