
Be disruptive in the making
Joined March 2019
- Tweets 167
- Following 79
- Followers 27
- Likes 294
44 Photos and videos












Let's be honest. ☝️ Large models like #huggingface transformers are expensive to run.
In this FREE webinar, we present our cost-effective and yet scalable solution. eventbrite.com/e/deploy-tran…
#Transformers #NLP #MachineLearning #webinar
1
2

17 Jan 2022
I am normally all @GaryMarcus when it comes to AI, but oh boy, the harder it is to model a problem, the more I believe in @ylecun 's perspective. Strictly speaking of course.
#ArtificialIntelligence #DeepLearning
3
2 Jan 2022
Generating text with #Cheapity3 can prove to be a great and cheap resource for multilingual data generation.
This simple frontend was built with 3 lines of code using @Gradio.
The model is on the HF hub and Github.
github.com/flexudy/NLPlaySto…
huggingface.co/flexudy/cheap…
2
5
25 Dec 2021
Looking for a cheap open-source multilingual (🇩🇪🇫🇷🇬🇧) alternative to " #gpt3 " ? In particular for academic text?
Well, then Merry Christmas. 🎁😃. T5 available on @huggingface hub and on GitHub.
huggingface.co/flexudy/cheap…
github.com/flexudy/NLPlaySto…
#NLP #Transformers #DeepLearning
1
1
pascalzoleko retweeted

2 Dec 2021
We’re releasing the 1.0 version of Opacus, a #PyTorch training library that makes it easier for researchers to adopt differential privacy in #ML. Opacus 1.0 will accelerate differential privacy research in the field. Learn more: opacus.ai/
6
63
271
7 Oct 2021
There is a new challenging EXtractive QA dataset. Question operators are based on didactic principles like Bloom's taxonomies.
Want to see how well your QA model performs? Download it at: github.com/flexudy/ai-powere… or on the @huggingface hub. #NLP #DeepLearning
1
14 Sep 2021
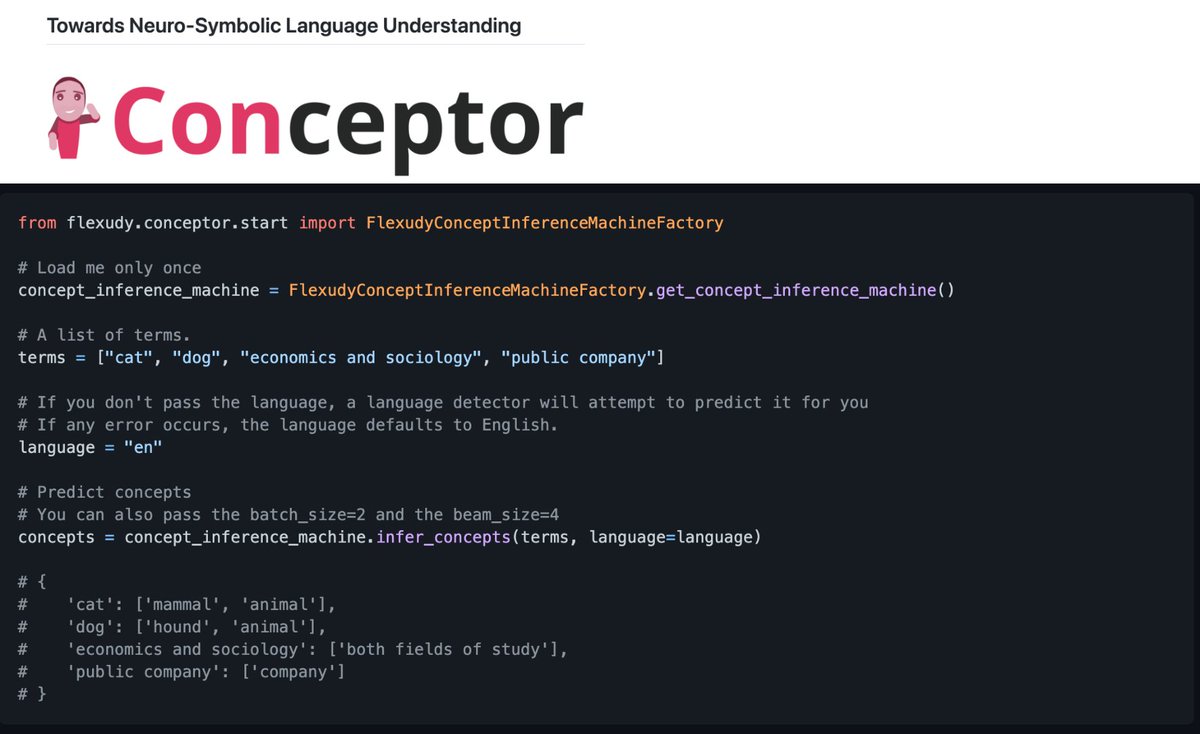
🎯 The Conceptor is now available on the @huggingface 🤗 hub. Generate concepts or types E.g A dog is an animal.
Ideal for Zero-shot tasks, logical reasoning, NER, QA or even text or intent classification pipelines.
github.com/flexudy/natural-l…
#NLP #ArtificialIntelligence
2
8 Jun 2021
Start building #NeuralNetworks backwards. The heart of true #ArtificialIntelligence is knowledge acquisition. Not consumption.
I think it aligns well with people with this belief: "abstraction is the key".
1
1 Apr 2021
The field of #ArtificialIntelligence is conquered 😃?
No more need for Transformers or GPUs?
#DeepLearning #MachineLearning
Create #Flashcards in one click with #Flexudy.
Simply choose the documents that you want to #study with and get right into it. Study on the go with the Flexudy app for Android and iOS or boost your study sessions with the Flexudy web app.
Studying has never been this easy 🤓
2
2
pascalzoleko retweeted

17 Feb 2021
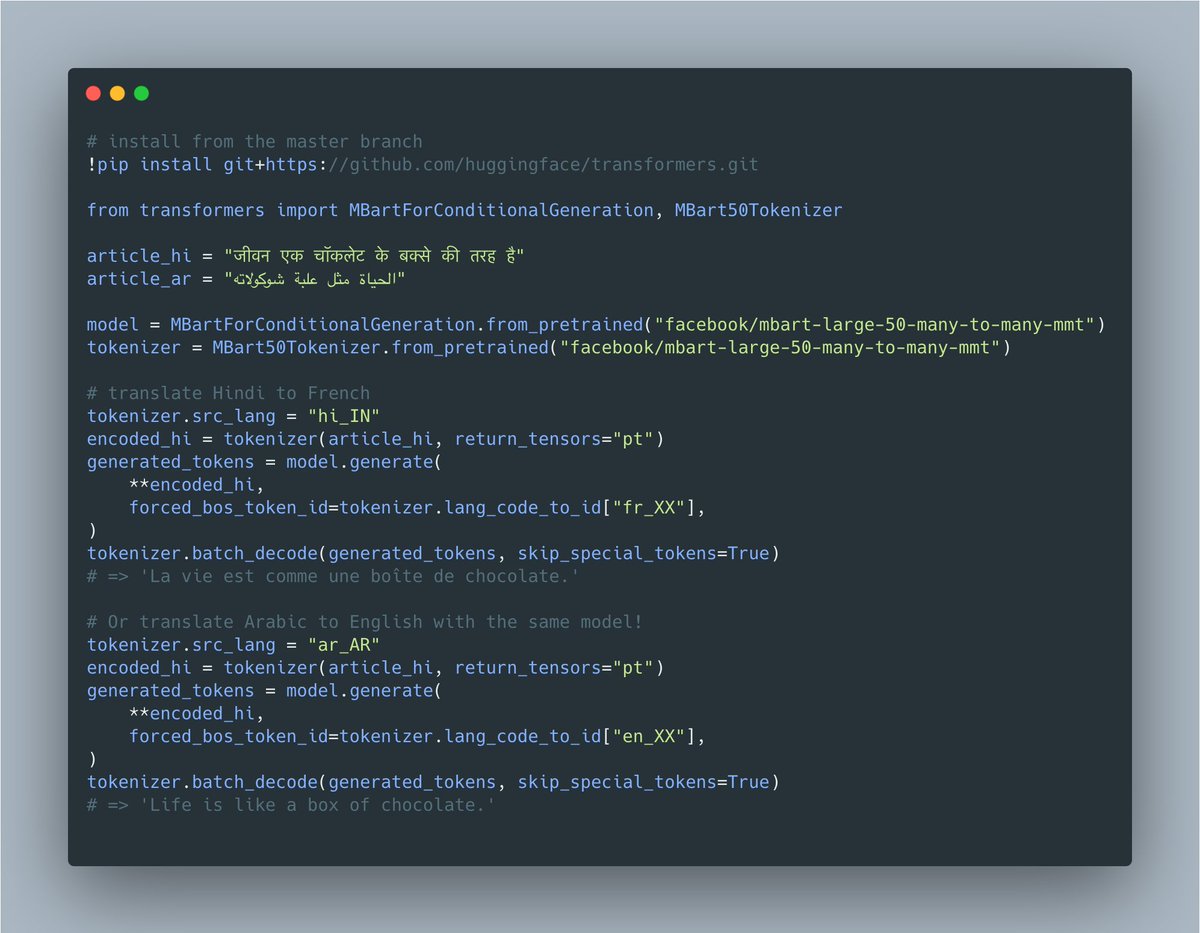
🚨 NEW MODEL ALERT 🚨
Translate text to, or between 50 languages with mBART-50 from @facebookai !
🇺🇳 One-to-Many model: translate from English to 49 other languages
↔️ Many-to-Many model: translation btw any pair of 50 languages
7
74
408
15 Feb 2021
Who is still waiting for the 4th edition of AIMA?
#ArtificialIntelligence #MachineLearning
1
15 Feb 2021
In case you need a no-frills post-processor for facebook AI's amazing Wav2Vec 2.0: huggingface.co/flexudy/t5-sm…
I fine-tuned a T5 model from the Hugging Face Hub using about ~120K paragraphs extracted from popular QA datasets.
#naturallanguageprocessing #huggingface #flexudy
3
Yet another two brilliant minds Sophia and Natasa have joined our #openinnovation team at #flexudy.
Machine Teaching helps us improve our #AI making sure we are on top. Giving us a chance for new applications to cater to your needs
Join us on our rise: flexudy.com/education/pipe/

2
5
28 Dec 2020
1

Beyond CUDA: GPU Accelerated Python for Machine Learning on Cross-Vendor Graphics Cards Made Simple
A practical deep dive into GPU Accelerated Python on cross-vendor (not only NVIDIA) GPUs for building ML algorithms using “Vulkan Kompute” Python Framework
redd.it/ju2em0
2
54
241
13 Nov 2020
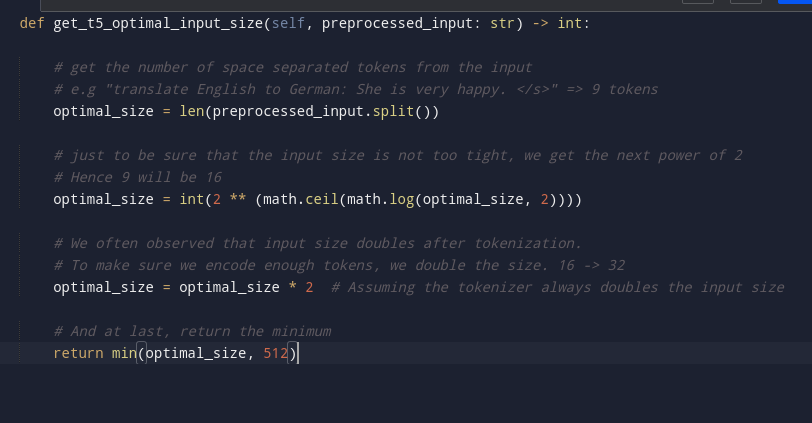
I sometimes see @huggingface's t5 tokenizer used like this: tokenizer.encode(some_long_text, max_length=512 ..)
Di you know the size can double depending on the input 😅? Meaning sometimes, len(some_long_text.split()) ~= 2 x len(input_ids) so 256 tokens might be your max.
2 Nov 2020
At @flexudy we started looking at simple approaches to improve the quality of T5 question-answer generation models on @huggingface using @deepset_ai's Haystack.
The notebook is found here: colab.research.google.com/dr…
Also accessible via @huggingface notebooks on github.
5
8
26 Oct 2020
Made with much love 💚 🙌 by @CollinsKamgaing at the @flexudy Research Pipe. 💯 Open Sourced. Stay tuned at lnkd.in/ebMqEKg or flexudy.com/pipe. Interested in getting early access to a deployed version ?
#naturallanguageprocessing #machinelearning #datalabeling
3
3
20 Oct 2020
How well do you unterstand what you read?🤯 What if your Smartphone could ask you questions like a teacher would? 🧐
🇨🇵🇬🇧🇩🇪
#flexudy #homeschooling #france2 #Education #edtechstartup #smartphone #universitylife
1