
phd @uwcse, student researcher @microsoft, undergrad @berkeleyai
Joined June 2023
- Tweets 37
- Following 287
- Followers 455
- Likes 174
8 Photos and videos





Pinned Tweet

Mar 26
We’re releasing OmniReset, a framework for training robot policies using large-scale RL and diverse resets for contact-rich, dexterous manipulation.
OmniReset pushes the frontier of robustness and dexterity, without any reward engineering or demonstrations.
Try the policies yourself in our interactive simulator! weirdlabuw.github.io/omnires…
(1/N 🧵)
21
94
465
108,524
Patrick Yin retweeted
Here’s a pretty weird and surprising result - retrieval-augmented generation works unreasonably well for robot learning – but only when parameterized using difference vectors!
We introduce Difference-Aware Retrieval Policies for Imitation Learning (DARP), a simple, semi-parametric RAG architecture for imitation learning that achieves gains of up to 200% over standard behavior cloning. No additional assumptions beyond BC, just a little architecture switch! The theory backing it up is pretty cool too and it works on real robots! :)
Play with our website to understand better: weirdlabuw.github.io/darp-si…
🧵(1/7)
6
27
163
19,922
Patrick Yin retweeted

May 19
Real-world RL is still too brittle and data-hungry for long-horizon, contact-rich tasks.
We introduce Simulation Distillation (SimDist), which turns large-scale simulated experience into reusable world-model priors for rapid real-world adaptation.
By combining online planning with dynamics adaptation, SimDist achieves high success rates on tasks requiring precision, force, and reactivity.
Play with our interactive visualization to see for yourself: sim-dist.github.io
(1/n)
3
44
205
26,257
Patrick Yin retweeted

Mar 26
Excited to share the project that has surprised me the most in the last year!
Large-scale RL in simulation, no demos and no reward engineering can solve dynamic, dexterous and contact rich tasks. The learned behaviors are reactive, forceful and use the environment for recovery in ways that are extremely challenging to bake in or teleoperate!
You can play with the policies yourself to see: weirdlabuw.github.io/omnires…
And, the learned behavior transfers to real world robots from RGB camera inputs!
So what’s the trick - using simulator resets carefully! Let’s unpack (1/10)
17
90
615
82,344
Mar 26
We’re releasing OmniReset, a framework for training robot policies using large-scale RL and diverse resets for contact-rich, dexterous manipulation.
OmniReset pushes the frontier of robustness and dexterity, without any reward engineering or demonstrations.
Try the policies yourself in our interactive simulator! weirdlabuw.github.io/omnires…
(1/N 🧵)
21
94
465
108,524
Mar 26
We’re building UWLab, a shared ecosystem for training robot policies in simulation and transferring them to the real world, built on Isaac Lab.
This includes the full OmniReset codebase, along with tasks, algorithms, and deployment in one clean, modular stack: github.com/UW-Lab/UWLab
1
5
36
2,493
Mar 26
Website: weirdlabuw.github.io/omnires…
Paper: arxiv.org/abs/2603.15789
Code: github.com/UW-Lab/UWLab
We’ll present at #ICLR2026 this April! Joint work with @TylerW24089, @octi_zhang, @jtran_uw, Ignacio Dagnino, Eeshani Shilamkar, @numfortiapo, Simran Bagaria, Xinlei Liu, Galen Mullins, @Andrey__Kolobov, @abhishekunique7
2
23
1,954
Patrick Yin retweeted

18 Dec 2025
Excited to introduce PolaRiS, a real-to-sim recipe for turning short real-world videos into high fidelity simulation environments for scalable and reliable zeroshot generalist policy evaluation.
polaris-evals.github.io
(1/N 🧵)
8
48
234
65,925
Patrick Yin retweeted

10 Oct 2025
How can we help *any* image-input policy generalize better to visual and semantic variations?
👉 Meet PEEK 🤖 — a framework that uses VLMs to decide *where* to look and *what* to do, so downstream policies — from ACT, 3D-DA, or even π₀ — generalize more effectively!
3
16
42
10,819
Patrick Yin retweeted

10 Apr 2025
Scaling imitation learning has been bottlenecked by the need for high-quality robot data, which are expensive to collect. But are we utilizing existing data to the fullest extent? A thread (1/11)
14
41
252
51,464
13 Feb 2025
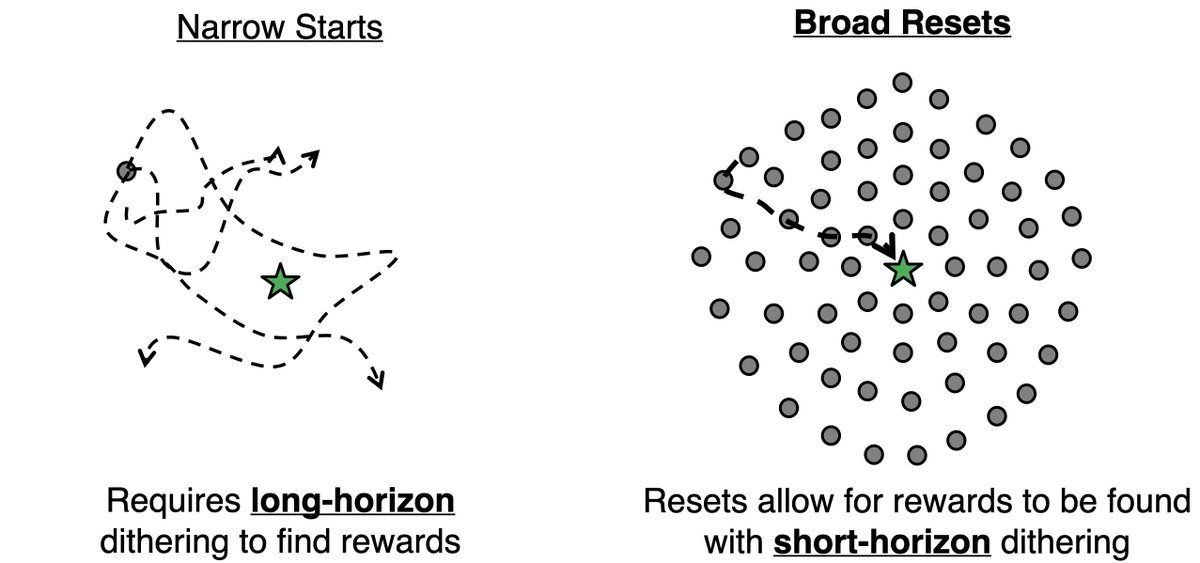
Current RL finetuning methods are too inefficient to make autonomous real world robot learning tractable. We propose Simulation-Guided Fine-Tuning (SGFT) - a simple, general sim2real framework that extracts structured exploration priors from sim to accelerate real world RL. 🧵1/6
1
24
117
9,199
13 Feb 2025
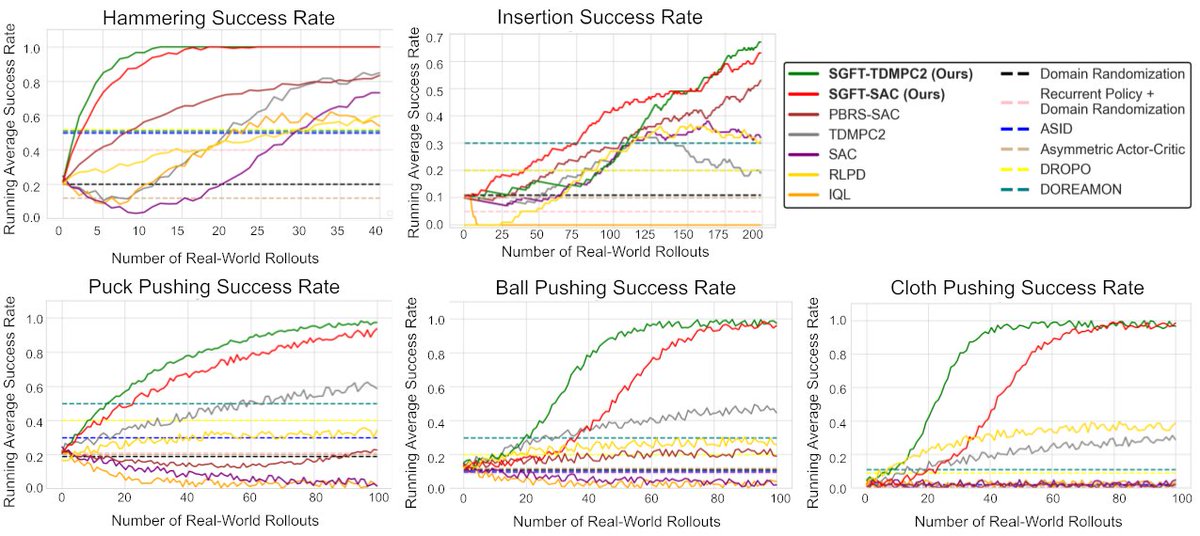
Here is a comparison of time to learn each task with our method vs existing baselines using sim2real transfer, RL finetuning, and/or model-based RL. In each case, our method outperforms baselines in sample efficiency by at least 2x! 🧵5/6
1
5
383
13 Feb 2025
We will be presenting this paper at #ICLR2025 this April!
Website: weirdlabuw.github.io/sgft/
Paper: arxiv.org/abs/2502.02705
Fun collaboration with Tyler Westenbroek, Simran Bagaria, Kevin Huang, @chinganc_rl, @Andrey__Kolobov , @abhishekunique7 🧵6/6
8
349
Patrick Yin retweeted
13 Feb 2025
So we did a bunch of projects with real world reinforcement learning - but it was often too inefficient to be practical to train tabula rasa. This suggests we need better priors, but acquiring these from on-robot data can often be expensive as well.
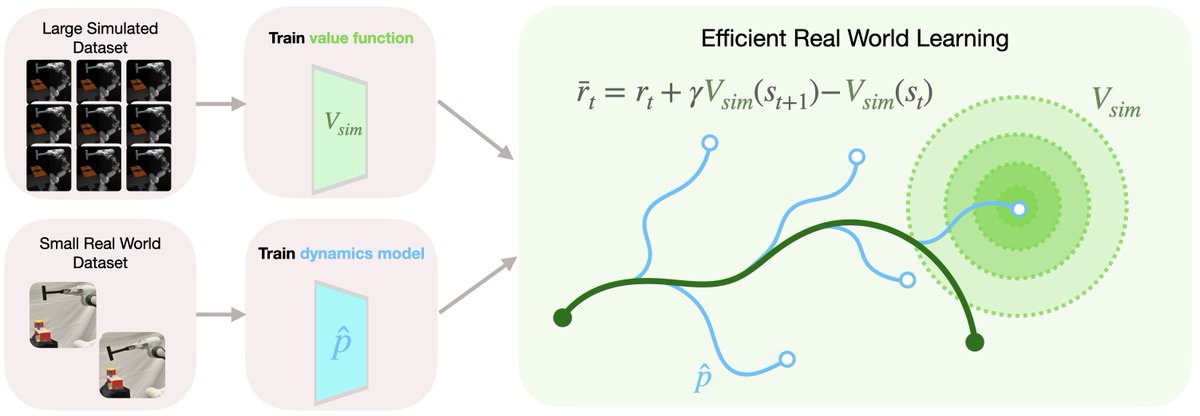
In our recent work, we show that despite being fundamentally inaccurate, simulation can guide provide a cheap way to guide real-world RL finetuning to be super efficient! We propose Simulation-Guided Fine-Tuning (SGFT) - a simple paradigm for sim2real finetuning that uses simulation to provide reward shaping that accelerates real world RL finetuning *beyond* just providing an initialization. TLDR: Use value functions from sim to shape rewards for real-world RL, see large sample efficiency improvements 🧵(1/6)
3
27
189
13,627
Patrick Yin retweeted
20 Dec 2024
In my experience, robot 'generalists' are often jacks of all trades but masters of none. In training across multiple tasks and environments, robot policies fail to generalize robustly and effectively to each particular test setting. What if at test time, we non-parametrically *retrieved* “relevant” data from the training set and used it to significantly improve the performance of few-shot imitation learning to be robust to various test time scenes. Notably, we are *not* collecting lots of new data, just training more on sub-components of the same training data! Now, we’re certainly not the first to suggest retrieval, but in our new work - STRAP, we show how retrieving relevant *sub-trajectories* from offline datasets can significantly increase data reuse across tasks, when paired with an appropriate metric space. A 🧵 (1/7)
2
21
115
12,060
Patrick Yin retweeted
20 Dec 2024
Have some offline data lying around? Use it to robustify few-shot imitation learning! 🤖
STRAP 🎒 is a retrieval-based method that leverages semantic sub-trajectories in offline datasets to augment the training data.
🧵 1/6
3
25
70
12,429