
Researching reasoning @OpenAI | Co-created Libratus/Pluribus superhuman poker AIs, CICERO Diplomacy AI, and OpenAI o-series 🍓 reasoning models
Joined January 2017
- Tweets 1,674
- Following 916
- Followers 135,471
- Likes 6,889
163 Photos and videos









Pinned Tweet

12 Sep 2024
Today, I’m excited to share with you all the fruit of our effort at @OpenAI to create AI models capable of truly general reasoning: OpenAI's new o1 model series! (aka 🍓) Let me explain 🧵 1/

231
1,512
11,348
2,905,976
Jun 11
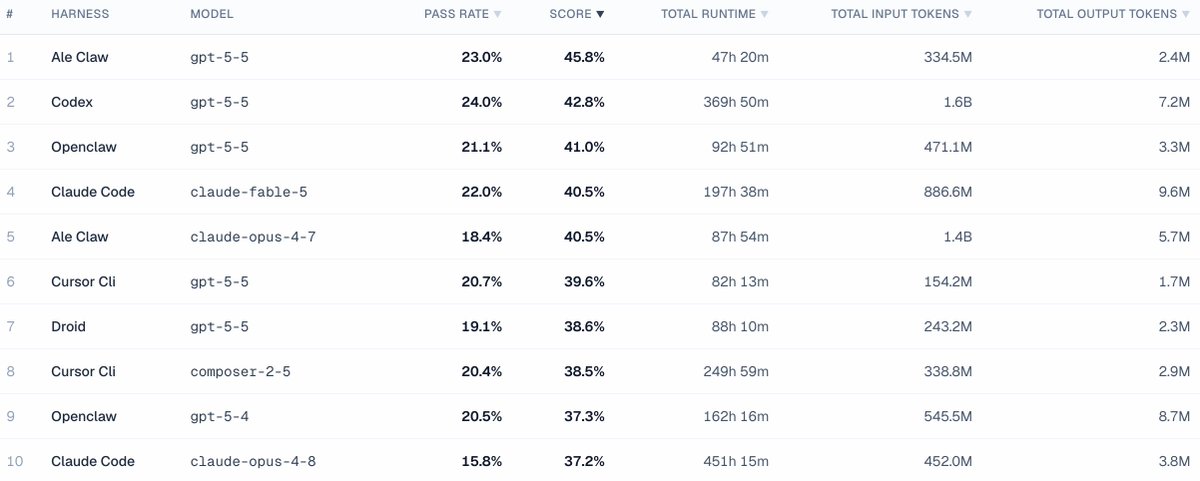
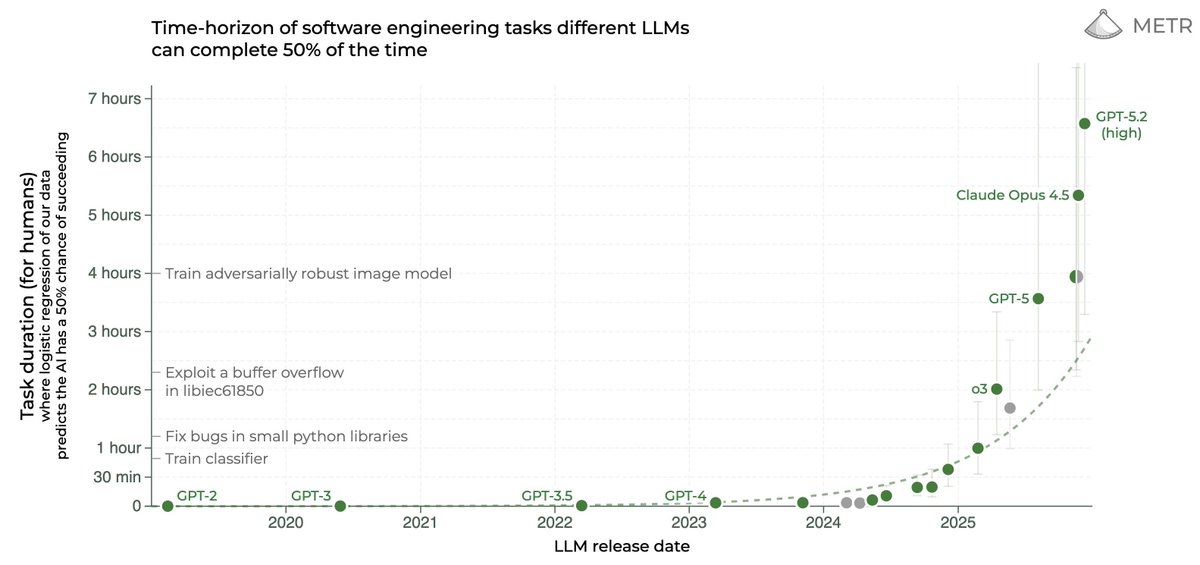
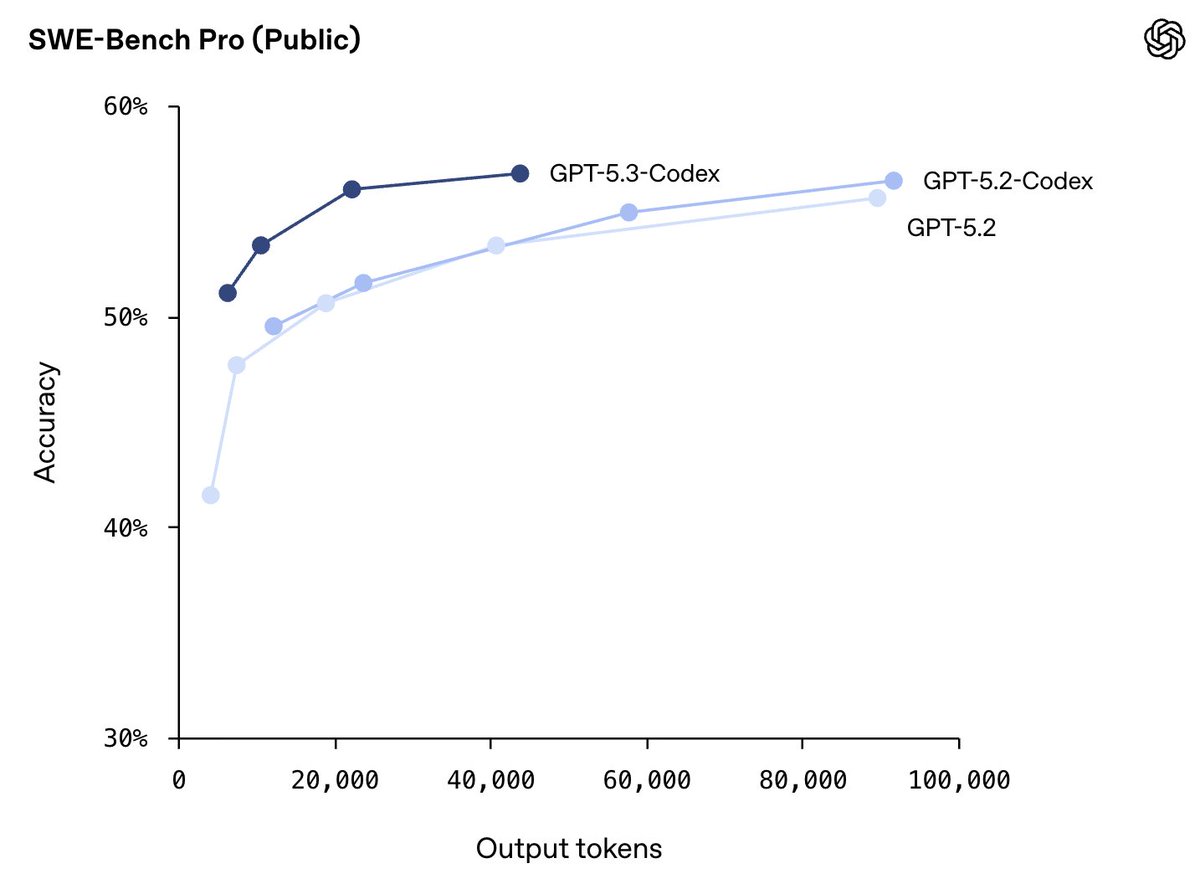
I'm happy GPT-5.5 tops this eval
I'm even happier it's still doing the best when measured vs tokens, cost, or wall-clock time!
Jun 11

Everyone says the latest AI agents will be "job-ready" soon, especially after the release of Fable 5 this week. But is that really the case?
Over the past many months, my group and collaborators have been building Agents' Last Exam (ALE), a benchmark designed to test exactly that claim on real digital labor-market work.
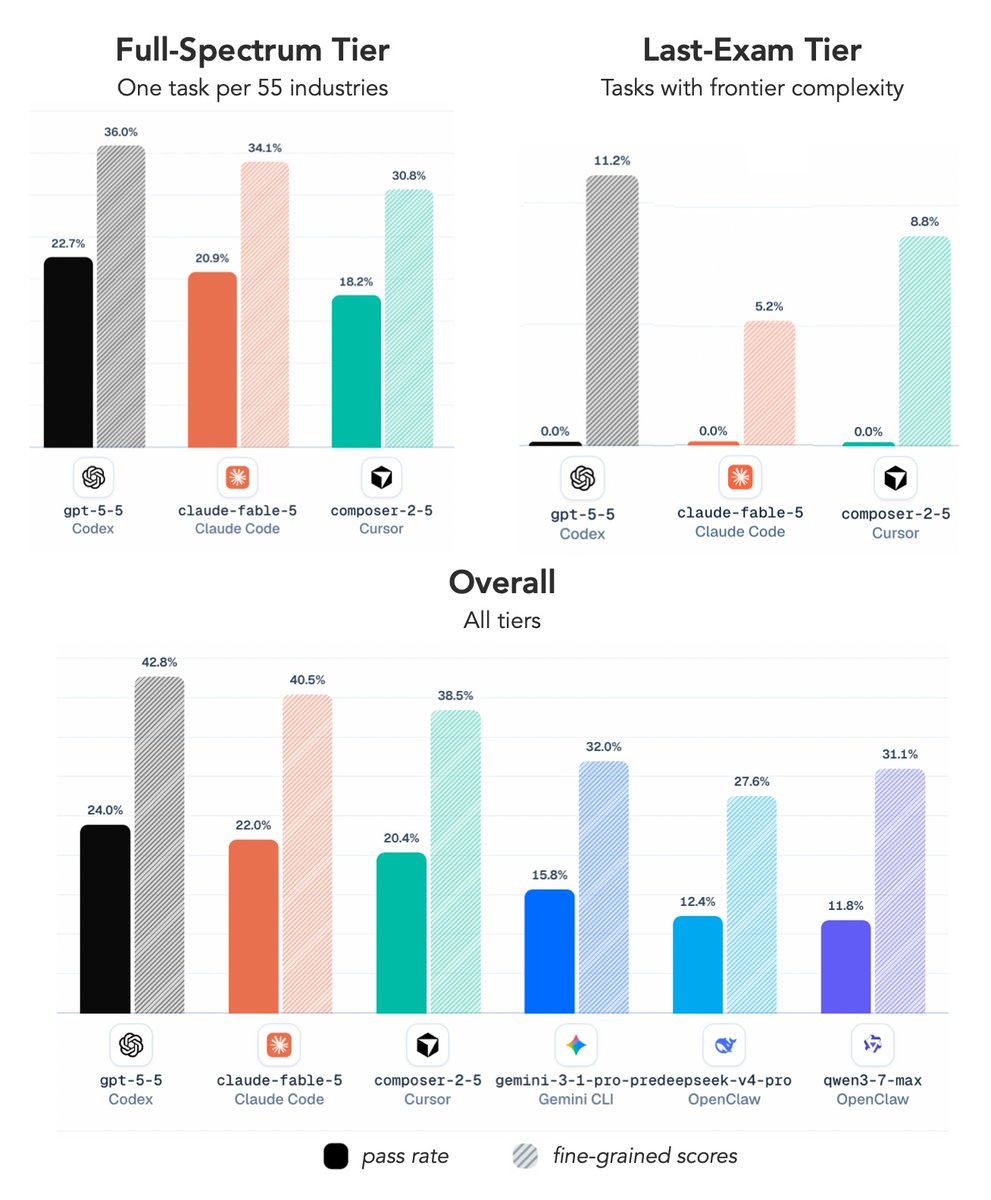
My group and collaborators previously have created many of the benchmarks the field runs on, including MMLU, MATH, CyberGym, and ExploitGym. Today, I'm excited to share Agents' Last Exam (ALE): a rolling benchmark that measures whether AI agents can actually perform economically valuable work across a broad range of real-world domains.
With ALE, we evaluated Fable 5, GPT-5.5, Composer 2.5, and other frontier agent systems across more than 1,500 expert-sourced tasks spanning 55 occupations.
The result is both impressive and sobering.
Today's agents can solve a meaningful fraction of professional tasks. But when we look at the hardest tasks, the ones requiring sustained reasoning, deep domain expertise, and reliable execution over long horizons, they are still far from human-level performance.
On ALE's hardest tier, every frontier agent we tested, including Fable 5, achieved a 0% success rate.
The age of useful agents is here.
The age of truly job-ready agents is not.
We hope Agents' Last Exam (ALE) will serve as a new guidepost and north star for developing agents capable of reliably performing economically valuable work across a broad range of domains.
🧵
23
40
721
89,407
Jun 9
We've known about LLM test-time compute scaling since @OpenAI o1.
Yet 2 years later labs still report scalar evals for models; safety orgs are still surprised when a scaffold does better via 100x inference; and RSPs still ignore inference budget when deciding critical thresholds.

33
68
860
80,410
Noam Brown retweeted

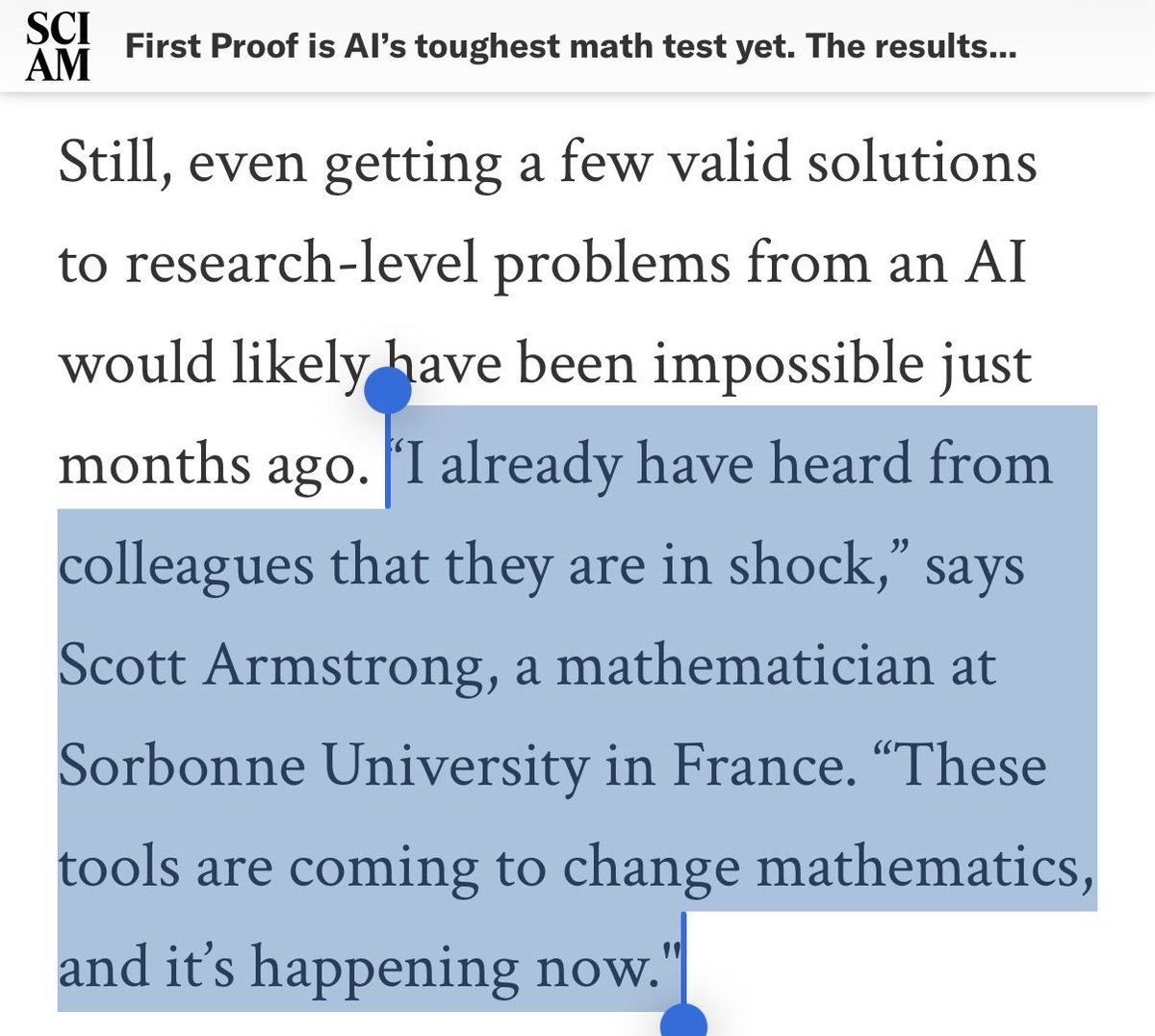
I think people underestimate the effect GPT-5.x is already having on research in mathematical fields. 5.5 Pro has been proving many theorems for me, but I don’t talk about it much because I want to publish those results with my name on it and that’ll take time to write up.
42
63
1,002
156,936

What happened when one of our models found a counterexample to an 80-year-old Erdős conjecture?
Researchers @alexwei_, @HongxunWu, and @wjmzbmr1 shared the story on the OpenAI Podcast with @AndrewMayne and explained how mathematicians and models can work together to make new discoveries.
166
151
1,377
287,856
Noam Brown retweeted

Jun 4
Very excited to share our interview with @polynoamial on AI for math — the Erdős unit distance problem, saturating the IMO, the future of math research, and more!
23
80
628
184,342
May 28
After AlphaGo, the skill of human Go players noticeably improved. I suspect we will see a similar pattern in math.

Another major problem, this time in additive combinatorics, has fallen, this time to humans rather than AI, but using methods related to the AI solution to the unit distance conjecture.
187
973
9,041
784,335
Noam Brown retweeted

May 21
1/ Today, an internal @OpenAI model has refuted Erdős’s unit distance conjecture — a research result that one could recommend “acceptance without any hesitation” to the Annals of Mathematics, one of the most prestigious journals in mathematics.
We came across it in a side quest to push our model on the hardest problems.

Today, we share a breakthrough on the planar unit distance problem, a famous open question first posed by Paul Erdős in 1946.
For nearly 80 years, mathematicians believed the best possible solutions looked roughly like square grids.
An OpenAI model has now disproved that belief, discovering an entirely new family of constructions that performs better.
This marks the first time AI has autonomously solved a prominent open problem central to a field of mathematics.
9
85
645
116,355
May 20
Today, we’re sharing that a general-purpose internal @openai model achieved a breakthrough on one of the best-known combinatorial geometry problems. Less than 1 year ago frontier AI models were at IMO gold-level performance. I expect this pace of progress to continue.
Today, we share a breakthrough on the planar unit distance problem, a famous open question first posed by Paul Erdős in 1946.
For nearly 80 years, mathematicians believed the best possible solutions looked roughly like square grids.
An OpenAI model has now disproved that belief, discovering an entirely new family of constructions that performs better.
This marks the first time AI has autonomously solved a prominent open problem central to a field of mathematics.
81
193
2,398
448,704
May 20
This is a general-purpose LLM. It wasn’t targeted at this problem or even at mathematics. Also, it’s not a scaffold. We have not pushed this model to the limit on open problems. Our focus is to get it out quickly so that everyone can use it for themselves.
39
70
1,010
248,349
May 20
Since people are asking, no it did not use Lean. But I don't think it should matter anyway.
16
20
609
46,779
Noam Brown retweeted

If you are a mathematician, then you may want to make sure you are sitting down before reading further.
167
886
9,222
3,222,243
May 19
Andrej @karpathy is back in the game! I would have loved for him to rejoin @OpenAI, but I'm happy he's at any frontier lab pushing the field forward. It’s easy to frame this as zero-sum among the labs, but in truth we’re collectively advancing the most important tech of our era.
May 19

Personal update: I've joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.
64
127
3,702
215,961
May 14
It's now even easier to keep your agents running productively 24/7
You've been asking for this one...
Now in preview: Codex in the ChatGPT mobile app.
Start new work, review outputs, steer execution, and approve next steps, all from the ChatGPT mobile app. Codex will keep running on your laptop, Mac mini, or devbox.
18
13
315
28,253
Noam Brown retweeted

May 13
Want to (officially) use Codex at work?
Send this post to your CTO to bring your team to Codex. Eligible enterprise customers who switch in the next 30 days get 2 free months of Codex usage for new users.
230
285
4,129
1,306,198
May 12
I love seeing a new eval with such low scores. When we announced GPT-5.5, almost every benchmark had a score above 50%.
It's time to retire evals like GQPA and bring in a new set.
May 12

The first ProgramBench task was just solved by GPT 5.5 high/xhigh. Interestingly, high/xhigh picked two different languages for the task (C vs Python). GPT 5.5 xhigh was significantly better than Opus 4.7 xhigh in all metrics. 🧵
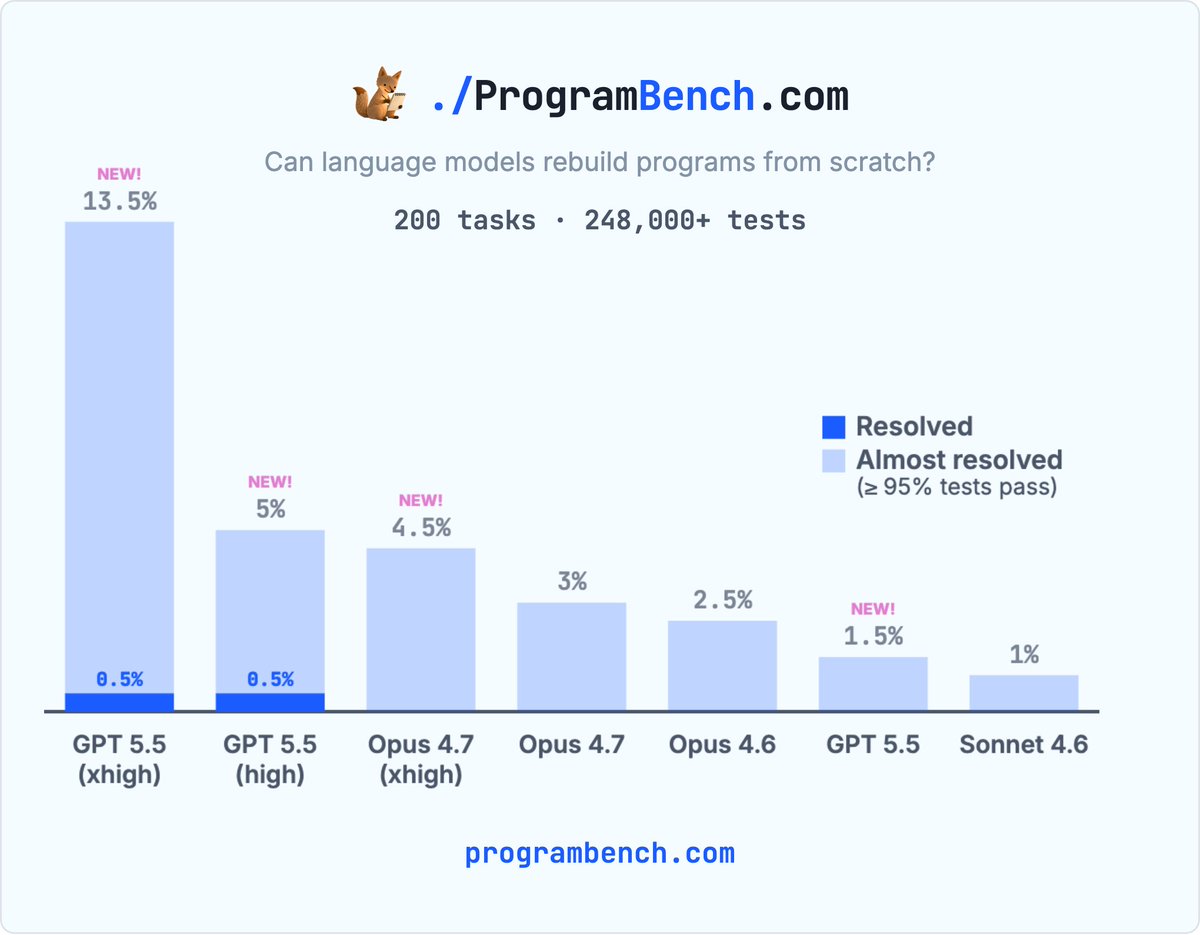
28
45
883
106,951
May 12
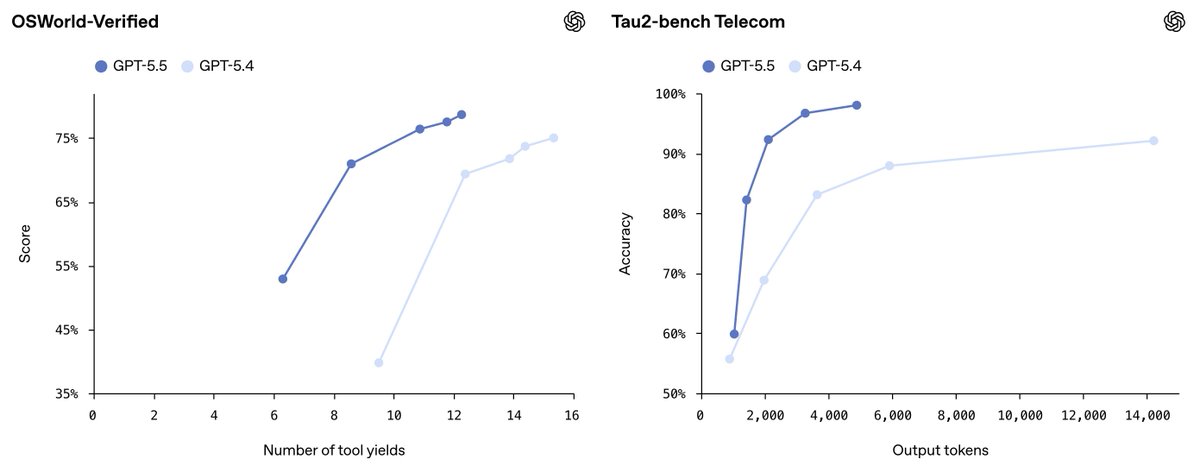
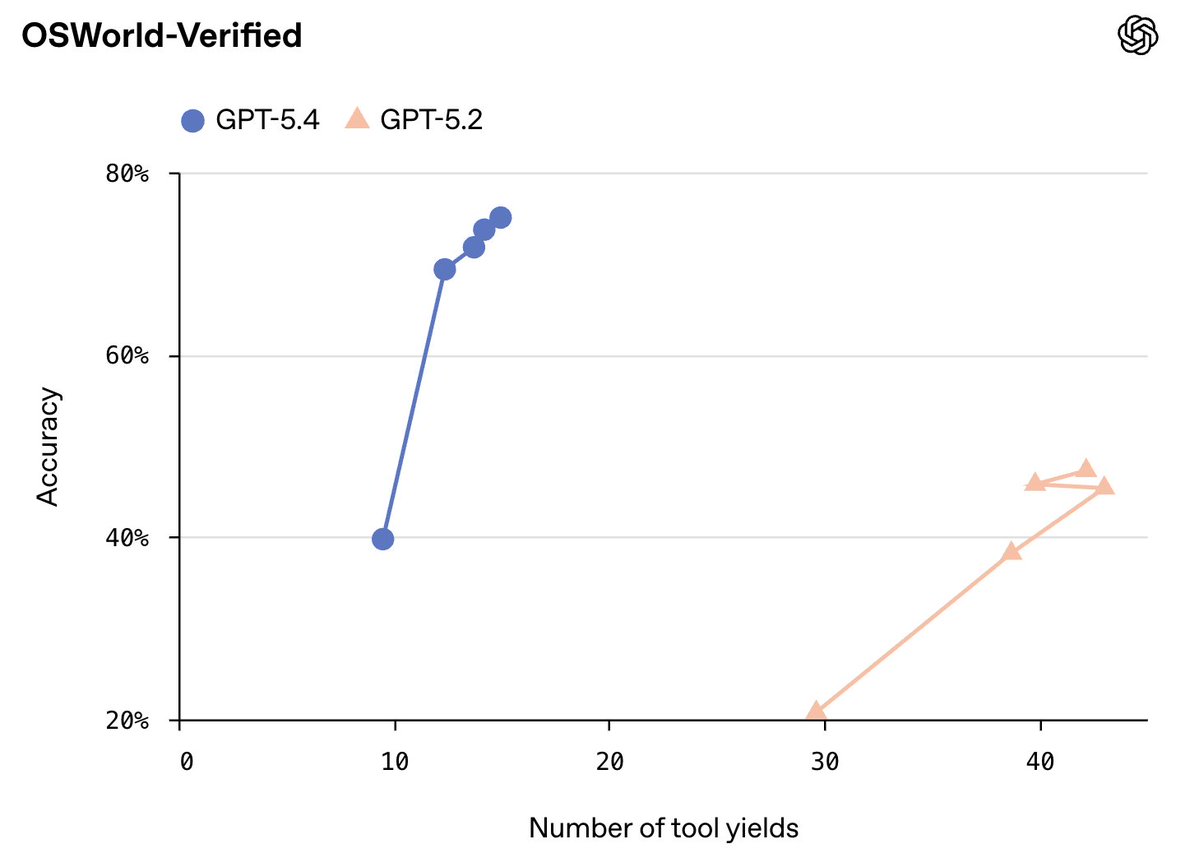
And, of course, they should be plotted with compute, latency, or cost on the x-axis.
6
1
114
8,159
May 12
Fun fact: the fatal errors were initially flagged using @OpenAI's GPT-5.5
May 12

We are conducting an AI-assisted review of FrontierMath: Tiers 1-4. This has flagged fatal errors in about a third of problems, and we believe most of these flags to be valid. We will release updated scores on a corrected dataset after completing a thorough human review.
17
67
1,019
148,322