
Your CTO and dev team. One agent.
Joined August 2023
- Tweets 937
- Following 168
- Followers 1,852
- Likes 273
339 Photos and videos













Jun 12
Token efficiency and AI ROI won’t be solved at the model layer. The challenge will take place inside the harness.
If the primary interface to your product is going to be through agents, managing agent friction and efficiency precisely will be a deciding factor for your product's adoption.
Think about the unit economics: If the only way for end-users to get reliable results is to throw a heavy frontier model at your product, that massive token cost gets attributed directly to your product—even though you never see a dime of that spend. What happens when the token costs required to use your application suddenly exceed the actual subscription price?
Providing the right context and the right tools at the exact right time is the only way to squeeze frontier-model quality out of your system without breaking the bank.
True "tokenmaxxing" isn't about burning as many tokens as possible. It’s about maximizing your specific engineering efficiency per token.
Because the vast majority of digital workflows ultimately boil down to a simple loop of files and data in, files and data out, coding agents have naturally emerged as the most efficient general-purpose agents on the market.
But forcing a single, generalized agent to handle every unique workflow creates bloat. The natural progression is a coding agent that is intentionally biased toward proprietary tools and supported by a bespoke context design.
This optimized, harness-driven approach is what allows companies to provide their end-users with highly capable, agent-enabled applications at a price point that is actually tenable.
We built @predotdev from the ground up to serve as this exact orchestration plane.
If you are looking to build highly specialized, cost-effective coding agents on top of your own unique product infrastructure, let’s talk. Our harness is engineered to make it happen.
2
3
181
pre.dev retweeted

Jun 11
We are web sandboxed by default, but soon you will be able to drive @predotdev on your local filesystem and sync seamlessly with the cloud with the release of our new predev CLI

1
1
62
Jun 11
Token budgets are becoming a deciding factor for candidates evaluating engineering roles.
It is still early, but the shift is real. Based on our conversations with teams tokenmaxxing (in a good way), we are seeing a few common trends.
Here is our breakdown of the Do’s and Don'ts of managing enterprise token budgets:
Jun 11

Heads up, business leaders: This will soon be one of the most frequent questions you face when hiring engineers.
"What’s the token budget associated with this role?"
It sounds absurd until you look at the macro numbers.
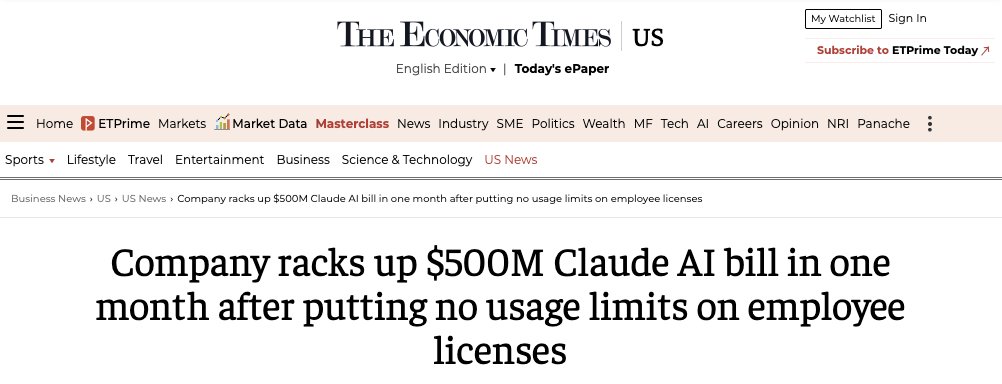
Not only is coding agent adoption rising, but as models grow more advanced, the unit cost for compute is compounding. Amazon recently made headlines for spending $500 million on tokens in a single month, while Uber completely burned through its entire annual AI budget in just four months.
Organizations are rushing to gain control over token spend and measure true ROI, all while providing their engineers with the best tools for the job.
If you are developing a strategy around token management, here is a practical breakdown of the operational Do’s and Don'ts we are observing in the wild:
The Do's
Maintain Model Flexibility: Avoid vendor lock-in. Ensure the harness that operates your coding agents allows you to swap underlying models, including open-source options and third-party APIs.
Enforce Discipline: Software development best practices are eroding fast under AI usage. Engineers jump straight into coding prompts and skip structural design. Ensure your systems require agents to plan, estimate, and verify tasks before writing code. Your harness should feature a dedicated planning layer that integrates cleanly with your project management tools and provides a long-term execution graph.
Implement Routing: A robust planning layer also gives you predictability. When your harness understands the scope and complexity of a feature beforehand, it can act as an orchestration plane and route individual subtasks to the most cost-effective model tier capable of handling it, rather than default-spending on premium frontier models.
Decouple Engineers: Your developers do not need to sit and babysit agent loops in their terminals. A true long-horizon coding agent should be able to self-drive. This enables your agent to run at night—frequently capitalizing on off-peak API windows.
Log Spend per Feature: Start implementing visibility at the product level. When you log token costs per feature, high-agency engineers naturally gravitate toward optimizing their spend. You cannot change what you do not measure.
Approach Committed Use Carefully: Foundation model providers are pushing long-term spend commitments. Before signing away your opex, remember how fast this landscape shifts. The market leader today can be entirely leapfrogged tomorrow, and a rigid contract will prevent you from pivoting to better infrastructure.
The Don'ts
Don't Assign Cookie-Cutter Budgets by Role: Deciding that a "Senior Engineer gets $5,000 a month in tokens" ignores operational reality. It skews incentives. Engineers will either hoard budgets for fear of hitting a wall mid-sprint, or spend tokens carelessly just to exhaust their monthly allocation.
Don't Introduce Bureaucratic Approval Barriers: Adding complex justification forms or manual approval flows to token requests is a developer's nightmare. Top talent will simply look elsewhere for work. Budget guardrails should be managed systematically by the project sandbox, not through administrative overhead.
Don't Blindly Ban Premium Models: While you don't need a frontier model to write a basic script, blanket model-tier caps stifle innovation. Restricting your team entirely to lower-tier models prevents engineers from discovering advanced patterns, testing edge capabilities, and exploring the cutting edge.
Don't Gamify Token Spend via Leaderboards: Leaderboards were useful for driving initial internal adoption, but the long-term incentives are broken. Rewarding teams for raw output frequently leads to token waste. Instead, encourage developers to share their structural prompting techniques and architectural layouts. A great example of this is Shopify's internal tool, River, which utilizes public workspaces to mimic a traditional apprenticeship model where teams learn best practices by observing each other's interactions.
We are building predev with token efficiency as a core structural pillar. If you want to explore approaches to manage compute spend and start providing your engineers with a true self-driving coding agent, let's talk. @predotdev

86
Jun 10
Loop engineering is the current trend in AI development. But building longer loops inside a single generalized agent will eventually hit a logical bottleneck.
The natural progression is a harness of harnesses. Here is what that means:
Right now, coding agents are being treated as general-purpose agents. There is a practical reason for this: at a fundamental level, most digital workflows break down to file inputs, data transformations, and file outputs. Running programs is simply the most effective way to process structured data. It is exactly why teams are currently hacking tools like Claude Code and custom MCP skills to handle everything from UI design to go-to-market marketing strategies.
But using a heavy-duty software engineering agent for narrow, everyday tasks is a structural design flaw.
If you ask a general coding agent to check the weather, it shouldn't write a custom Python script, consume a public API, spin up a local runtime, and execute the code just to return a temperature. That is massive architectural bloat.
The future belongs to a meta-orchestration layer: a harness of harnesses.
Instead of forcing a single agent to adapt to every scenario, a meta-harness dynamically configures the optimal environment for the problem at hand:
The system assesses the high-level goal and spins up a temporary, highly constrained sandbox. It provisions only the exact tools and model tiers needed for that specific micro-task.
You are no longer just engineering the loop an agent implements to solve a problem. You are designing a specialized infrastructure around the problem to ensure maximum execution speed and cost efficiency.
We put this architectural theory into practice when building predev browser agents.
Instead of letting our core coding agent execute heavy web-browsing frameworks, we used predev to design a highly specialized, lightweight browser harness. Because it is built deterministically for narrow web actions, it runs significantly faster and at a fraction of the cost of market alternatives.
Within predev, these harnesses work in tandem. When the coding agent finishes building an application, it doesn't try to navigate the web directly. It dispatches the specialized browser agent to handle a narrow verification task—like testing whether a newly generated login form actually functions, or taking a screenshot of a page to programmatically verify that the UI matches the original stakeholder criteria.
The challenge isn't about building one massive agent loop that tries to do everything. It’s about building a stable orchestration layer that deploys the right harness for the right job, which then in turn implements a highly optimized loop.
Follow @predotdev for more updates on our native coding agent.
3
1
3
122
Jun 10
More on how we built predev Browser Agents.
x.com/predotdev/status/20545…
May 13

At predev a lot of our harness engineering effort goes into maximizing token runway.
But is the juice worth the squeeze? 👇
1
50
Jun 10
Clip from episode 7 of the predev podcast, the Artificial Intelli-Gents. Feat. @ArjunRajJain and @adampredev
x.com/predotdev/status/20615…
Jun 1
The Artificial Intelli-Gents Ep. 7: We Beat Claude Opus with a Smaller Model
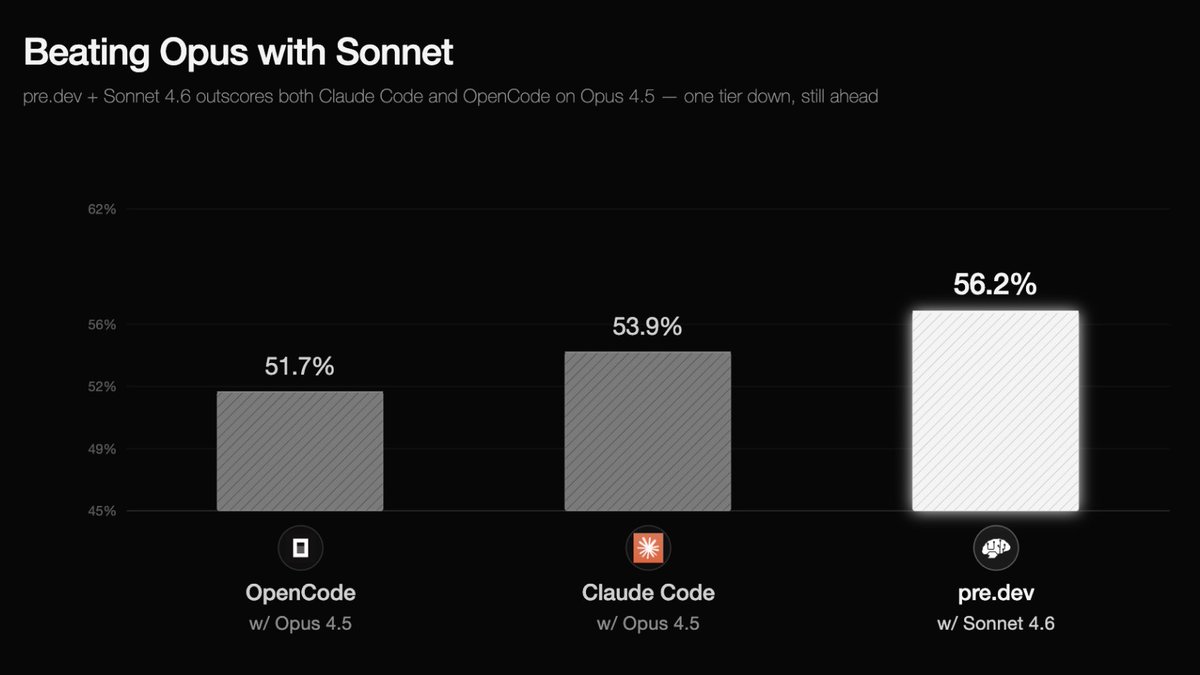
We did it: We dropped an entire model tier and still finished ahead. By proving that orchestration beats brute reasoning, our predev harness paired with Sonnet 4.6 (56.2%) officially beat Claude Code running Opus 4.5 (53.9%) on the grueling Terminal-Bench 2.0. The best part? We achieved higher accuracy while significantly cutting our per-task token bill.
Also in episode 7 of The Artificial Intelli-Gents, we dive into the current state of RLM, why "harness engineering" is the next frontier, and how to leverage forward-deployed engineers.
Timestamps:
2:28 - Why Terminal-Bench
9:33 - How we did it & what the results mean
18:05 - What makes our harness unique
27:00 - Building our own Browser Agents
34:35 - Implementing Recursive Language Models
41:20 - The future of benchmarks
51:00 - Forward Deployed Engineers & Dev Shops
1:04:00 - The harness of harnesses
1:17:37 - Upcoming Releases
@adampredev @ArjunRajJain
50
Jun 9
The race for recursive self-improvement is on. How we combined long-horizon planning with coding agents to outpace the biggest frontier labs in AI.
2
76
Jun 8
Have you spent the last few days thinking about how to move from writing prompts to designing loops?
To truly achieve long-running agents, you need a long-term execution graph. Here is how we do it:
Last month, we had a user run our coding agent for 60 hours straight. To sustain that scale, you have to solve two foundational challenges: memory compaction and predictive planning.
In last week's podcast, Arjun (@ArjunRajJain) and Adam (@adampredev) break down how they built the predev harness capable of handling tens of thousands of messages in a single session.
Recursive Memory Compaction:
Context stuffing or pollution occurs naturally if the agent simply keeps going, which warmth-seeks and inevitably causes drift. To maintain coherence over a 60-hour window, the agent shouldn't have to break the loop to summarize its history. It requires a memory layout that manages context dynamically without losing the core intent.
The Predictive Planning Layer:
To build a long-horizon agent loop, you must approximate the series of events before execution begins. By establishing a contract of milestones, user stories, and acceptance criteria up front, the harness translates a vague idea into a structural execution graph.
An additional benefit of knowing the full architectural scope ahead of time is efficient infrastructure management. Because the harness understands the roadmap before execution starts, the agent can configure its own isolated cloud sandboxes and route individual subtasks to the exact model tier that offers just the right performance for that specific action.
Oddly enough, the deeper you go into the long-term execution graph, the closer you get to traditional project management.
It turns out you manage coding agents the exact same way you manage a human engineering team. You break down complex goals into distinct user stories, estimate them, and design the system so the agents report back on their progress, upcoming subtasks, and impediments. Sound familiar?
The real engineering enabler isn't the underlying model. The magic lies in building a harness that can decompress a stakeholder's high-level request, map out the execution graph, and dispatch specialized agents with a shared, evolving memory.
If you want to see for yourself how to run your coding agents for 60 hours on autopilot, give predev a spin and explore our native agent right in your browser.
Link in the comments.
2
1
4
242
Jun 8
Full Podcast Episode of the Intelli-Gents
x.com/predotdev/status/20615…
Jun 1
The Artificial Intelli-Gents Ep. 7: We Beat Claude Opus with a Smaller Model
We did it: We dropped an entire model tier and still finished ahead. By proving that orchestration beats brute reasoning, our predev harness paired with Sonnet 4.6 (56.2%) officially beat Claude Code running Opus 4.5 (53.9%) on the grueling Terminal-Bench 2.0. The best part? We achieved higher accuracy while significantly cutting our per-task token bill.
Also in episode 7 of The Artificial Intelli-Gents, we dive into the current state of RLM, why "harness engineering" is the next frontier, and how to leverage forward-deployed engineers.
Timestamps:
2:28 - Why Terminal-Bench
9:33 - How we did it & what the results mean
18:05 - What makes our harness unique
27:00 - Building our own Browser Agents
34:35 - Implementing Recursive Language Models
41:20 - The future of benchmarks
51:00 - Forward Deployed Engineers & Dev Shops
1:04:00 - The harness of harnesses
1:17:37 - Upcoming Releases
@adampredev @ArjunRajJain
81
Jun 5
"It vibes on my machine." We’ve been here before.
The acceleration of AI coding agents has curiously resurfaced some familiar and frustrating challenges in professional software development.
If your engineers are walking around the office with their laptops open, babysitting their agents running loops inside a local terminal, you are heading toward a very predictable wall.
By executing agents locally, engineering teams are re-introducing classic infrastructure liabilities:
Context Pollution & Agent Drift: Local history and environments alter the agent’s behavior. The prompt templates and guardrails that cleanly run on one machine fail to replicate across the team, making harmonization and discipline impossible.
Local Harness Customizations: When developers hack local settings to force an agent to cooperate in a certain way, you lose a standardized, deterministic execution framework. Something you may have invested in heavily when onboarding coding agents for your organization.
Resource Exhaustion: Next-gen local harnesses eat memory like crazy. Running bloated agent loops on a local device inevitably leads to memory leaks and system crashes during long-duration tasks. Beefier machines and more RAM are not a permanent fix.
The solution to agent drift isn’t any different from how the industry solved the classic "it works on my machine" era a decade ago. You move the runtime off the local box.
We built predev to be entirely browser-native and cloud-sandboxed. No local setup, no local dependencies.
Because the runtime lives in isolated cloud infrastructure, the operational dynamic changes:
Persistent Execution: You can close your laptop without your agents going to sleep or dropping a thread. You can even check on your agents with your phone.
Isolated Sandboxing: Separating the agent from your local network and local file system isn't just a baseline security requirement. It allows the agent to run blind, reproducible verification loops to ensure acceptance criteria are met without environmental bias.
Predictive Resource Allocation: Because predev maps out the architecture and user stories before writing a single line of code, the system understands its upcoming constraints. The agent can autonomously configure its own isolated cloud resources, spinning up the exact sandbox environment and model tiers required for the specific task ahead.
Software orchestration belongs in a stable, standardized cloud runtime. Not crammed into a local terminal.
Below is a clip from our latest podcast episode, where Adam (@adampredev) and Arjun (@ArjunRajJain) reflect on the architecture of agent sandboxing and why local execution is a scaling liability.
2
1
3
311
Jun 4
On the latest episode of the Artificial Intelli-Gents Podcast, Adam (@adampredev) and Arjun (@ArjunRajJain) discuss the growing demand for forward-deployed engineers as AI-native startups rapidly ship new products and post tremendous ARR growth.
Our partnership with Pangea (@pangea_ai) allows founders building with predev to access top-tier, hands-on tech talent to help navigate their GTM growth, all while orchestrating their product roadmap through our architecture-first coding agent.
Jun 4
Going from $0 to $1M ARR is easier, and faster, than ever.
What happens to your MVP as you try to scale from $1M to $10M ARR is where the reality check hits.
Coding agents are incredible for getting a prototype in front of users and driving early revenue. But viably translating tokens into stable production code is only half the equation.
This is exactly where most startups lose their momentum.
A codebase, even an agent generated one, still requires real-world maintenance, bug fixes, infrastructure scaling, and dependency updates. Eventually, you hit a tipping point where a founder CEO has to stop hacking the product and start focusing entirely on customers.
When you hit that milestone, the technical challenge shifts:
Adoption Bottlenecks: If your production environment can't scale seamlessly with your new users, they simply cannot adopt the product.
Product Decay: When customer feedback isn't fed back into a continuous loop, the business suffers. Letters of Intent turn into cold leads, and key feature commitments get delayed.
The Enterprise Wall: You cannot expand into enterprise relationships if you lack watertight security infrastructure, or if you are still personally stuck prompting your coding agent.
This tipping point is one of the most critical structural challenges we see our customers face when hitting their initial ARR milestones.
It is also why we have continuously evolved our partnership with Pangea AI.
This collaboration allows our customers to quickly deploy fractional CTOs and forward-deployed engineers to step in and manage technical execution.
What makes this approach different is that they don't throw away what you've already built. They take the wheel of your existing predev infrastructure. These hands-on experts manage your long-term product roadmaps and scale your system architecture, maintaining the exact transparency and token efficiency you've grown used to, all while bringing the real-world operational experience needed to scale.
You focus on growing the business and obtaining customer insights. The engineering team translates those insights into a compounding product cycle.
If your startup is navigating the $1M to $10M ARR chasm, our @predotdev @pangea_ai solutions can help you maintain that critical momentum.
Head over to our website to learn more. Link below.
2
2
238
Jun 4
Full Episode. Intelli-Gents: We Beat Claude Opus with a Smaller Model
x.com/predotdev/status/20615…
Jun 1
The Artificial Intelli-Gents Ep. 7: We Beat Claude Opus with a Smaller Model
We did it: We dropped an entire model tier and still finished ahead. By proving that orchestration beats brute reasoning, our predev harness paired with Sonnet 4.6 (56.2%) officially beat Claude Code running Opus 4.5 (53.9%) on the grueling Terminal-Bench 2.0. The best part? We achieved higher accuracy while significantly cutting our per-task token bill.
Also in episode 7 of The Artificial Intelli-Gents, we dive into the current state of RLM, why "harness engineering" is the next frontier, and how to leverage forward-deployed engineers.
Timestamps:
2:28 - Why Terminal-Bench
9:33 - How we did it & what the results mean
18:05 - What makes our harness unique
27:00 - Building our own Browser Agents
34:35 - Implementing Recursive Language Models
41:20 - The future of benchmarks
51:00 - Forward Deployed Engineers & Dev Shops
1:04:00 - The harness of harnesses
1:17:37 - Upcoming Releases
@adampredev @ArjunRajJain
107
Jun 3
🃏
Jun 3
Coding with AI feels a lot like poker: I have to wager tokens with high variance on whether the solution is legitimate, while balancing the possibility that the opponent (the agent) is bluffing me. I have imperfect information because I can't account for every single bash command and line of code, while having to make live reads on if the agent's information is accurate.
131
Jun 3
How do you compete in the AI coding game against giants like Anthropic and OpenAI?
You don't outspend them. You out-engineer their harnesses.
"The harness matters. Especially when it comes to cost efficiency and token usage. If you can get both an intelligence gain and a cost gain, then that’s really how you're chasing the edge in this coding game.”
We break down how we just broke the model cost continuum.
1. On off-the-shelf SDKs:
"We hand-built this harness because we tried the Claude Code SDK and the Open Code SDK. They both had gaping leaks."
2. On picking a benchmark that actually mirrors real engineering:
"You have two types of benchmarks. Some just introduce isolated patches, but they aren't really multi-agent turn. We picked Terminal Bench because it tests multi-file, multi-turn execution right in the terminal."
3. On the results that broke the cost curve:
"Our Haiku scored higher than Sonnet 4.5 on the leaderboard. We did about 16% better than Claude Code on Haiku. That’s a three times cost difference, and we somehow jumped that."
4. On the core thesis of next-gen software engineering:
"The harness matters. Especially when it comes to cost efficiency and token usage. If you can get both an intelligence gain and a cost gain, then that’s really how you're chasing the edge in this coding game."
May 19
If you have been using Claude Code professionally, take a minute to read this.
We beat Opus with Sonnet by using the predev harness. Here is what it means for agentic coding:
Orchestration beats brute reasoning. A smaller model running on our architecture just beat Claude Opus on Terminal-Bench 2.0.
For the last two years, the default way to improve an AI coding agent has been simple: throw more money at the model. Upgrade the tier, burn more tokens, buy a bigger context window, and hope for better code.
But a model's raw weights matter far less than the system architecture wrapping it.
Seeing a clear ROI on every shipped feature has a direct impact on the success of your business. So does spending 50% more tokens per feature.
We wanted to prove that a smarter harness could break the trend of relying on brute compute. So we put it to the test on Terminal-Bench 2.0.
We ran predev Sonnet 4.6 on the Harbor reference harness against the Terminal-Bench 2.0 task set. The Claude Code numbers were taken directly from their public submissions on tbench.
The final result: predev Sonnet 4.6 scored a 56.2% pass rate. Claude Code running the massive Opus 4.5 scored 53.9%.
We dropped an entire model tier and finished ahead. Accuracy went up, while the per-task model bill went down.
We didn't close that performance gap by paying for a premium model; we did it by spending tokens more efficiently. Buying a bigger model just trades dollars for points. A better harness gets the points without making that trade.
Frontier labs build mass-market engines. They cannot highly specialize their layer for deep engineering tasks. It is exactly like a database program—the engine doesn't tell you how to organize your application data.
We built our harness narrowly and explicitly to solve complex, production-ready systems engineering. The core architecture rests on three uncompromising loops:
It plans before it codes. The agent extracts a structured blueprint with milestones before a single file is touched.
It uses dynamic execution paths. Leveraging ToDo dependency graphs and parallel analysis.
It verifies before passing. A blind verifier re-runs acceptance criteria against the output and disagrees freely.
You don't need to be a frontier lab to beat one. You just need a system engineered for the actual work.
We built predev for real, live use cases and customers.
predev customers include software development agencies building products for clients, software vendors building proofs-of-concept for their prospects, enterprise teams building internal data pipelines, and startups getting their MVP out on time and on budget.
If ROI matters to your business, stop burning tokens on brute force. Head over to predev, run your project through our harness—be it an existing codebase or greenfield—and watch us ship.
The open-sourced Harbor trajectories and repository are live on GitHub. The full breakdown of the results is live on our website.
(Links to both in the comments).
3
3
5
538
Jun 3
Full Episode:
x.com/predotdev/status/20615…
Jun 1
The Artificial Intelli-Gents Ep. 7: We Beat Claude Opus with a Smaller Model
We did it: We dropped an entire model tier and still finished ahead. By proving that orchestration beats brute reasoning, our predev harness paired with Sonnet 4.6 (56.2%) officially beat Claude Code running Opus 4.5 (53.9%) on the grueling Terminal-Bench 2.0. The best part? We achieved higher accuracy while significantly cutting our per-task token bill.
Also in episode 7 of The Artificial Intelli-Gents, we dive into the current state of RLM, why "harness engineering" is the next frontier, and how to leverage forward-deployed engineers.
Timestamps:
2:28 - Why Terminal-Bench
9:33 - How we did it & what the results mean
18:05 - What makes our harness unique
27:00 - Building our own Browser Agents
34:35 - Implementing Recursive Language Models
41:20 - The future of benchmarks
51:00 - Forward Deployed Engineers & Dev Shops
1:04:00 - The harness of harnesses
1:17:37 - Upcoming Releases
@adampredev @ArjunRajJain
85
Jun 2
instead of a tokenmaxxing leader board for devs we should have a leader board for enterprises wdyt?
May 28
Uber spent its entire annual AI budget in one quarter. The creator of Openclaw burns $1M a month on Codex tokens.
What is the true ROI on AI token spend? Here is how we measure and increase it.
When Fortune 100 CFOs question tokenmaxxing and Microsoft cancels Claude subscriptions, it points to an underlying issue.
Our engineering patterns are evolving for raw output, not efficiency: the illusion of free code.
Because a developer doesn’t see a cash meter running while typing prompts, writing code suddenly feels free.
So we run three agents in parallel just to pick the fastest output, or throw Opus at a basic typo because it's easier than switching models.
No one wants to touch code they didn't write, so they just use AI. It becomes a compounding cycle.
But when code feels free, foundational engineering discipline erodes.
Vague, one-sentence prompts replace rigorous user stories. The ergonomics have changed; no one wants to jump into Jira anymore.
They go straight to the terminal, letting the agent make an educated guess. If it's off, they just start over, it’s faster than writing extensive briefs.
We end up with an explosion of output: a mountain of code generated by a mountain of tokens. But how much actually makes it to production?
Did we build an overly complex solution to a simple problem just because compute allowed it? We accelerated output, but didn't increase productivity.
We ran a dev shop for years. When clients pay for shipped product rather than raw hours, ROI is your entire business.
Scarcity breeds process innovation. True efficiency doesn't happen while the agent is typing. It happens before a single line of code is written.
We baked those exact operational mechanics directly into the predev. We pre-dev before we build.
It enforces planning. Tasks break down with an estimation directly inside your workflow, syncing with Jira to eliminate context switching.
It selects the right tool. With proper briefing, the harness chooses the optimal model tier. For a basic button component, you don't need premium reasoning.
It leverages recursive long-term memory. Like a veteran engineer who knows a codebase's quirks, predev builds a compounding memory of common bugs, libraries, and tooling issues with every task.
It blind-verifies everything. It runs strict acceptance criteria against the output to kill false positives before they ever pollute your repository.
The result is total visibility over engineering margins. Every credit spent is traceable down to an exact user story, subtask, and pull request.
You can finally make intelligent spend decisions based on actual business value, rather than letting unconstrained agents run wild on your corporate credit card.
The point is you finally have control. You can make a calculated spend decision based on the exact value of a task, all while remaining highly efficient.
If you are ready to optimize your engineering ROI, head over to predev to book a demo.
ALT news articles mentioning at token spending
96
Jun 2
Can a custom software harness make a low-tier model outperform a premium frontier model that costs three times as much?
Most enterprise teams are facing skyrocketing token bills because they think raw capital is the only path to intelligence.
On the latest episode of the Artificial Intelli-Gents Podcast, predev co-founders Adam and Arjun break down exactly why the industry has hit a model cost wall.
Instead of waiting for updates from foundational labs, Adam Elkassas (@adampredev) and Arjun Raj Jain (@ArjunRajJain) hand-built a native cloud harness from scratch to fix the severe memory leaks and structural shortcuts found in standard SDKs.
They ran their system against Terminal Bench, the most rigorous multi-file coding benchmark in the industry. The results broke the standard model cost continuum:
Running on a low-cost tier like Claude Sonnet, predev’s native harness outperformed Anthropic’s own Claude Code running on premium Opus 4.5.
How do you manufacture that kind of lopsided intelligence gain while cutting token costs by two-thirds?
Here is a breakdown of the episode and how they out-architected foundational labs valued at hundreds of billions:
- Why Terminal-Bench: The truth about why standard benchmarks fail to test true, multi-turn agent capability in the wild.
- Breaking the Cost Continuum: The exact mechanics of how predev helps users maximize intelligence per token without breaking the bank.
- What Makes Our Harness Unique: Moving past simple for-loops into long-horizon planning layers and long-term execution graphs.
- Building Custom Browser Agents: How Arjun built a specialized browser agent layer that runs at 3x the speed and 1/3 the cost of market alternatives.
- Implementing Production RLM: The blueprint behind being the first team to truly implement Recursive Language Models to achieve unlimited execution depth.
- The Reality of Enterprise AI: Why raw agents fail out of the box in production, and how forward-deployed engineers scale MVPs to enterprise security standards.
- Upcoming Releases: A sneak peek into predev's next-gen CLI release, local-to-cloud syncing, and multi-session isolated sandboxes.
While frontier labs pour tens of billions into physical data centers, the real software alpha is being captured at the orchestration layer.
If you want to see how architectural execution beats raw compute capital, this episode is your blueprint.
Full episode in the quoted post below.
Jun 1
The Artificial Intelli-Gents Ep. 7: We Beat Claude Opus with a Smaller Model
We did it: We dropped an entire model tier and still finished ahead. By proving that orchestration beats brute reasoning, our predev harness paired with Sonnet 4.6 (56.2%) officially beat Claude Code running Opus 4.5 (53.9%) on the grueling Terminal-Bench 2.0. The best part? We achieved higher accuracy while significantly cutting our per-task token bill.
Also in episode 7 of The Artificial Intelli-Gents, we dive into the current state of RLM, why "harness engineering" is the next frontier, and how to leverage forward-deployed engineers.
Timestamps:
2:28 - Why Terminal-Bench
9:33 - How we did it & what the results mean
18:05 - What makes our harness unique
27:00 - Building our own Browser Agents
34:35 - Implementing Recursive Language Models
41:20 - The future of benchmarks
51:00 - Forward Deployed Engineers & Dev Shops
1:04:00 - The harness of harnesses
1:17:37 - Upcoming Releases
@adampredev @ArjunRajJain
1
1
190
pre.dev retweeted
Jun 2
Harness “engineering” is a combination of research and engineering. It takes both
1
65