
Full Stack Developer, System Engineering & DevOps
Joined March 2022
- Tweets 971
- Following 83
- Followers 96
- Likes 1,366
198 Photos and videos








Pinned Tweet

21 Nov 2024
Ready to build that project MVP on the following:
✅Games
✅Websites
✅ Custom API services
✅Mobile/web applications
Book a deal today by filling out this quick form, and I'll get in touch shortly afterward: ✅🚀
forms.gle/RqBpXXCLZnPF8DBL6

2
3
315
Mar 25
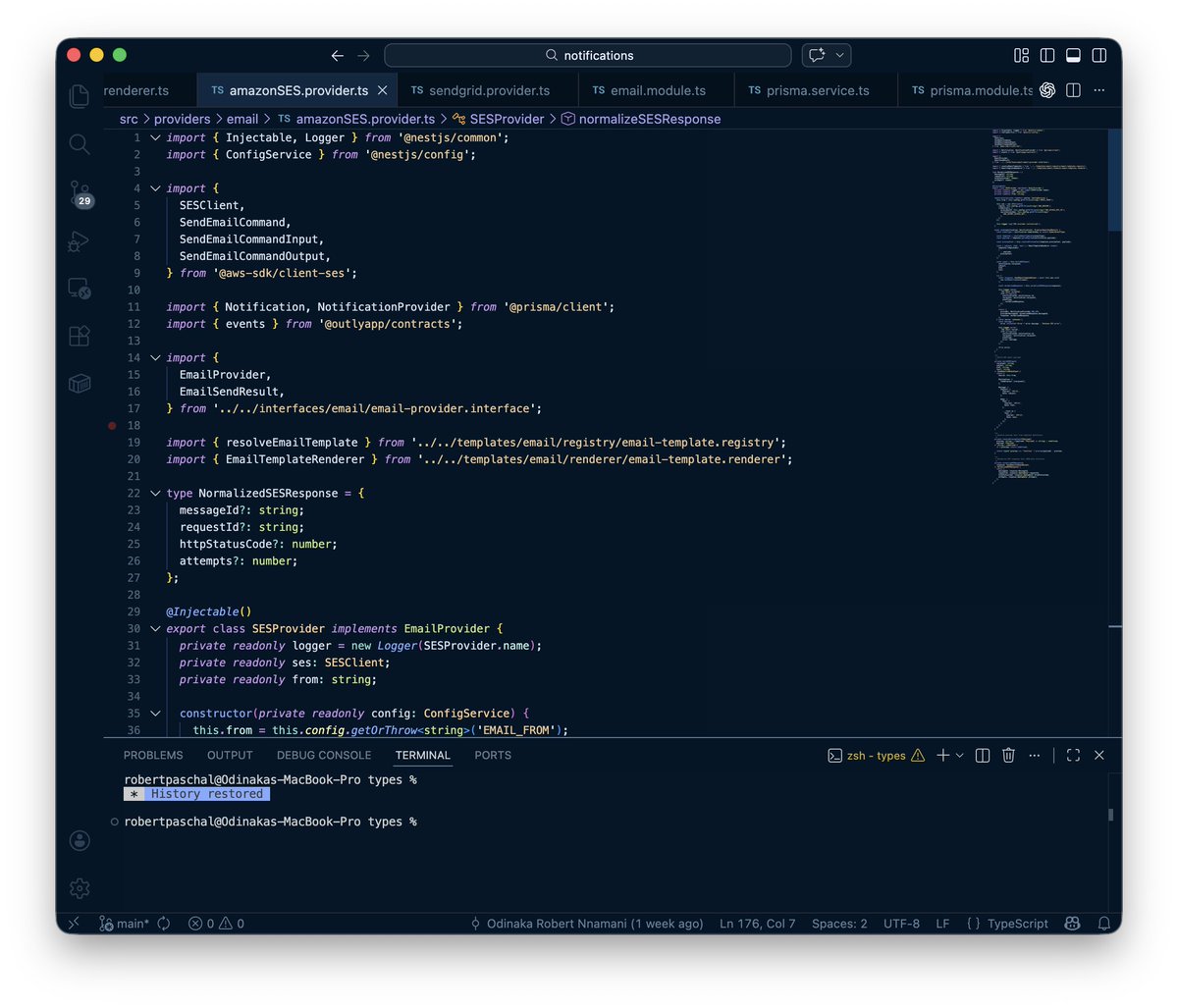
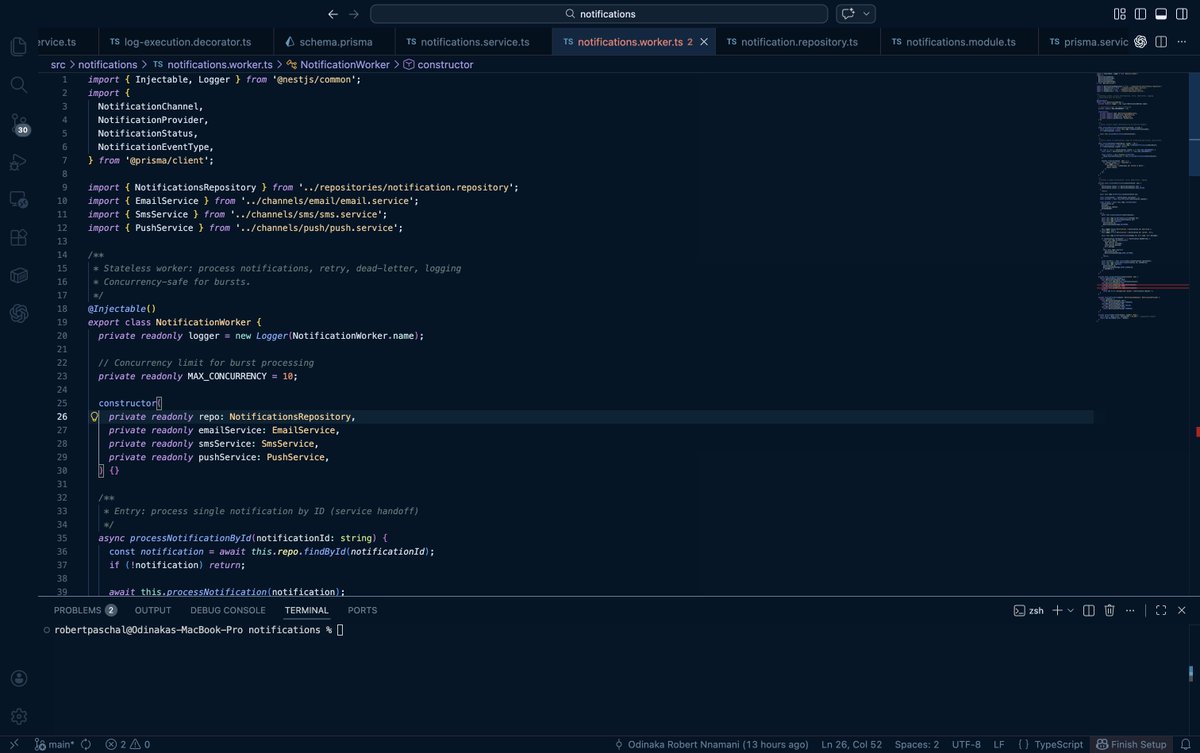
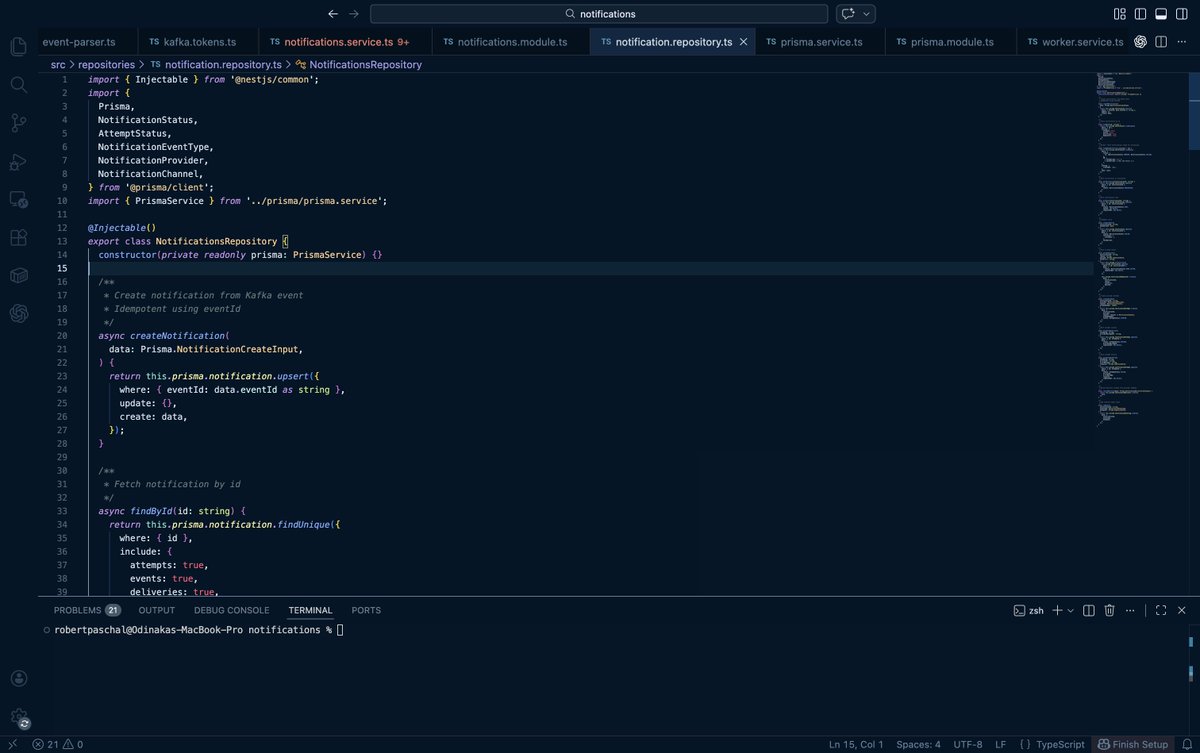
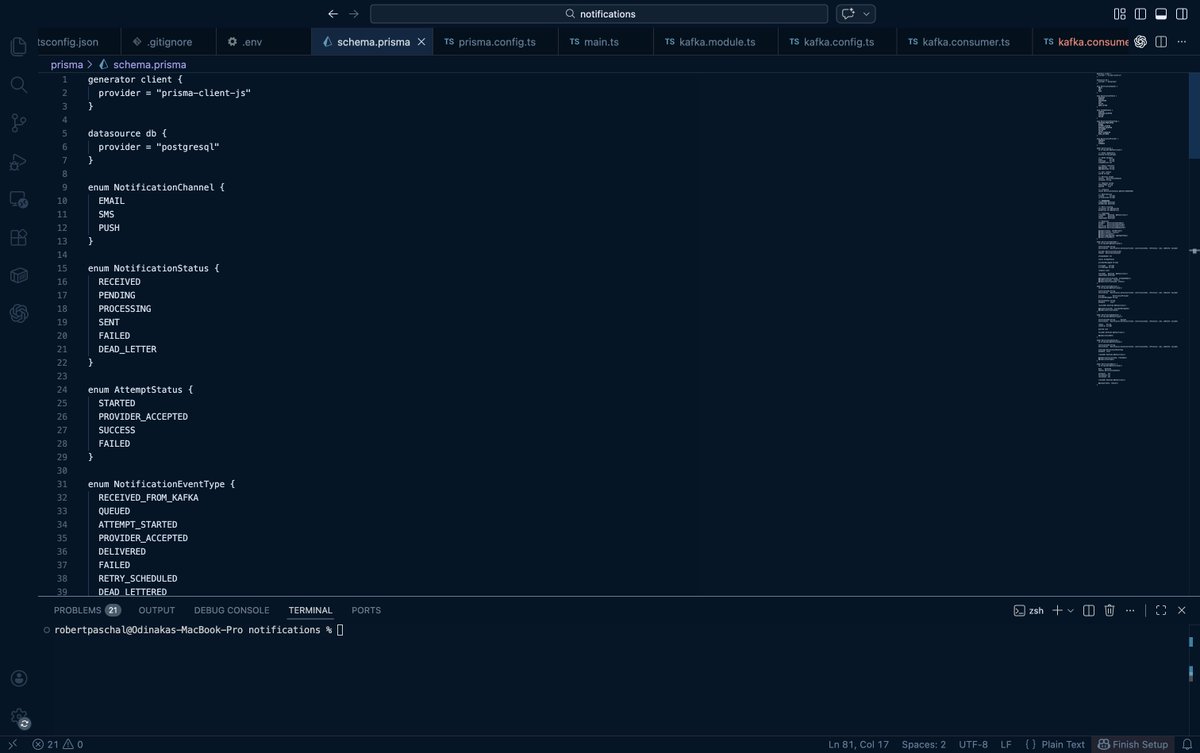
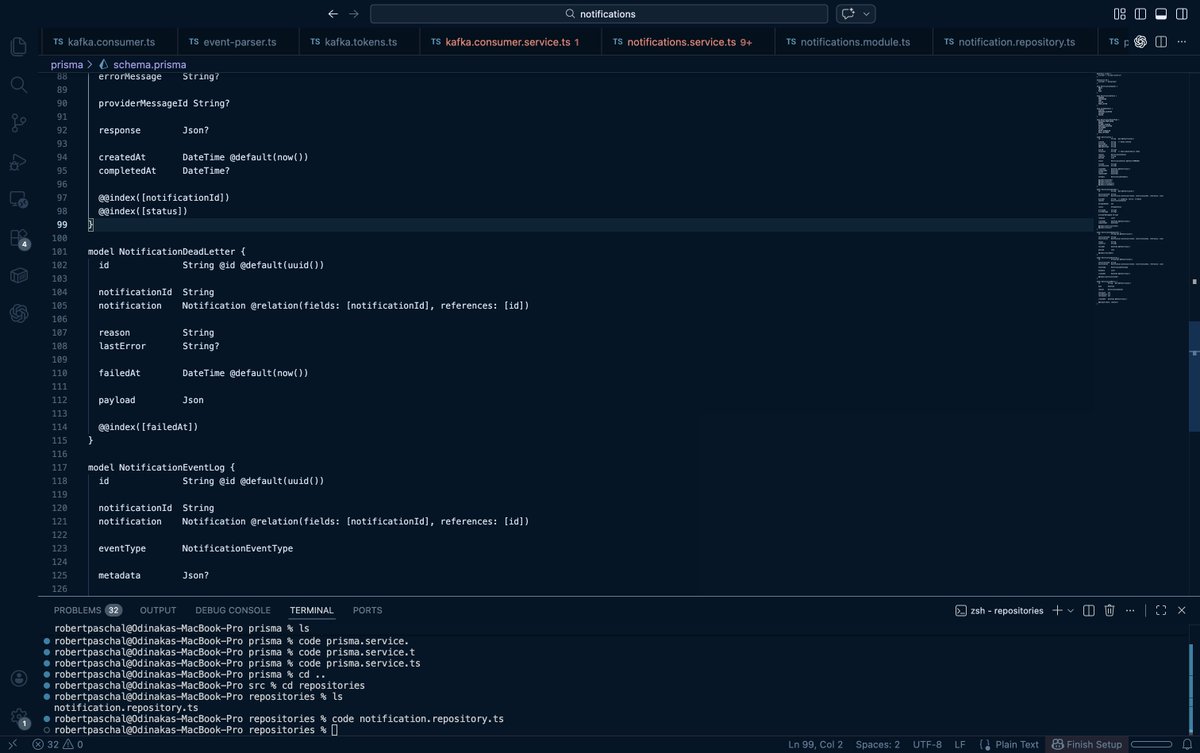
Day 37: Building my first mobile app:
Switched from SendGrid → Amazon SES.
Not just for cost.
For control.
Rebuilt the notification system to be:
• Provider-agnostic
• Template-driven (Handlebars)
• Easily extensible for new email types
• Retryable fully logged
1
1
42
Mar 25
“Good systems evolve easily” — that line hit. Was that learned the hard way?
1
1
3
Mar 25
Always is 😄 Every rigid system eventually forces a rewrite. Trying to design this one so future changes are incremental, not painful.
1
3
Mar 25
Feels like you’re building toward an internal notification platform, not just a feature.
1
1
3
Mar 25
That’s exactly the direction. Treating it as infrastructure early makes everything easier as the system grows.
1
2
Mar 25
Logging notifications is a combo I wish more systems took seriously. What are you tracking?
1
1
3
Mar 25
Delivery attempts, failures, retries, and provider responses. The goal is to make debugging issues fast instead of guesswork.
1
2
Mar 25
Designing for new payloads upfront is such a power move. How are you structuring them?
1
1
3
Mar 25
Keeping payloads schema-driven and mapping them cleanly to templates. That way adding a new email type is mostly configuration, not logic.
1
2
Mar 25
Interesting move from SendGrid to SES. Any trade-offs you had to accept?
1
1
12
Mar 25
Definitely. SES gives more control but less out-of-the-box convenience. Had to build more internally—but that’s also where the flexibility comes from.
1
5
Mar 25
This is the kind of backend work that users never see but always feel when it breaks.
1
1
3
Mar 25
100%. If users notice your notification system, something probably went wrong 😅 The goal is reliability without visibility.
1
12
Mar 25
Retry logic is underrated. How are you handling failures—queue-based or inline retries?
1
1
5
Mar 25
Leaning toward a retryable pipeline with structured logging so failures are observable and recoverable. Long-term, this will sit behind a queue for better resilience.
1
3
Mar 25
Handlebars for templating is an interesting choice. Did you consider anything else?
1
1
3
Mar 25
Yeah—looked at a few options. Handlebars hit the sweet spot between simplicity and flexibility for dynamic content without overcomplicating rendering.
1
2
Mar 25
Provider-agnostic sounds great in theory, but adds complexity. How did you balance abstraction vs over-engineering?
1
1
3
Mar 25
Great question. I kept the abstraction thin—just enough to swap providers without leaking their specifics into business logic. The goal wasn’t perfection, just optionality.
1
6
Mar 25
A lot of people don’t realize how quickly “just send an email” turns into a full system problem. Curious—what was the breaking point that made you switch providers?
1
1
6
Mar 25
Exactly this. It stopped being about sending emails and started becoming about control scalability. Cost was the trigger, but flexibility sealed the decision.
1
7