在所有文化中,对地狱的描述都是重复。
Joined April 2011
- Tweets 33,794
- Following 1,489
- Followers 56,545
- Likes 49,441
2,673 Photos and videos









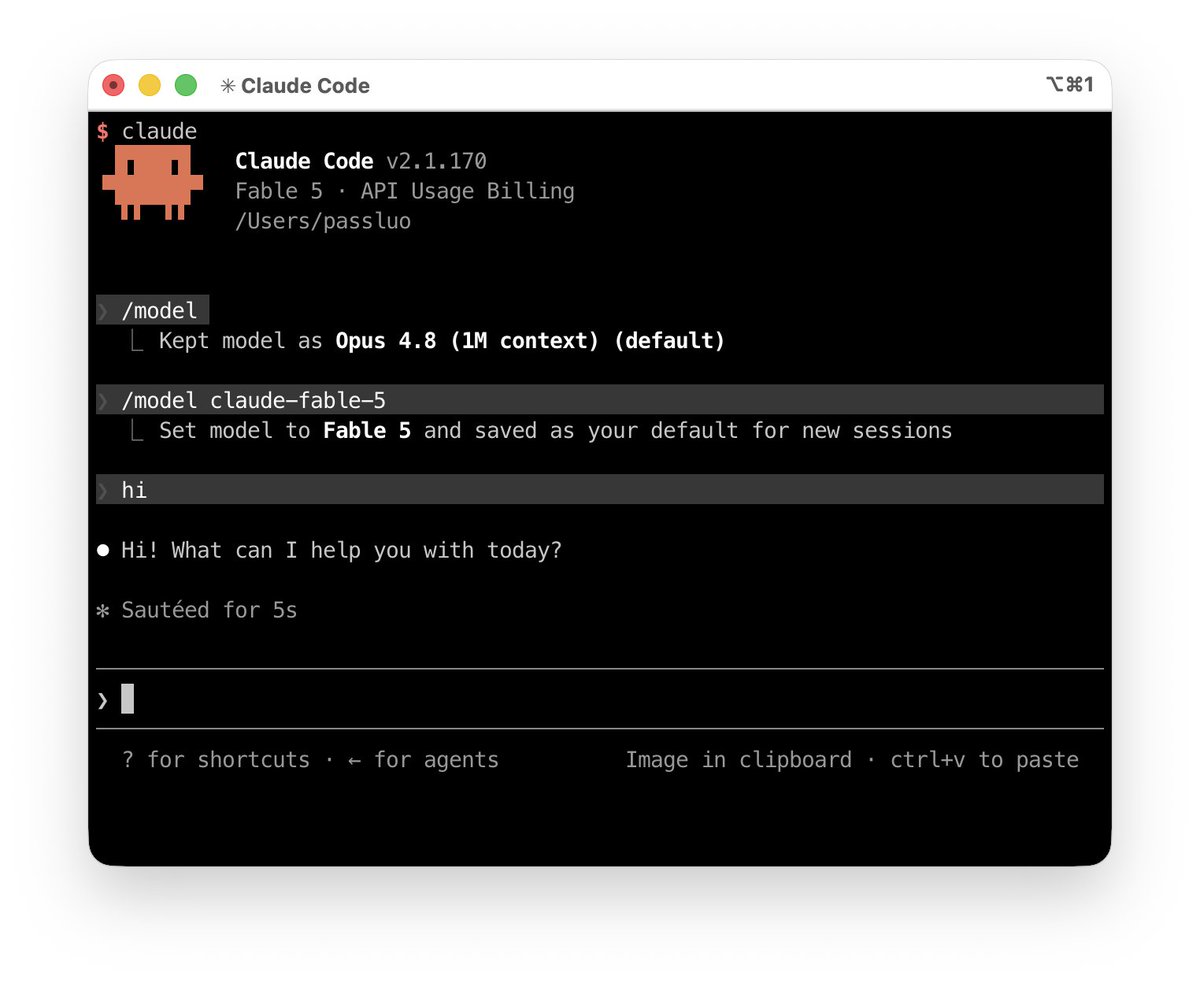



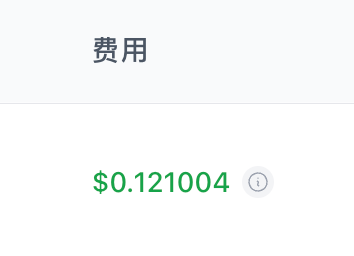
哦豁,fable-5 才爽几天就没得用了😂
Jun 13

As a result of a US government directive, we are suspending access to Claude Fable 5 for all users. You can continue to use all other Claude models.
Here’s what this means for you:
Across Claude products, new sessions will run on your selected default model or Opus 4.8, and existing Fable 5 sessions will end with an error.
On the Claude Platform, requests to Fable 5 will also return an error. Please update your integrations to other Claude models.
We know this is a disruption to your workflows; we appreciate your patience and support.
3
3
3,393
感觉这段有点误导,提供另一个观点:
拿「我个人的工作场景中目前模型够用了」去推断「整个大模型技术已经逼近渐近极限」显然是另一种幸存者偏差,这只能说明 OP 的 AI 协作模式还没有迁移到更高维度的新范式
Singular Abstractions 的工作流已经是 1-2 年前的东西了,这种范式的工作模式和任务复杂度已经被目前主流的模型解决,属于它们的能力重叠区
就像前几天小互的那个段子一样,「以我的智商,根本测不出来 fable-5 强在哪里」,你去问一群大学生 9 的平方根是什么,分不出他们的区别很正常
如果上面说的还是很抽象,那你可以想象回到 2009 年,有人说:「我的诺基亚也能发短信、看网页、看视频,iPhone 斌没有改变我的生活方式,手机技术已经到极限了」
作为 2026 年的人,我们显然知道这个论断是很荒谬的
正是因为新的手机范式到来,手机产业从硬件到软件加速突破,资本成百上千倍的加大投入,才最终催生出了现在完全颠覆过往生活方式的移动互联网生态
「模型够不够用」是一个模型应用层的经济性的问题,模型大厂们迟早需要面对这个话题,但我觉得距离这个时间节点还有很长一段路要走
对模型大厂而言,他们看的绝对不是「能不能帮工程师顺畅地写一个 AWS ALB 脚本」,而是追求的是全面超越人类平均智商水平的 AGI 诞生,否则这场倾尽资本全部的世纪性豪赌毫无意义
截图中作者吐槽对 fable-5 能力的误解和幻觉的吐槽,其实也恰好说明了现有的模型还不够强,而要解决这最后 10% 的高难度幻觉,底层的模型能力可能需要提升几十倍几百倍
现在模型蒸馏的方法论,在逐渐从硬蒸馏到软蒸馏过渡,这个流程里有个很重要的人类角色就是「出题人」
出题人的工作是找到 A 模型能解决,但是 BCDE 模型都不能解决或者解决得不好的那些问题,然后通过记录 A 模型解决问题的过程来创建训练数据
每家模型大厂都在不断出题、不断寻找模型的差异化边界,这是提高 LLM 能力的路劲,而这些问题确实可能是 99% 的人在日常工作中不会遇到的,但这种方法是目前百亿级参数(10B-32B)小模型在特定任务上能够逆袭、甚至暴打千亿级大模型的核心秘诀
顶流大厂追求更大、更快、更强模型的方向是毋庸置疑的
虽然这样做可能与基础用户需求的已经有点脱节,但也并不属于为了 0.1% 的提升在做一些毫无性价比的工作
相反,OP 期望「在明年这个时候 128g 的 MBP 上一个本地模型能提供 Claude 90% 的能力」这个愿望的实现,本身就依赖于顶级模型的能力不断加强再作为教师模型去蒸馏训练他希望的这个本地模型


7
5
33
12,742
𝙋𝙖𝙨𝙨𝙡𝙪𝙤 retweeted

Jun 10
我以为只是 meme,原来你半夜真在搞这玩意。

2
4
67
20,428

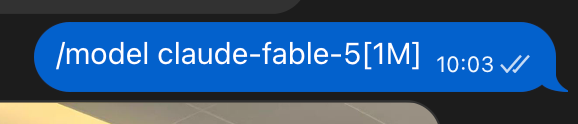
哈哈哈,确实好多人问怎么开
1️⃣ 更新下 claude code cli 到最新版
2️⃣ ⬇️⬇️⬇️
Jun 10

/model claude-fable-5[1m]
不然很多人更新了最新版也看不到哈哈
16
8
5,049
没有 Claude 账号的可以在我们中转站体验下
注册链接 yylx.io
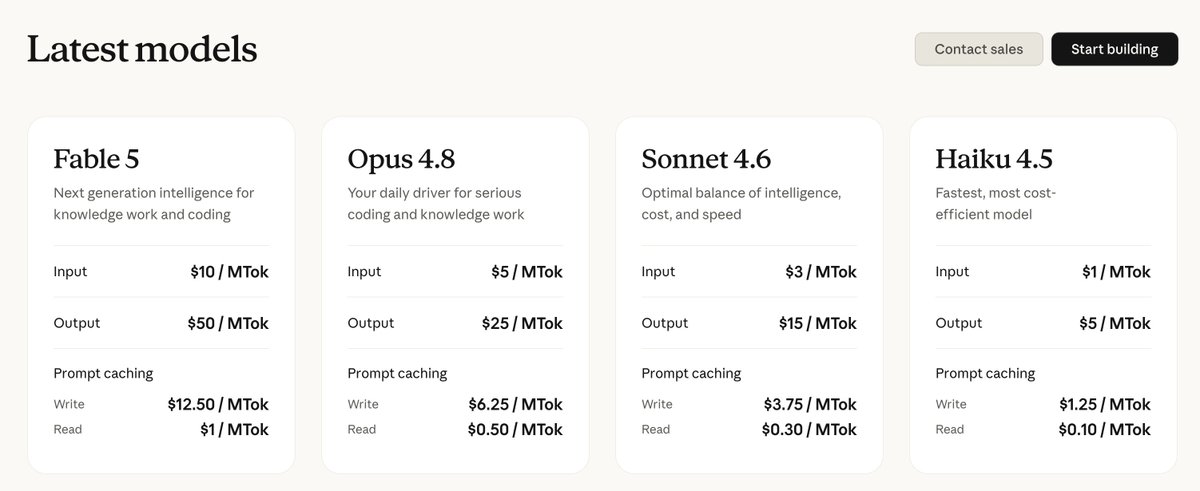
6 月 22 号以后,fable-5 就要从 Claude 官方套餐里面去掉了
到时候只能走 API,走不了反向代理,成本会更贵
当然,也有小概率 A\ 出一个 400 美金的套餐包含它
希望 OpenAI 好好加油啊,治一治这些臭毛病
68
24
9,507