
35 Photos and videos
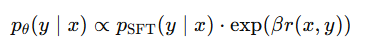





日积月累研究思路,并从第一性原理出来找到重要的问题
1. pick your own problems: choose an outcome you genuinely want to exist and reason backwards to the experiments.
2. inputs: read old papers with a wide range and depth/ read the paper itself
3. write ideas down
4. open you door

2
66

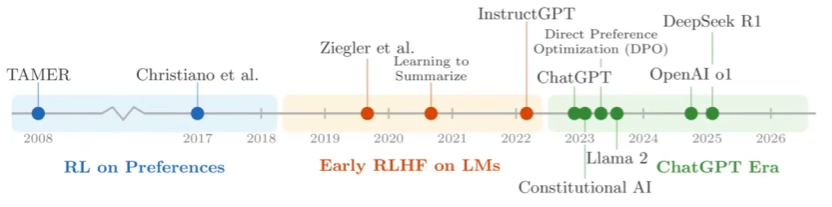
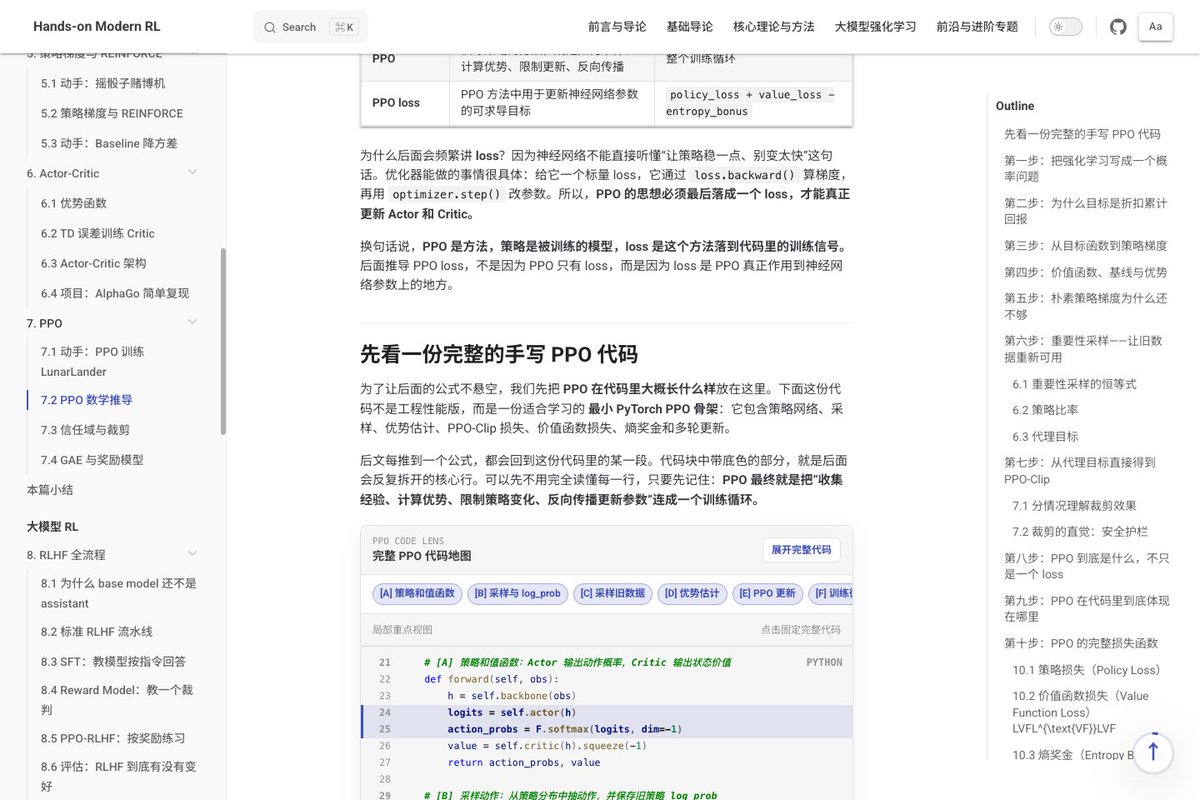
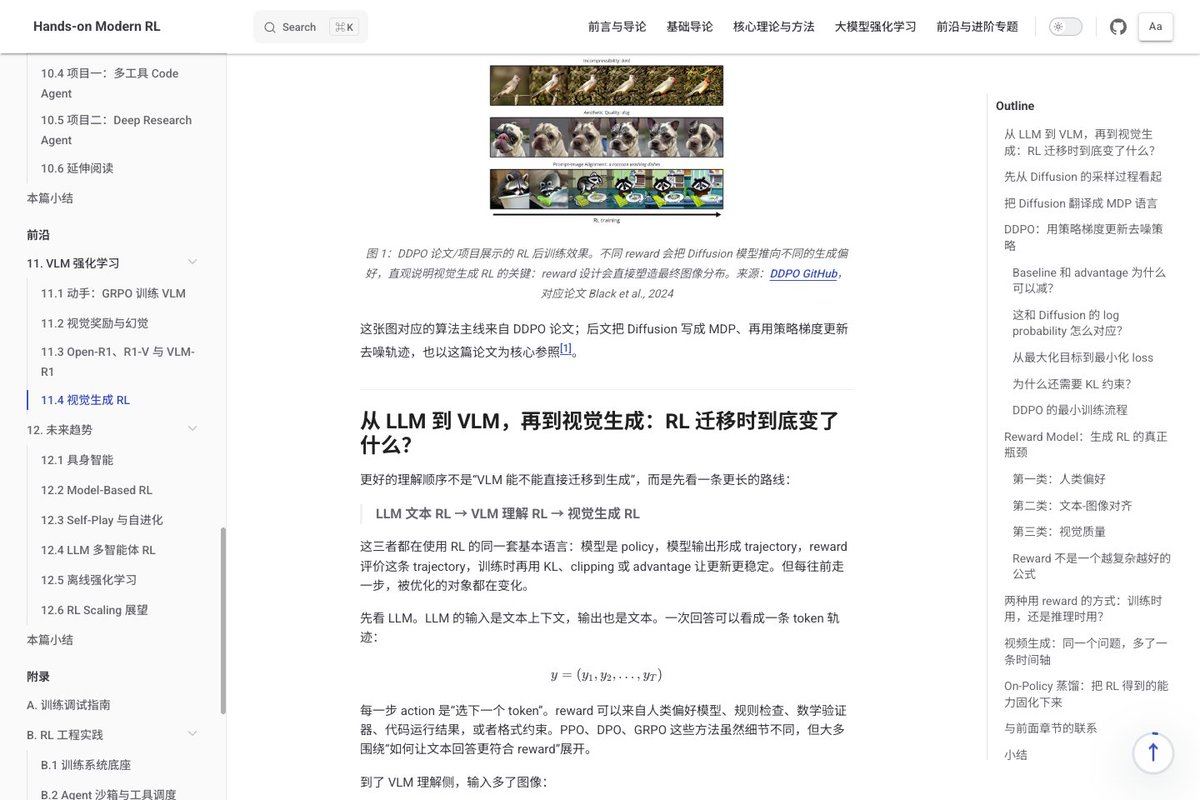
花了段时间写了 RL 教程 Hands-On Modern RL,路线是从 CartPole PPO 入门,然后到 LLM 后训练(RLHF、DPO、GRPO)、Agentic RL。代码先行,公式用来解释现象。英文版很快更新。
目前是草稿版本,RLHF、Agentic RL 部分本地审校中。
欢迎提 PR 或 Issue & 显卡支持:github.com/walkinglabs/hands…


51
343
2,041
332,856
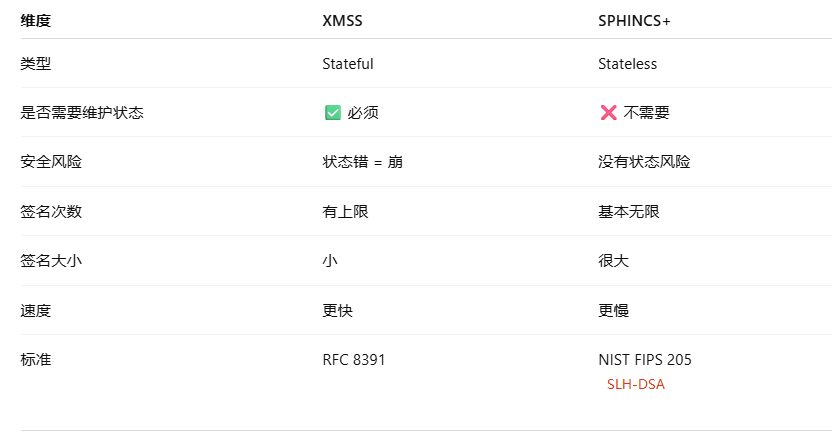
这里的shared sender容易误解成用户的地址(这样就很奇怪不同用户地址不一样),其实简单理解就是同一个 relayer EOA(或者 AA execution account)替很多用户上链
May 5

🔐 New EIP-8250: Keyed Nonces for Frame Transactions 🔐
by @soispoke, @nero_eth, @lightclients and @VitalikButerin
This replaces the single sender nonce with (nonce_key, nonce_seq), giving frame transactions independent replay domains.
For privacy protocols, the key can be derived from a nullifier: concurrent withdrawals from a shared sender become possible, with inclusion atomically marking the nullifier spent.
Target fork: Hegota
Links below 👇
1
1
162
full video: youtube.com/watch?v=U46fJ2bJ…

Creator of C , Bjarne Stroustrup:
AI-generated code isn't ready — it generates more bugs, more bloat, more security holes, and is nearly impossible to validate
"senior developers are already retiring rather than deal with it"
The problem is that even a small prompt change can shift the entire codebase in unpredictable ways
130

Creator of C , Bjarne Stroustrup:
AI-generated code isn't ready — it generates more bugs, more bloat, more security holes, and is nearly impossible to validate
"senior developers are already retiring rather than deal with it"
The problem is that even a small prompt change can shift the entire codebase in unpredictable ways
618
1,945
10,569
1,744,108
Reth's mempool design is fascinating. Wrote up my understanding of how best_transactions works — a k-way merge with nonce constraints, backed by an MVCC-like snapshot.
Full article:
hackmd.io/@near/Skzou8YkMx
1
57
Stanford
@CS153Systems
'26, Session 8 The Compute Behind Intelligence with Jensen Huang

90
Po🎏 retweeted

May 8
Codex grew programmatic policies with no neural nets: max score on Breakout, and SOTA-level scores on MuJoCo.
Maybe heuristics were not too weak. Maybe they were just too expensive to maintain. Maybe it's the next paradigm.
trinkle23897.github.io/learn…
64
235
1,442
3,206,857
Po🎏 retweeted

May 5
Introducing SubQ - a major breakthrough in LLM intelligence.
It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA),
And the first frontier model with a 12 million token context window which is:
- 52x faster than FlashAttention at 1MM tokens
- Less than 5% the cost of Opus
Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention).
Only a small fraction actually matter.
@subquadratic finds and focuses only on the ones that do.
That's nearly 1,000x less compute and a new way for LLMs to scale.
1,491
2,876
23,036
12,992,326
Po🎏 retweeted

Apr 28
After 6 months of work, we're proud to finally share our first release of our new smart contract language:
Plank v0.1 🚀
To fix the fundamental issues plaguing smart contract development we're rebuilding the language stack from the ground up. 🏗️
Learn more 👇
57
50
469
45,330
Cool!
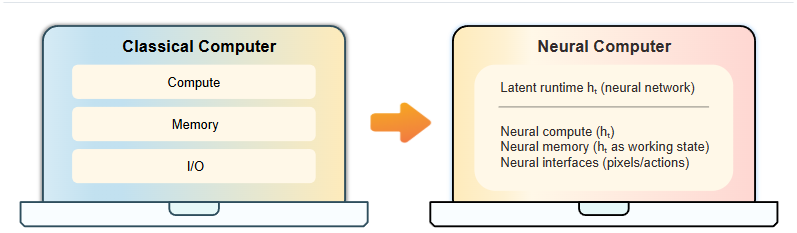
A mini, from-scratch PyTorch-like ML framework in TypeScript Rust—runs on CPU/CUDA/WebGPU and built to understand deep learning from the ground up.
github.com/mni-ml/mni-ml.git…
github.com/mni-ml/framework
Apr 21

I added KV caching and INT8 KV quantization to our transformer inference, improving throughput by 35x.
All of this was done from scratch in Rust CUDA, on top of a homemade ML framework.
On a 4-token prompt with 252 generated tokens:
- Original: 0.76 tok/s
- KV cache fp32: 27.21 tok/s
- KV cache int8 (quantized): 27.29 tok/s
Try it out yourself here: mni-ml.github.io/demos/kv-ca…
In practice:
- KV caching gave us about a 35x end-to-end speedup
- INT8 KV cache kept roughly the same speed as fp32 but cut KV cache memory by 3.78x
FP32 cache used 4.5 MB in this run while the INT8 cache used only 1.19 MB
This simple change to inference created a huge impact on performance. To learn more about the KV cache and other optimizations like this, check out the blog at mni.ml!
2
105
Cool~ Enable it:
- Open Settings in the Codex app.
- Go to Personalization and make sure Memories is enabled
- Turn on Chronicle below the Memories setting
- Review the consent dialog and choose Continue
- Grant macOS Screen Recording and Accessibility permissions when prompted
Apr 20

Last week, we released a preview of memories in Codex.
Today, we’re expanding the experiment with Chronicle, which improves memories using recent screen context.
Now, Codex can help with what you’ve been working on without you restating context.
51
分享3个理解AI底层原理的实战课:
diy-llm 斯坦福CS336中文课程
github.com/datawhalechina/di…
base-llm 大模型基础与微调量化
github.com/datawhalechina/ba…
happy-llm 从零开始构建大模型
github.com/datawhalechina/ha…
2
111

No worries, buddy. All your stuff is fully stored on-chain here and is accessible via the web3:// protocol. Check it out: vitalikblog.w3eth.io.
1
1
67