
173 Photos and videos




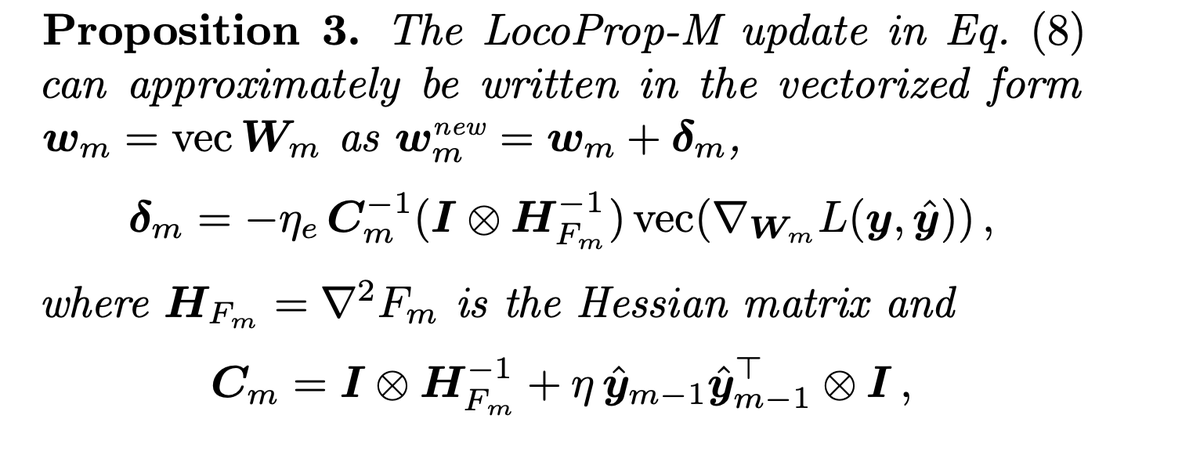



Plugyawn retweeted

Jun 13
Julius Caesar knife block.

993
9,083
95,016
2,910,663
oh, so that's how the sovereign AI races begin
Jun 13

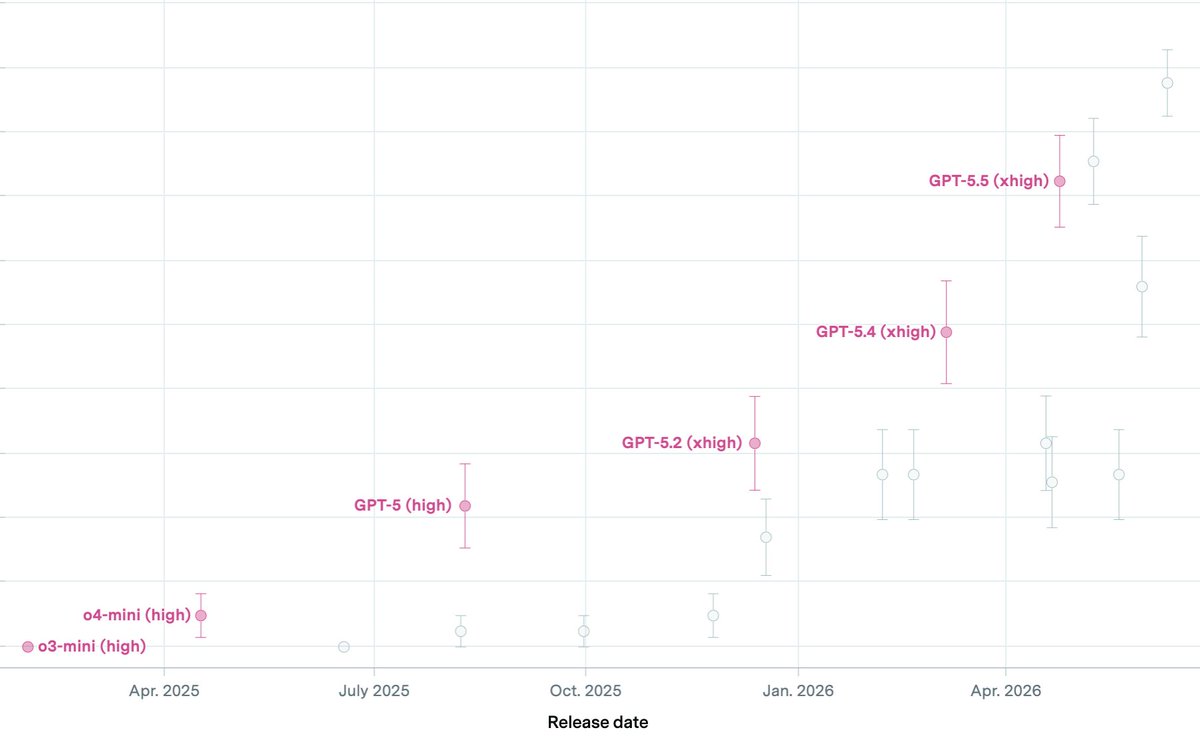
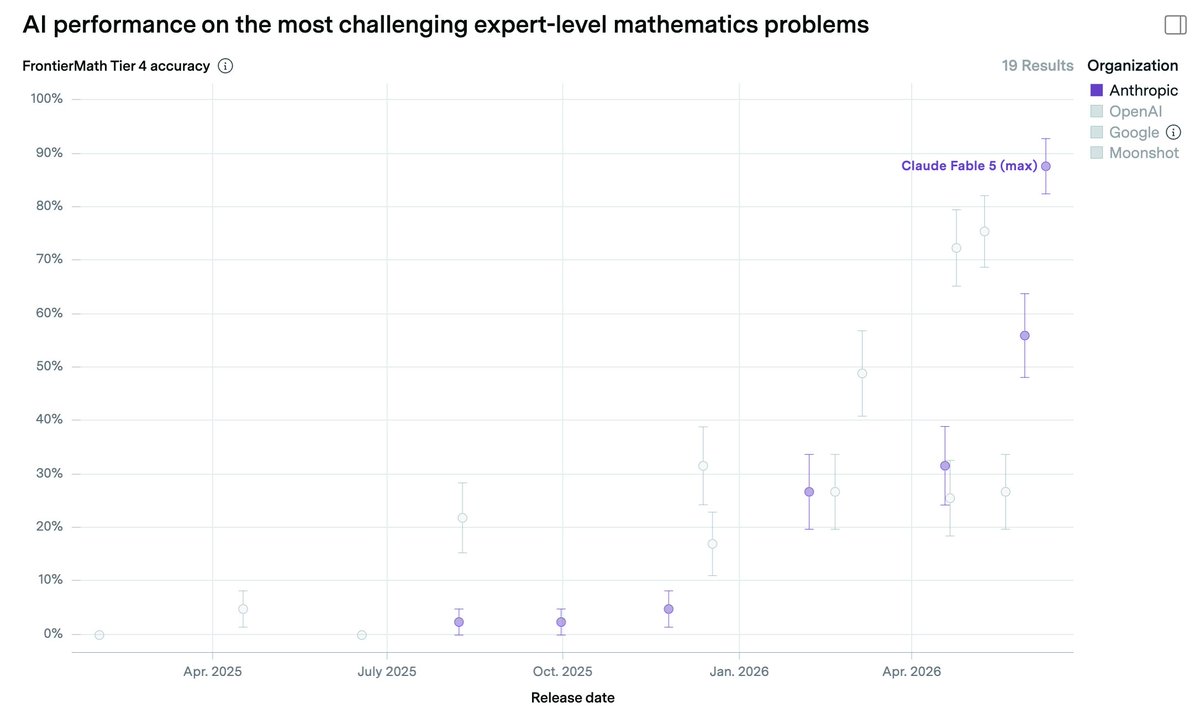
NEW: Anthropic claims the capability cited by the U.S. in restricting Fable 5 is already widely available from other models, including OpenAI’s GPT-5.5.
25
Plugyawn retweeted

May 6
This is a man who has thought through the long term consequences of ai generated imagery.
1
2
337
25,245
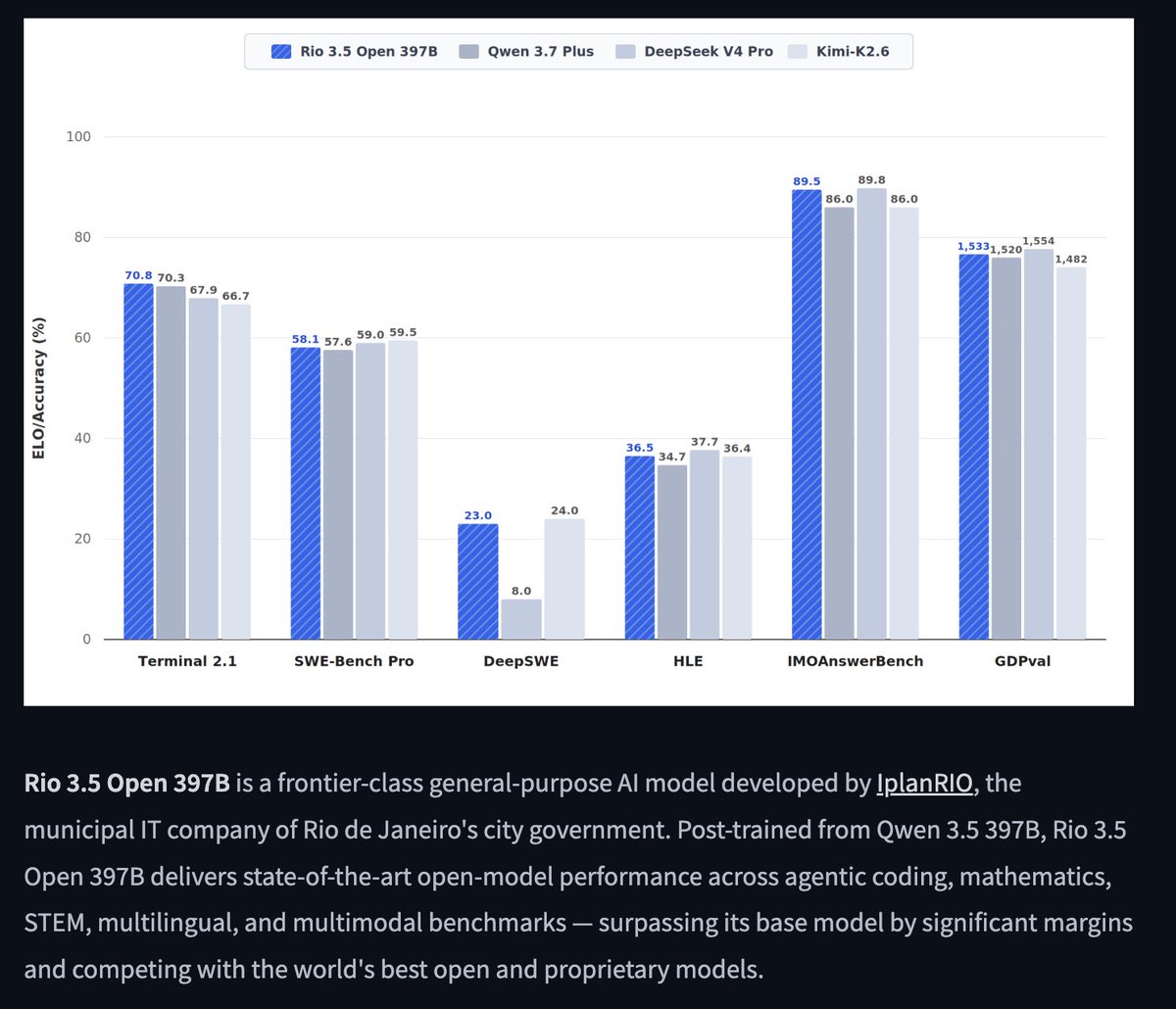
The LLM cake in India, or for that matter, the EU, is perhaps not a startup's to take. At some point knowledge about training diffuses enough and open-source algorithmic innovation brings down costs enough that it's commonplace to train foundational models surpassing humans in intelligence.
We may hope that at some point, by virtue of test-time scaling, the balance shifts somehow in favour of faster models: already, it appears that intelligence logarithmically scales with test-time compute. If the exponent is related to the extent of pretraining, I imagine it's possible to procure a smaller, faster model that thinks 10x the number of tokens in the same wallclock as a larger model.
In that case, the game will shift again, and may we then be ready with a manufacturing infra that can produce good ASICs.
But! There are more models to make, more modalities. Large, overparameterized models for computer-use, for agriculture, of logistics and of transport networks. Those are just as important, and perhaps one of the best uses of the superintelligence API. That game is not yet lost.
Jun 13

To train a GPT class 1T model from scratch - including failed runs, data acq clean rlhf, post-training, team/people will likely req $250M of compute on an aggressive 3-4mo schedule (i.e. more reserved GPUs), $500-600M all-in IF you do a dense one. MoE fp8 will cut costs by 1/10th depending on how many active params you have. If you want SOTA however, the budgets go significantly higher on test-time compute, post-training RL, and data/synthetic generations..and v. high on talent. Maybe $2-4B all-in. After that comes serving the model. The talent is key to get to SOTA/beat it - and then you have to ensure this is useful enough to have inference vol over time - for which the capital will come if there is usage / TAM. So this is not as much about raising $50-60B, or raising it all at once as the OP says - we are investors in mistral, sarvam, reflection and anthropic - and they all scaled capital over time as models got adoption, but the early bottleneck is more on talent GPUs at that scale where you can do interesting things.
2
141
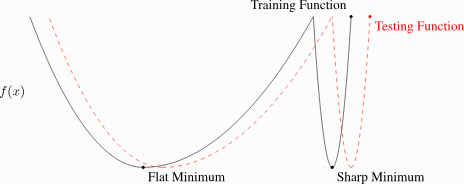
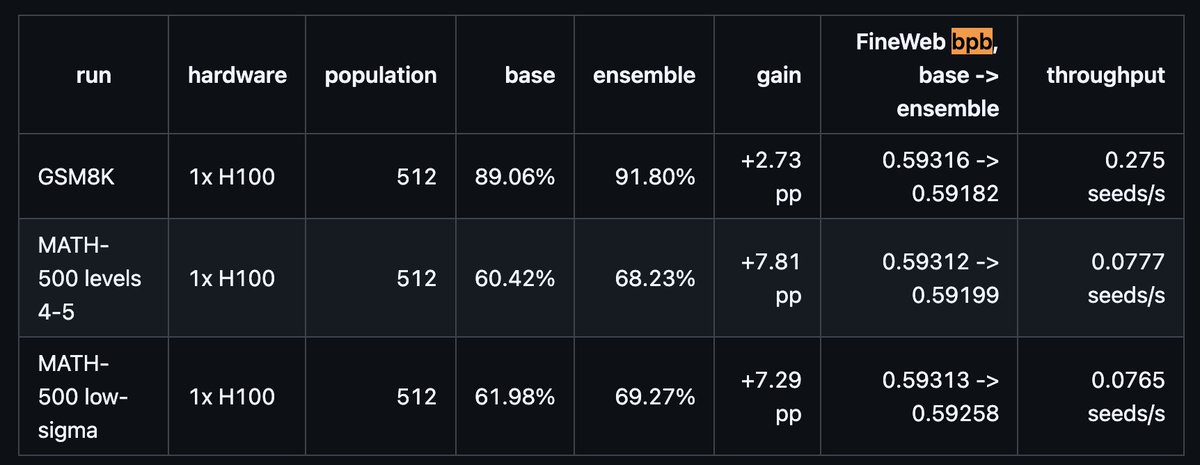
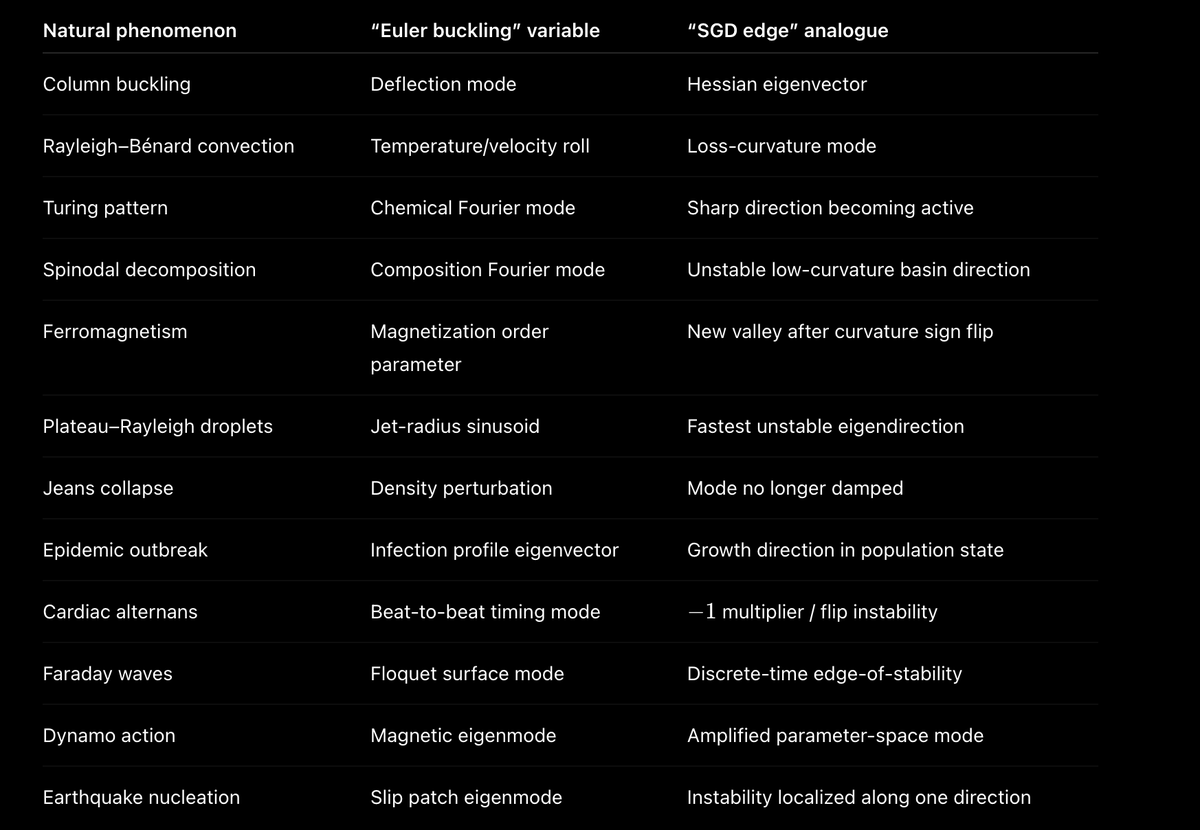
interesting that energy-minimizing systems trying to tackle instability everywhere come to this: linearize around the simple state, track extreme eigenvalues, and see what becomes a macroscopic quality when they cross a threshold.
considering linearization has strong ties to lazy learning (via the NTK line), EoS is maybe what explains why we see feature learning in large networks?
That's roughly your point too, right, @recurseparadox?
I see some work around NTKs and EoS, but I think NTKs are a dead end now sadly.
Jun 13

The Edge of Stability line of research shows you that most of the optimization is not happening due to geometry. All second order methods look good on Kellers benchmark benchmark because it needs too few steps with tiny models
1
89
An alternate view comes from @SadhikaMalladi's work on pretraining coverage too; I think thickets.mit.edu is a strong example of an emerging idea of "measuring" the pretraining process (higher probability of nearby task experts ~ better generalization, better pretrain?)
34
Locoprop is just a fascinatingly principled way to apply adaptive input-dependent compute in training. The problem seems to be that the base step is as expensive as a current full step, and there seem to be no half-steps.
But considering the embarrassing parallelism of the local problem, perhaps there can be some nice new overlap patterns?
1
101
so
SGD is G.
Locoprop-S converges to G (X.T @ X)
KFAC is (dY.T @ dY) G (X.T @ X)
Do we have a (dY.T @ dY) G?
Is Shampoo, via msign(G) doing something similar?
Newton-Muon is msign(G (X.T @ X)), so it would be similar to KFAC then?
@HessianFree @_arohan_ ?
1
72