
Building data integration for service businesses.
Joined June 2024
- Tweets 725
- Following 52
- Followers 61
- Likes 217
20 Photos and videos














Max Tappenden retweeted

18h
PM: "let us walk you through this pristine roadmap we have created..."
VP: "Yes, see how effectively this roadmap lets us reach our goals..."
CEO: "...."
4
6
142
20,912

Jun 14
This is useful data. Our current harness uses Opus 4.8 x2-4 (scale depending on task). We had 72 hours of glory with Fable x2-4, but that’s gone now, and Opus isn’t cutting it.
Biggest barrier is modifying the harness for OpenAI generic vs Anthropic. Also… I’m probably out of touch here, but can other models reliably use tools now? That was a big reason for settling with Anthropic.
Jun 13

Introducing the Fusion API, the smartest compound model in the market.
Fusion achieves Fable-level intelligence at half the price.
How it works 👇

114
Jun 13
FoundationDB simulation is exactly the kind of task that is meaningfully better with Fable vs Opus.
My weekend sucks because the Administration called @Anthropic’s bluff on their pernicious cyberweapon / regulatory posture.
Perhaps it’s time to grow the fuck up ahead of your planned IPO?
1
42
Jun 14
I thought I was done, but my work here uncovered a real hygiene issue. Must clip fingernails. That's a sharp edge. Have filed medium priority Plat-N.
16
Jun 12
This is your gentle reminder that any comply claiming its product is open source, while releasing it with a BSL licence, is explicitly and deliberately lying to you.
1
1
98
Jun 12
David Hockney has died. I asked Grok to imagine his wake in the style of David Hockney.
1
101
Max Tappenden retweeted

Jun 10
DeepMind cofounder Shane Legg thinks that search is essential for a model to be genuinely creative.
Pre-trained base models can do incredible things. But Shane thinks this is just a matter of them mixing together existing concepts from their training data.
If he's right, coming up with genuinely novel ideas always involves searching a large space for "hidden gems".
36
32
306
35,507
Jun 10
Do y’all remember when compilers eliminated software engineering as a profession?
27
Jun 10
And this makes you afraid for the future of software engineering because… what? You don’t understand the economics of productivity?

Claude Fable 5 is by far the most ridiculous model that makes me genuinely afraid for the future of software engineering.
I compiled the top 10 most unbelievable things I've seen Claude Fable 5 do today:
— Migrate a 50M line codebase from Stripe in a day (humans take 2mos)
— Draw amazing 3D graphics a) Boeing 747 b) space simulations with >5000 objects c) Minecraft roller coasters d) full photorealistic forest scenes e) NYC skyline f) stormy clouds)
— One-shot Pokemon FireRed the game
— Optimize a real world proprietary interaction net evaluator 10x more than the next best model, gpt5.5
AND it's about the same price as GPT 5.5 ($10/M input, $45/M output) vs Fable 5 ($10/M input, $50/M output) and 6x cheaper than GPT 5.5 Pro.
Community note
The claim misrepresents Anthropic's report: Fable 5 performed a codebase-wide migration within a 50M-line codebase in one day, not a full 50M-line migration. GPT-5.5 standard pricing is $5/M input and $30/M output, not the $10/$45 long-context rates used in the comparison. anthropic.com/news/claude-fa… developers.openai.com/api/docs/prici…
50
Max Tappenden retweeted

Jun 9
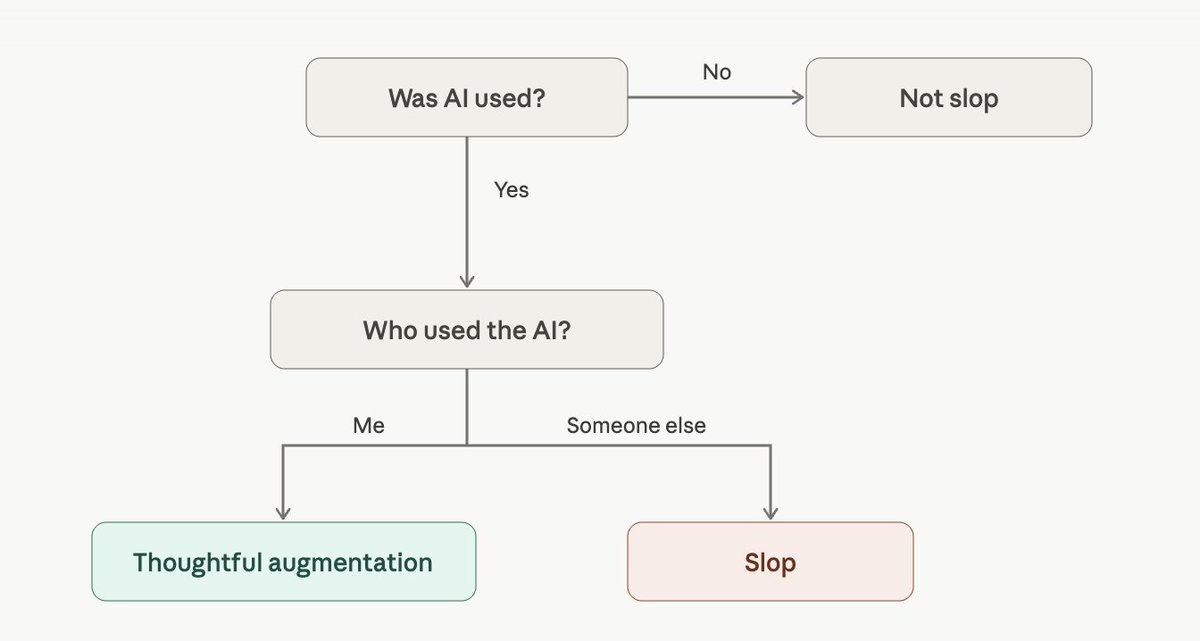
I just open sourced my "Is this slop?" simple test
115
1,045
19,176
452,812
Jun 10
.@AnthropicAI @claudeai So we can't use Fable 5 to test our edge auth? This is fucking absurd.
1
32
Jun 10
Fable 5 is supposed to be able to handle long-running autonomous tasks. My initial experiments were encouraging, but it appears to be a false promise.
26
Max Tappenden retweeted

Jun 7
Excellent observations from latest @lennysan podcast episode with @tfadell
None of these 4 points is new to an experienced product builder, but nearly every product builder still severely underestimates the degree of differentiation and success that’s possible with these skills.

28
42
474
34,396
Jun 4
A genuinely useful tool is now even more accessible. Use it for testing. Use it for internal tooling.
Jun 4

Hookdeck CLI is now in Homebrew Core!
`brew install hookdeck` 🤩
1
3
175
Jun 4
Engaging with me in bad faith is one way to go, of course, but I don't recommend it.
38
Jun 4
1/ I got burned badly by @SurrealDB.
I made a core architectural decision based on their published ambitions and roadmap. When I asked how their moves reconcile with those promises, they told me: “Interesting, we'll have to change the copy on this to avoid confusion.”
In other words: we lied, or we’re happy to memory-hole it. Don’t trust forward guidance from these companies. It can be stale, marketing-led, or deliberately fraudulent.
1
139
Jun 4
2/ The stated goals, license, and architectural guidance of an open source project wholly owned and directed by one commercial interest should never be taken at face value.
@SurrealDB is the textbook case. They sell you the open source vision, you build on it, then they pivot to commercial control and rewrite the docs so the old promises “never existed.” Their open source narrative was, and remains, a lie.
1
125
Jun 4
3/ This isn’t open source in any real sense. It’s commercial control wearing an open source costume.
If you’re evaluating @SurrealDB (or any similar project), treat their openness narrative as what it is: bullshit designed to get you to bet your architecture on them, then change the rules when it suits them. In any serious profession this would get people sanctioned or fired.
I already paid the price. Don’t be like me.
119