
Pinecone is the knowledge infrastructure for AI at scale.
Joined July 2020
- Tweets 2,509
- Following 146
- Followers 27,593
- Likes 2,961
533 Photos and videos


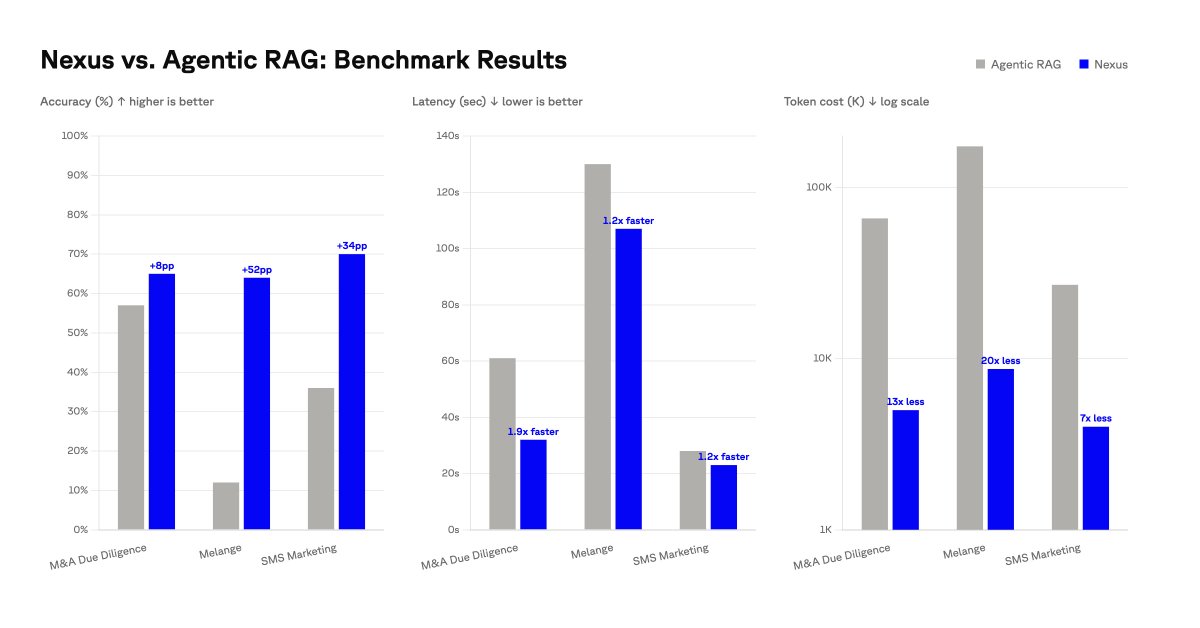













Introducing Pinecone Nexus. A knowledge engine for agents.
The bottleneck for production agents isn't the model. It's the per-query work of searching, stitching, parsing tables, normalizing labels. Nexus compiles that work ahead of time into typed, governed artifacts. Agents query through KnowQL.
90% fewer tokens. >90% task completion. 30x faster.
Early access open.
pinecone.io/blog/introducing…

4
5
35
16,059
Pinecone retweeted

Jun 12
🎙️New Breaktime Tech Talks! Talked with @RoieSchwabco from @pinecone about why your AI agents are burning excess tokens, and what to do about it. Also: naive RAG, "Franken answers," and building low-code AI apps.
🎧 pod.fo/e/42f0c4
#btt #RAG #Pinecone
3
6
408
Pinecone @PulumiCorp: an evening of talks on how AI systems get built and run under the hood.
The infra behind vector search and RAG, IaC done right, and an AI running coach that lives in Slack and merges messy real-world data into context the model can use.
Demos, Q&A, hangout after.
Thu June 18, 5 PM, NYC: luma.com/pinecone-m9my
1
1
5
397
Proud to have Pinecone Nexus be a part of this along with our friends at @LangChain, @tavilyai, and @guardrails_ai!

Most #AIAgents don't fail because of the model. They fail because of the infrastructure around it.
Introducing the Nebius Agents Blueprint: an open architecture for building, operating, and continuously improving agents in production.
nebius.com/blog/posts/introd…
1
2
7
662
Most AI agents reset every session. @JenovaAIAgent's don't.
Longest session on their platform: 16M tokens. All of it retrievable in <10ms via Pinecone vector retrieval.
Result: Fast ramp to $1M ARR, 200K users, 10x revenue in 5 months. Nearly all organic.
"For an agent platform, the quality of the knowledge layer determines whether users stay or leave. Pinecone is what lets us store everything a user has ever worked on and retrieve exactly the right piece of it in milliseconds. That's the foundation our entire product is built on." — @boriswang01, Founder
Knowledge is the moat. Case study: pinecone.io/customers/jenova…



1
7
10
655
Managed SaaS needs vendor access security review won't approve. Self-hosted hands your team a vector database to run.
Pinecone BYOC runs the data plane inside your own AWS, GCP, or Azure account. Zero vendor access. Vectors stay in your VPC.
60-min session, June 17, 9 AM PT: luma.com/j61zhbux
2
2
307
Pinecone retweeted

And @DevangSachdev announced the @nebiusai Agents Blueprint and consists of
- @LangChain Deep Agents
- @tavilyai
- @pinecone
- @guardrails_ai Snowglobe
- Langchain Langsmith
#NebiusInflection26

1
5
19
4,435
Your AI chatbot is only as good as the data behind it.
This n8n template from our friends at @apify shows you how to wire up a RAG pipeline using Apify Pinecone Gemini so your chatbot can answer questions grounded in your actual website content, not just what the model knows.
How it works:
→ Apify's Website Content Crawler scrapes your site on a schedule
→ Content gets chunked and indexed into Pinecone as vector embeddings
→ Gemini retrieves the right context and generates accurate answers
The result: a support chatbot that stays current automatically, with no manual data wrangling.
🔗 @n8n_io template: n8n.io/workflows/14157-build…
And if you want to go deeper on the data layer, Apify's blog post covers the full approach (linked in the replies).
4
4
11
990
Four weeks, three enterprise customers, same pattern across all three.
Most inference spend goes to retrieval loops. A generic index carries no knowledge of domain, query types, or task structure, so the loop runs before the model can reason. Nexus compiles before the query.
Full results: pinecone.io/blog/nexus-ea-be…
2
2
5
403
Bulk import is now free up to 1 TB.
Reads directly from S3, GCS, or Azure Blob into the index builder. Standard and Enterprise get a $250 credit applied automatically.
After 1 TB: $0.25/GB, down 75%.
pinecone.io/blog/bulk-import…
1
6
362
Pinecone retweeted

Jun 3
Today at Microsoft Build: Pinecone Nexus now integrates with Microsoft OneLake.
Your enterprise data, turned into task-scoped, governed, cited knowledge your agents can use directly. 95% token reduction. 30x faster execution. Completion rates above 90%.
pinecone.io/newsroom/microso…
1
3
410
We just announced the integration of our knowledge engine, Pinecone Nexus, with @Microsoft OneLake at #MSBuild.
Want to build a reliable, production-grade knowledge layer directly over your structured data in OneLake or Fabric?
Staff Data Engineer Simon Lu shows you how it's done in this quick demo. Watch here and read the full announcement: pinecone.io/newsroom/microso…
1
1
8
522
95% token reduction. 30x faster execution. 90% task completion.
Today at #MSBuild, we announced a major shift to move reasoning upstream: Pinecone Nexus now integrates directly with @Microsoft OneLake.
Traditional AI agents waste tokens stitching raw data together at runtime. At scale, completion rates plummet 60% because we are forcing reasoning engines to do the heavy lifting of data infrastructure.
Pinecone Nexus x Microsoft OneLake fixes the infrastructure wall, moving reasoning upstream.
❌ Naive approach: Agent queries raw data ➔ Stitches chunks ➔ Dumps massive context window into frontier LLM ➔ High latency exploding token costs.
✅ Nexus approach: Nexus integrates with OneLake ➔ Pre-assembles task-specific artifacts ➔ Agent queries structured data via KnowQL ➔ Instant, cited responses.
The data your agents need already lives in OneLake. Stop rebuilding data pipelines. Enforce RBAC/ABAC instantly, and track tokenomics via a unified dashboard.
📣 Announcement: pinecone.io/newsroom/microso…
3
4
12
1,063
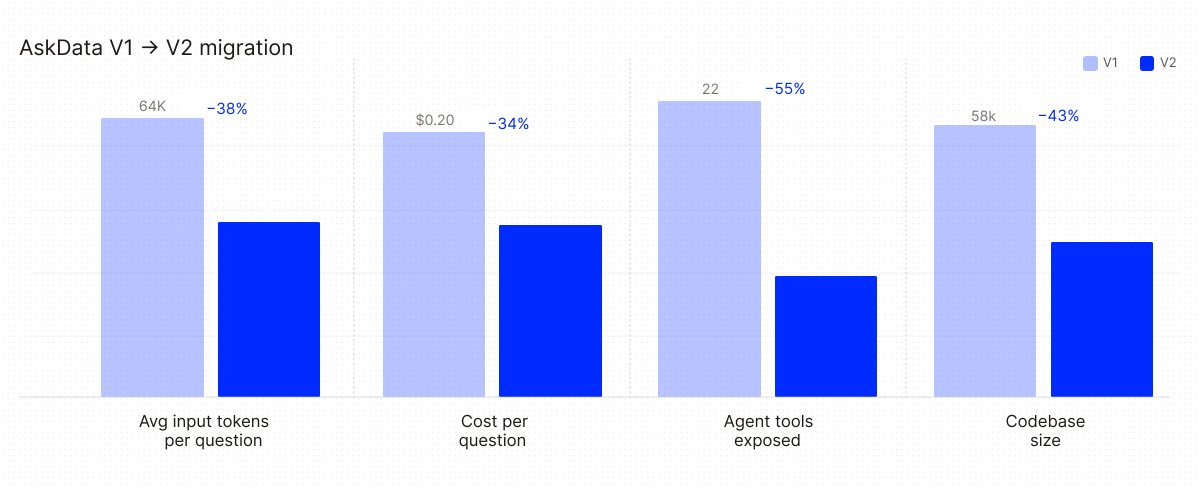
Data agents don't fail at writing SQL. They fail at knowing your business.
Schemas show you the columns, but they don't tell you which view is canonical for ARR, how often each metric updates, or which month you changed the pricing. That sits in dbt code, Slack threads, analyst memory, and old Notion pages.
Staff Data Engineer, Simon Lu built AskData, our internal data agent, on Pinecone Nexus earlier this year. Since then it's answered 3,690 questions and lets the team actually explore data instead of wrestling with dashboards. Token consumption dropped 92% compared to pointing Claude/Cursor directly at internal sources — and 38% vs. our previous custom implementation.
Full write-up a side-by-side demo you can run yourself: pinecone.io/blog/inside-askd…
2
11
593
Connecting agents directly to Snowflake, Slack, or BigQuery via MCP/CLIs is a multi-token disaster.
They default to brute-force exploration, firing 20-30 tool calls just to rediscover context on every single task.
❌ Naive Approach: LLM acts as its own data crawler. Result: Crazy token burn, compounding latency, and brittle execution.
✅ Pinecone Nexus Approach: Shift the work upfront. De-couple the Reasoning Engine from a dedicated Knowledge Engine.
We built Nexus to transform raw enterprise data into task-optimized artifacts before the agent fires a tool call. The engineering impact? Up to 90% fewer tokens and 30x faster time-to-completion.
Our VP of Product Jeff Zhu breaks down the agentic anti-pattern with @ashimmy on @TechstrongTV: youtube.com/watch?v=p4AX3qsn…
Deploy production-grade knowledge infrastructure for agents: pinecone.io/product/nexus/
3
1
5
451
ICYMI Dedicated Read Nodes are now generally available.
Predictable performance at scale. Up to 97% lower costs on real production workloads.
Fixed hourly pricing. No read rate limits. Always-hot data on dedicated, provisioned resources.
Real production results:
→ 1B vector semantic search: 77% cost reduction
→ 6.1M vector low-latency search: 83% cost reduction
→ 14M vector high-QPS search: 97% cost reduction
3
3
593
Learn more 🔗 pinecone.io/blog/dedicated-r…
1
450
You can’t build an autonomous agent on a static RAG pipeline. Because goals mutate dynamically, agents require an advanced knowledge infrastructure, rather than forcing the model to hunt through a raw text dump mid-task.
Pinecone Nexus bridges this exact gap by moving reasoning upstream, pre-compiling structured knowledge artifacts for agents.
Check out our Head of Developer Relations @RoieSchwabco on @TheEntAIShow with @bgracely:
📺 youtube.com/watch?v=-kZZEMR3…
📖 Learn about Pinecone Nexus here: pinecone.io/product/nexus/.
3
1
458
Ralph Loops are powerful, but wrapping a naive loop in a shell script is a total token burner in production.
Pinecone Principal Engineer Jen Hamon breaks down why standard loops collapse:
❌ The Bug: Premature convergence. The agent acts as its own reviewer, falsely tricks itself into thinking a complex task is done, and exits early with a broken payload.
❌ The Cost: Without structured grounding and clear limits, long-running reasoning loops stall out and torch enterprise token quotas.
✅ The Fix: Move past basic prompt chaining. Implement a programmatic "journaling of progress" to track state across loop iterations, and structurally isolate planning from execution.
Reasoning is only half the battle. If your agentic pipelines lack a dedicated knowledge layer (context, limits, evals), they will consistently converge on incorrect conclusions.
📺 Watch Jen's conversation with @mastra CPO @smthomas3 and CTO @abhiaiyer on the Agents Hour podcast: youtube.com/watch?v=s0L2qFyH…
🧠 Fix the knowledge gap with Pinecone Nexus: pinecone.io/blog/introducing…
2
1
6
919
We're hosting an agentic AI meetup in LA on May 28th — 5–7pm at Gulp in Playa Vista.
Builders, founders, engineers. Drinks, no fluff. RAG systems, agentic workflows, or just starting out — all welcome.
RSVP: luma.com/tvwl28gz
2
2
3
480