
Founder & CEO @ Instill AI | an entrepreneur programmer computer vision and machine learning enthusiast
Joined April 2010
- Tweets 601
- Following 116
- Followers 182
- Likes 518
Photos and videos

Apr 23
Sandbox in 60ms is now reality!
Apr 21

🥳We just open-sourced Cube Sandbox! An instant, concurrent, secure and lightweight sandbox runtime for AI Agents.
Built with RustVMM and KVM, it achieves the perfect balance of security and performance:
→ Sub-60ms cold start (2.5-50x faster)
→ Under 5MB memory overhead per instance (6x less memory)
→ Dedicated kernel per sandbox (hardware-level isolation)
→ Thousands of concurrent sandboxes per node
→ 100% E2B SDK compatible. Swap the endpoint, zero code changes
Full-stack capability, one-click deployment. 3 steps to spin up your own private AI sandbox 👇 🔗
github.com/TencentCloud/Cube…
44
Apr 20
An employee’s Google Workspace account got compromised through Context.ai OAuth, accessing to the Vercel environments.
How come can this happen if the OAuth scopes are constrained?
Apr 19

Here's my update to the broader community about the ongoing incident investigation. I want to give you the rundown of the situation directly.
A Vercel employee got compromised via the breach of an AI platform customer called Context.ai that he was using. The details are being fully investigated.
Through a series of maneuvers that escalated from our colleague’s compromised Vercel Google Workspace account, the attacker got further access to Vercel environments.
Vercel stores all customer environment variables fully encrypted at rest. We have numerous defense-in-depth mechanisms to protect core systems and customer data. We do have a capability however to designate environment variables as “non-sensitive”. Unfortunately, the attacker got further access through their enumeration.
We believe the attacking group to be highly sophisticated and, I strongly suspect, significantly accelerated by AI. They moved with surprising velocity and in-depth understanding of Vercel.
At the moment, we believe the number of customers with security impact to be quite limited. We’ve reached out with utmost priority to the ones we have concerns about. All of our focus right now is on investigation, communication to customers, enhancement of security measures, and sanitization of our environments. We’ve deployed extensive protection measures and monitoring. We’ve analyzed our supply chain, ensuring Next.js, Turbopack, and our many open source projects remain safe for our community.
The recommendation for all Vercel customers is to follow the Security Bulletin closely (vercel.com/kb/bulletin/verce…). My advice to everyone is to follow the best practices of security response: secret rotation, monitoring access to your Vercel environments and linked services, and ensuring the proper use of the sensitive env variables feature.
In response to this, and to aid in the improvement of all of our customers’ security postures, we’ve already rolled out new capabilities in the dashboard, including an overview page of environment variables, and a better user interface for sensitive env var creation and management. As always, I’m totally open to your feedback.
We’re working with elite cybersecurity firms, industry peers, and law enforcement. We’ve reached out to Context to assist in understanding the full scale of the incident, in an effort to protect other organizations and the broader internet. I also want to thank the Google Mandiant team for their active engagement and assistance.
It’s my mission to turn this attack into the most formidable security response imaginable. It’s always been a top priority for me. Vercel employs some of the most dedicated security researchers and security-minded engineers in the world. I commit to keeping you updated and rolling out extensive improvements and defenses so you, our customers and community, can have the peace of mind that Vercel always has your back.
61
Apr 16
In case you’re not aware of how stagnant the UK market is...

Taiwan overtook the UK in stock market value — making it the world's seventh largest — as tech firms regained favor. Read more: bloom.bg/4tklyc8
📷️: An Rong Xu/Bloomberg

50
Apr 12
Do you know that your knowledge base provenance can go beyond just Markdown files (especially if you’ve followed the recent hype around hand-crafted KBs based on Claude Code)?
Fine-grained citations that point to the authentic source file—and even to the exact location where a piece of information originates—provide much higher trust and efficiency when consuming massive amounts of unstructured data.
Try it yourself 👉 instill-ai.com/i/x-prelaunch…
Apr 11

Most people stop at summaries.
I think that’s where real understanding begins.
In my last post, I talked about saving content instead of just consuming it.
But the real next step is:
How do you go back and use it?
I almost always return to the original source.
60
Apr 6
I’m calling it. Any post claiming or discussing AGI must first define what AGI means to the poster.
I’ve f*cking seen 10 different versions of it.
Apr 5

I'm calling it. AGI is already here – it's just not evenly distributed yet.
1
46
Apr 5
Instill AI chrome extension = the knowledge base of your Internet.
After seeing Andrej Karpathy’s idea of personal knowledge base (llm-wiki), I’ve had a stronger realization:
In the end, we’re all converging to the same place.
Before, when I came across something interesting — whether it was a document, image, or video (especially long, information-dense videos) — I would usually just watch it and move on.
Mostly because there wasn’t a good, frictionless way to organize it into a knowledge base.
But now it’s becoming a very natural action:
👉 See → save it for later
And that’s just the first step.
After that, a few things tend to happen naturally:
1. Q&A and reprocessing the content
2. Going back to the original source to understand it more deeply
3. Sometimes turning it into something shareable
But the real shift isn’t these actions themselves.
It’s this: the information doesn’t disappear anymore — it stays, and starts to compound.
The future difference won’t be who writes better prompts.
It will be: who builds a knowledge base that keeps growing over time.
In my next post, I’ll share how I go back to the source, do Q&A, and turn it into output.
47
Apr 5
This is a weekend insight-sharing post.
1. Software engineering is moving from CI (continuous integration) and CD (continuous deployment) to CC (continuous contextualization).
Andrej Karpathy’s idea of a personal knowledge base is essentially a form of CC in practice.
2. ETL (Extract → Transform → Load) will transition to ECL (Extract → Contextualize → Load).
The “T” in ETL has historically been a billion-dollar business, as data cleaning and transformation require complex pipelines and workflows. While ETL workflows will remain—since foundational agent infrastructure still depends on them—ECL will rise rapidly, because context (tokens) is becoming what truly matters.
30
Apr 3
Instill AI has exactly the idea concretized and shipped for you. You likely wanna preserve the original unstructured data type and format to review the genuine sources with solid backlinks. Moreover, it’s not just a personal knowledge base in the end. It’s your high-quality context to generate more useful context for you and your agents.
x.com/pinglin02/status/20344…
Apr 2

LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
2
2
76
Apr 1
I'm curious how people using Claude Code git-worktree to run a dozen agents in parallel actually iterate on UI development.
For backend development, I can have five or six coding agents running simultaneously and it's highly efficient. But for frontend, I haven't found a solid loop-closure framework yet.
Case in point: here is an Instill Agent working on our Chat UI. After three iterations, I still had to personally roast it (roughly translated): "This is ugly," "What even is this?" and "Can you actually do something competent?"
I've tried using skill.md or agent.md, but the results are limited—likely because the codebase is too large. I'm still keen to learn any definitive closed-loop methods for frontend stuff.


1
1
66
Mar 31
AI shouldn't just help you work more—it should help you work chill. 🧊
With Instill AI, we’re ditching the busywork:
🎥 Multilingual video transcription & 1-click subs
🎨 Instant slides, images, & web pages
📂 Auto-organized Collections
🔍 Semantic search (just type @)
My top pick: Internalize 3-hour podcasts or videos into instant timeline segments. Jump straight to the gold, skip the fluff, and cite with a single click. 🖱️✨
Stop searching, start creating.
Grab your invite in the replies! 👇
#InstillAI #Productivity #AI #WorkSmarter
1
1
47
Mar 26
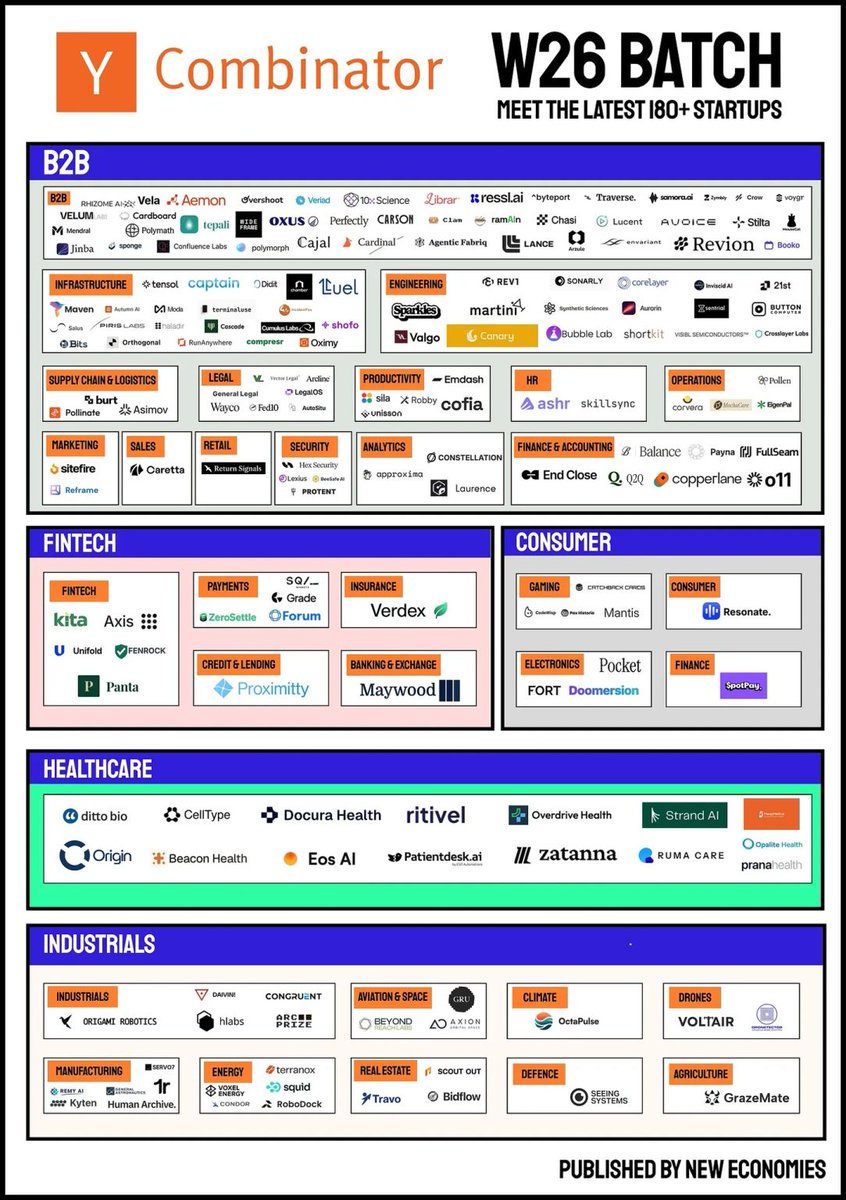
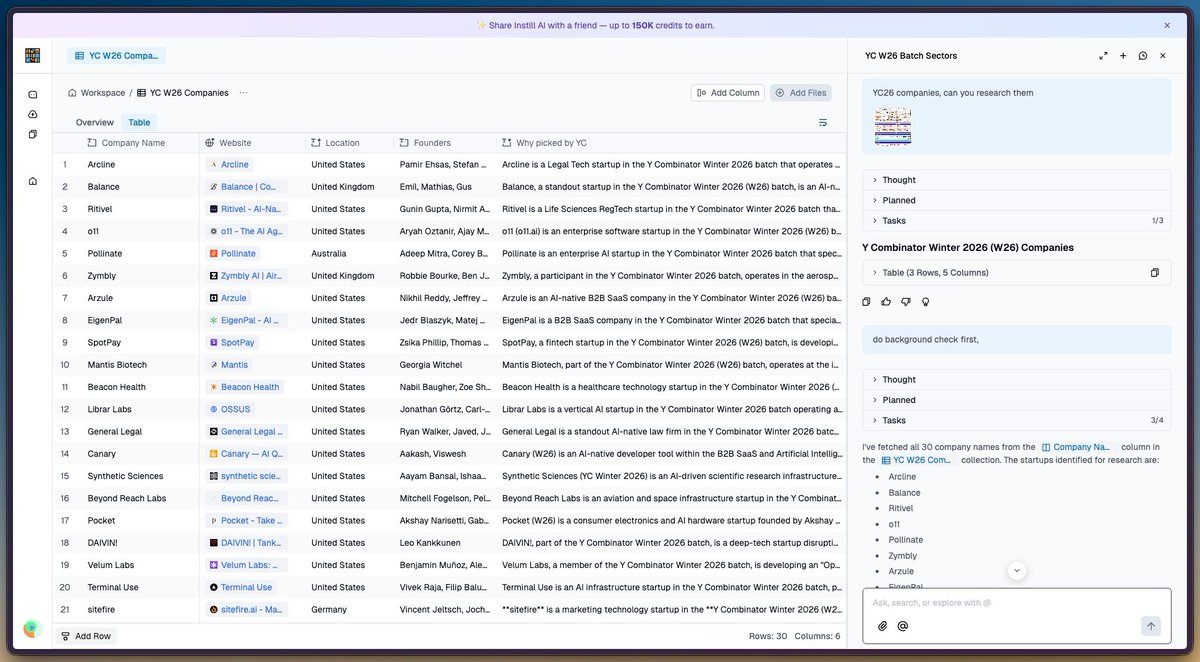
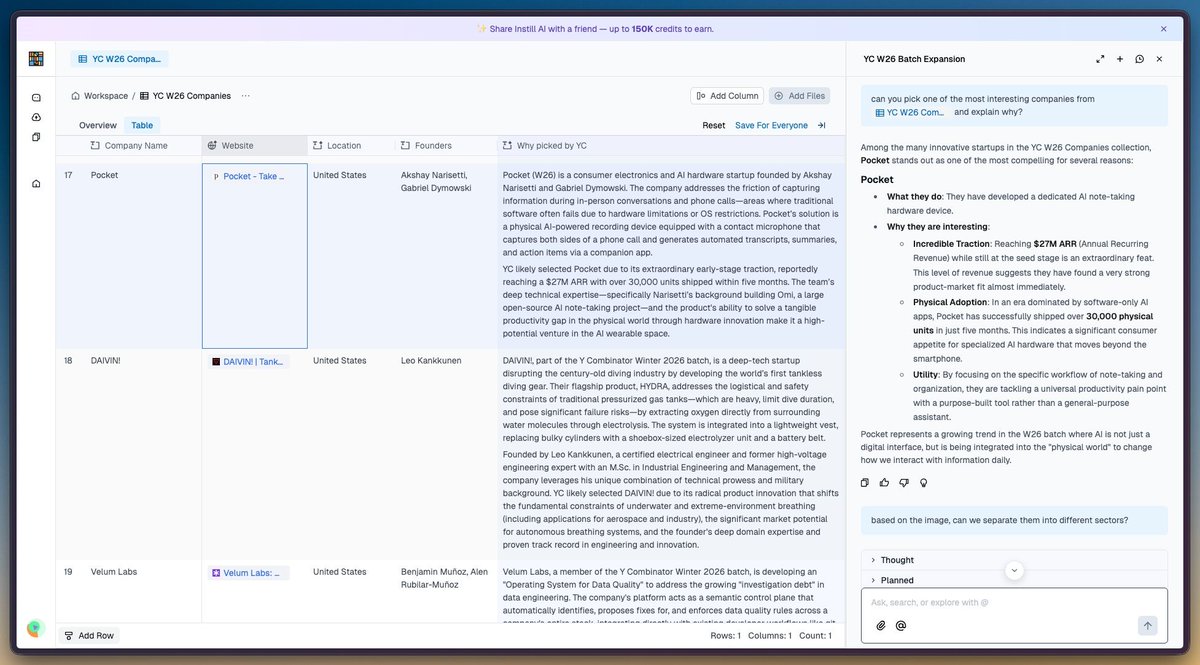
If you’re like me and curious about which hundreds of startups YC incubates in every single batch—and the "why" behind them—you can use Instill AI to curate a beautiful dataset in under a minute. (And then come back 18 months later to see which hundreds have already "perished.")
While you could get answers from ChatGPT, Claude, or OpenClaw, Instill AI makes that context persistent and organized, allowing you as a human to oversee your AI agents more effectively.
Basically, I (or my AI agent) just drop that YC poster image in, and let the Instill Agent organize it into a collection. Moving forward, this becomes high-quality context that you don't have to keep burning tokens to re-generate.
If you’ve started noticing that your agents are casually burning through millions of tokens, it’s not their fault—they just lack context! Give them a chance to redeem themselves; give them Instill AI.
Check the comments for the invitation link.
2
1
64
Mar 22
I just fed three of my PhD and Postdoc papers into Instill Agents to turn them into posters.
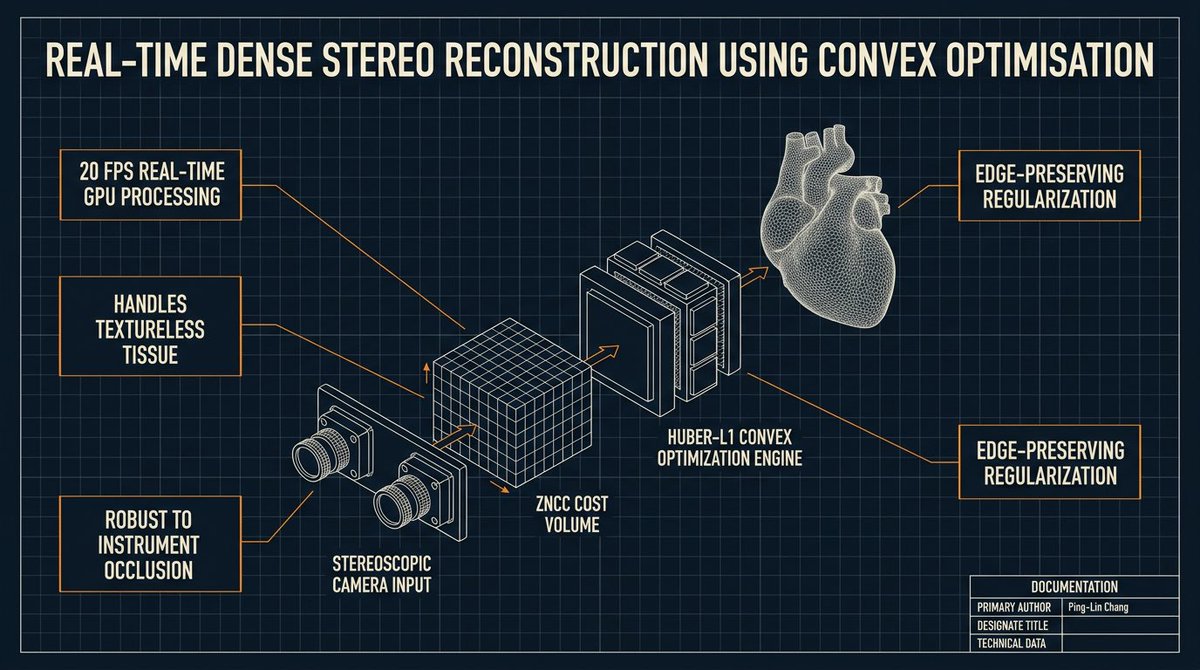
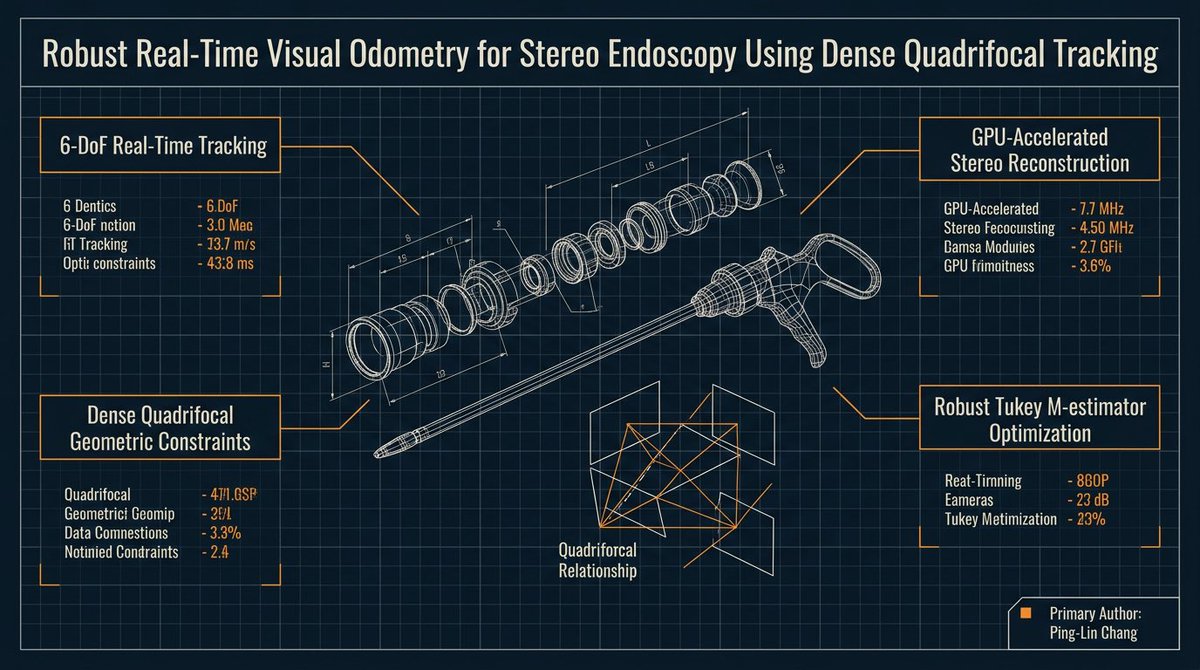
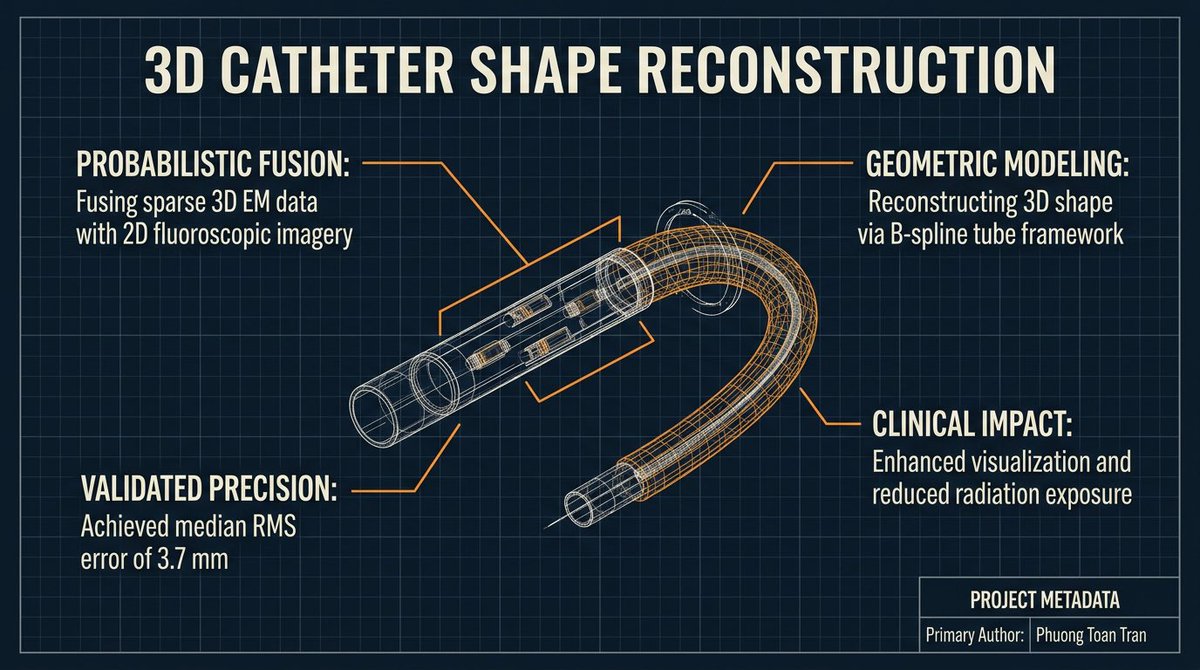
See that 3D cube? I spent two hours clicking my way toward carpal tunnel syndrome just to draw that. Back then (2011), the heart visualization required 3D scanning a mock-up model, getting the object file, rendering it with OpenGL shaders, and achieving CUDA interoperability for real-time 3D reconstruction and rendering.
The other two papers were from my "young and naive" days when I thought these would be commercialized within five years:
1. AR/VR for Prostate Cancer Surgery: Using the Da Vinci robot to "doodle" inside the bladder, guiding surgeons to avoid critical nerve tissue (preserving the patient's "future happiness").
2. Autonomous Robotics for Cardiovascular Surgery: Instead of a doctor manually pushing a catheter from the thigh to the heart—risking a fatal puncture—this EU project aimed to create a catheter that "swims" to the coronary artery, deploys the stent, and swims back out on its own.
1
78
Mar 22
Instill AI’s data model is called a Collection—think of it like a Notion database.
While a Collection looks like a table, it’s actually something much more powerful: it directly contextualizes both unstructured and tabular data.
What does that mean?
Today, we can do an incredible amount with unstructured data using Instill AI. It’s not magic—it’s the out-of-the-box benefit of transforming raw data into structured, contextualized information.
For example:
Storyboard → Slides → Visual storytelling
Research Paper → Context → Insightful report
Everything is handled 100% just by chatting with Instill Agents. 🚀
32
Mar 18
For Claude Code & OpenClaw agents, Instill AI is your access point to build and discover high-quality context:
mcp.instill-ai.com
For human knowledge workers, Instill AI is a place to chill:
instill-ai.com
We’re currently in private beta and happy to share invite links with both agent and human users.
Just comment or DM me.
1
72