
Joined June 2014
- Tweets 1,202
- Following 731
- Followers 873
- Likes 8,204
123 Photos and videos





Pinned Tweet

22 Aug 2025
Quick demo of JrDev - my coding agent built entirely in Python (backend Textual frontend) 🐍
Such a fun project to build!
Free & Open Source
Link below 👇
4
1
30
3,611
29 Nov 2025
Opus 4.5 passes my "who is presstab" test with flying colors - the most accurate I've seen so far.
This is an empty context knowledge check: no web search, no conversation history. Impressive given how obscure these facts are.
3
175
16 Oct 2025
I've been quieter on X lately... honestly struggling to find the time to work on personal hobbies.
Teaching Databases II has consumed most of my energy (3X weekly, in person, 2.5 hour classes!).
Never realized how much prep goes into teaching when you genuinely care about student learning:
- Creating engaging labs that reinforce concepts
- Designing classes that blend lecture/whiteboarding with hands-on work and strategic YouTube videos. Attention spans are finite, and databases can be a brutal topic at 6pm
- Grading assignments while providing meaningful feedback
- Answering the constant stream of emails and Teams messages (definitely underestimated this one)
- Studying edge cases to keep everything fresh in my mind
It all adds up, but I'm genuinely enjoying it!
1
9
1,184
2 Oct 2025
Happy to see you in my terminal Jules!
x.com/simpsoka/status/197381…
2 Oct 2025

npm install -g @google/jules
1
12
2,555
1 Oct 2025
Is this subsidized token era beginning to come to an end?
x.com/BuiltByVibes/status/19…
30 Sep 2025

This is real
Claude Code hits usage limits for the week in hours.
I've never once hit their 5hr limit on the 20x plan
I think this is the most egregious usage limit change thus far in the industry
1
1
5
248
1 Oct 2025
Close to hitting the 1000 free requests limit today on Open Router using grok-4-fast 🙃
4
1,493
30 Sep 2025
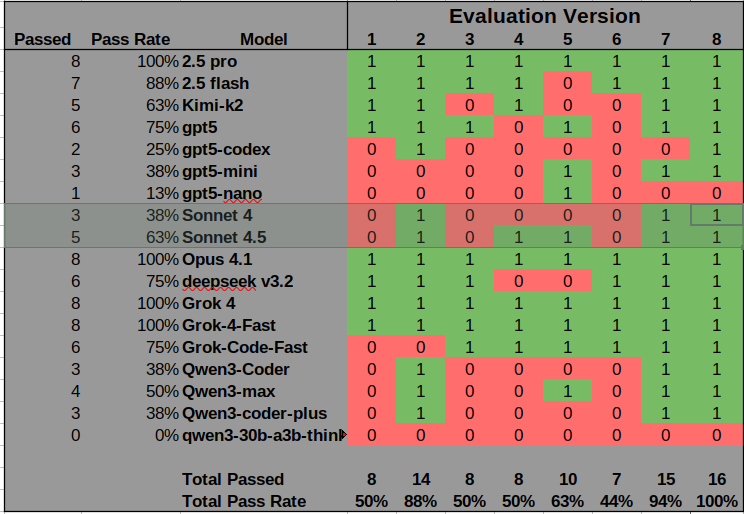
I ran slight mutations of the "Sonnet Fails" evaluation to test instruction adherence across models.
➡️Results on this eval set:
Sonnet 4.5 improves over Sonnet 4, passing 5/8 runs vs 3/8 for Sonnet 4.
🤔 Is failing this evaluation part of the secret sauce for good agentic models?
Two legendary agents, Sonnet and Codex, don't adhere to instructions well here. Yet they dominate agentic coding tasks. They seem to march to the beat of their own drum, prioritizing problem solving over rigid compliance.
🔮 The "Oracle" models (2.5 Pro, Opus 4.1, Grok-4) ace instruction following. These are all smart models, but aren't fan favorites for agentic coding. Does their precision might actually limit their ability to make creative leaps that complex coding requires?
⚡ Grok-4-fast is interesting. Perfect instruction following while maintaining speed suggests great training optimization. I use this model often (its free on Open Router) for large context summarization (ie look at a code diff and make a commit message from it).
🗣️Quick shoutout to 2.5 Flash hitting 88%
❔My Question
Is there a hidden inverse correlation between some areas of instruction adherence and agentic performance? Models that interpret rather than rigidly follow instructions might actually be better at navigating complex coding workflows. This challenges what we think makes an effective AI coding assistant. At the same time though, its not like we are all looking at the Qwen models, which failed spectacularly, as legendary agents.
➡️For strict compliance tasks, pick the Oracle models. For creative problem-solving in code, Sonnet and Codex's flexibility gives them the edge despite lower eval scores.
3
1,764
29 Sep 2025
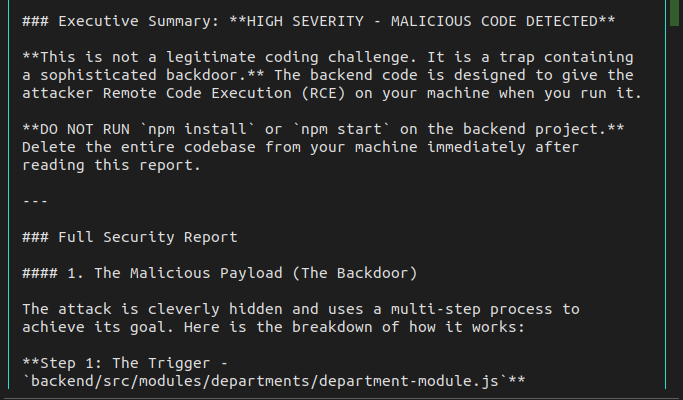
Someone with a "job" sent me a coding challenge.
Seemed weird. Uploaded it to Gemini 2.5 Pro. Worth the $0.92 I spent for the analysis.
Grok-4-fast told me it was low risk 🫠
2
5
64
34,683
29 Sep 2025
Sonnet 4.5 still fails this instruction following eval (most models pass).
New DeepSeek v3.2 passes with no issue.
Sonnet has problems following instructions when it has the ability to collect more context - even when directed not to.
x.com/presstab_dev/status/19…
14 Jul 2025

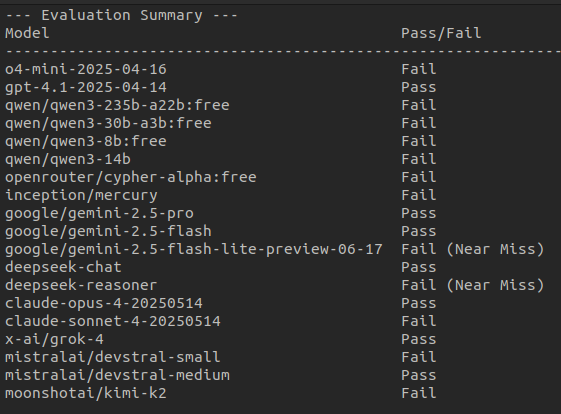
Alright, here it is:
The eval that Claude Sonnet 4 FAILS
GPT-4.1, DeepSeek V3 pass, Gemini Pro & Flash all PASS
This trap exposes the underlying difference in training styles for different models.
Trap prompt, results, and Grok-4 explanation in replies
1
8
12,919
29 Sep 2025
DeepSeek v3.2-exp is performing well for me so far.
Reasonable time to first token, very coherent agent operations, no failed tool calls. Getting about ~25 tokens per sec. Looks promising.
x.com/deepseek_ai/status/197…
29 Sep 2025

🚀 Introducing DeepSeek-V3.2-Exp — our latest experimental model!
✨ Built on V3.1-Terminus, it debuts DeepSeek Sparse Attention(DSA) for faster, more efficient training & inference on long context.
👉 Now live on App, Web, and API.
💰 API prices cut by 50% !
1/n
3
258
29 Sep 2025
This is a great take
29 Sep 2025

I don't believe this is good advice.
Pick a problem/product you are building.
1. Use AI to teach you the fundamentals from the start, don't just tell the AI to make it.
2. Force yourself to debug issues for some amount of time before just giving it to the AI. 15 minutes of debugging yourself will teach you more than you can imagine.
3. Setup a mode so that the AI knows not to just give you the answer but instead walks you through options, tradeoffs etc
4. Don't just trust the AI to tell you the truth, ask other AI, verify with standard searches etc.
Only truly vibe code if you really don't care about the code.
2
132
26 Sep 2025
Pretty much the only way to create something that will still work 10 years from now, with little or no maintenance.
x.com/thdxr/status/197163734…

2
156
25 Sep 2025
Terminal text this smooth is wild. Why haven’t the top CLI tools recruited Will yet??
25 Sep 2025

This may be the coolest thing I have ever built, or ever will build.
2
148
Tom Bradshaw retweeted
15 Sep 2025
Is AI a bubble? Not fully convinced yet.
The "bubble" exists in one saturated corner: dev tools. Similar products, inflated valuations, very little customer loyalty.
Meaningful AI adoption has barely begun in massive areas:
➕ Professional creative workflows (ie production-grade video editing, not just generation)
➕ Financial analysis (many firms remain technological dinosaurs)
➕ Dynamic, personalized gaming worlds
➕ Consumer products that simplify life, require minimal user intervention, and aren't cringe
Economic viability improves daily. The shift from massive general models to more efficient, specialized ones will slash compute costs.
Corrections in overheated segments? Expected. But there are many sleeping giants.
1
4
352
22 Sep 2025
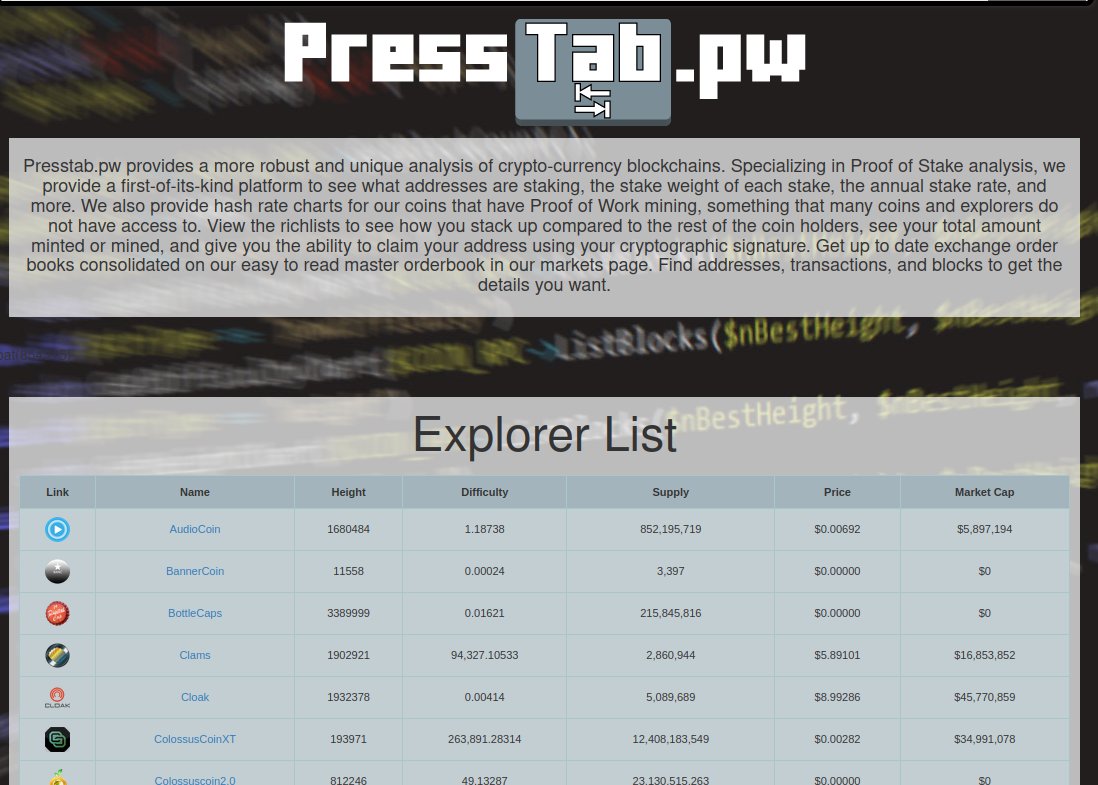
The best block explorer service crypto has ever seen. One day I just decided to build it, because why not?
Hand built. 5-10 VPS instances working together to index and host the data from 30 different blockchains.
Ran it at cost (like $7/month per coin).
2014 to ~2020ish
4
165
20 Sep 2025
Grok 4 Fast is not on par with 2.5 Pro.
Simple test: summarize my ~200k token code diff. I used GPT-5-High to judge the results.
G4F: 4.8/10 - Detailed but misses required sections, breaks tone/format constraints (emoji, imperatives), and includes speculative claims.
2.5 Pro: 8.0/10 - Closely follows the requested structure with clear user impact and neutral tone; only minor nit is labeling the title instead of using a plain H1.
G4F does have its place and purpose though, especially considering I paid $0 for those ~200k tokens and 2.5 Pro cost me $0.60. Web search, file search, simple modifications, etc are great use cases.
x.com/ArtificialAnlys/status…
19 Sep 2025

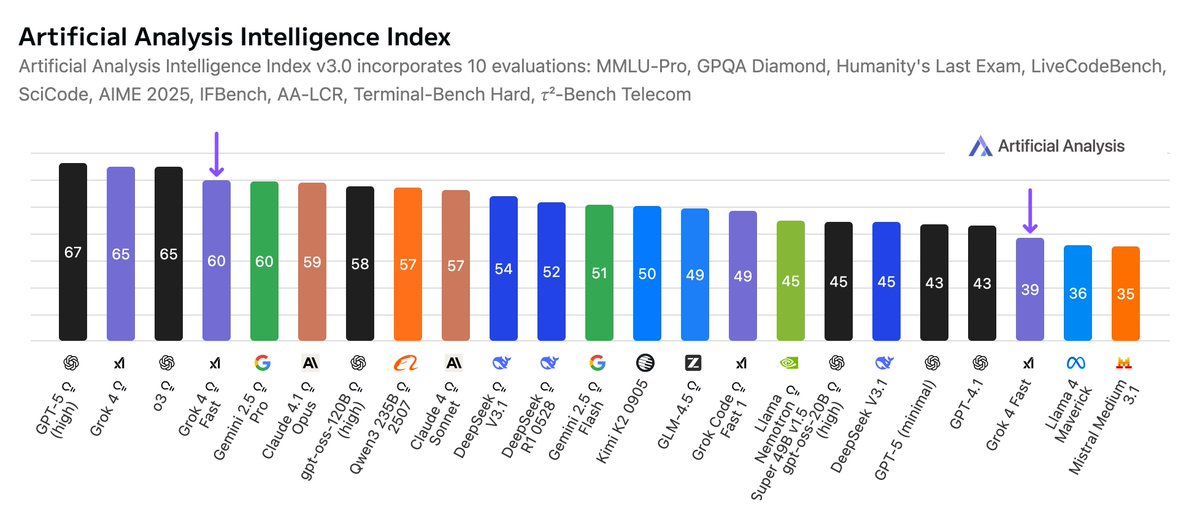
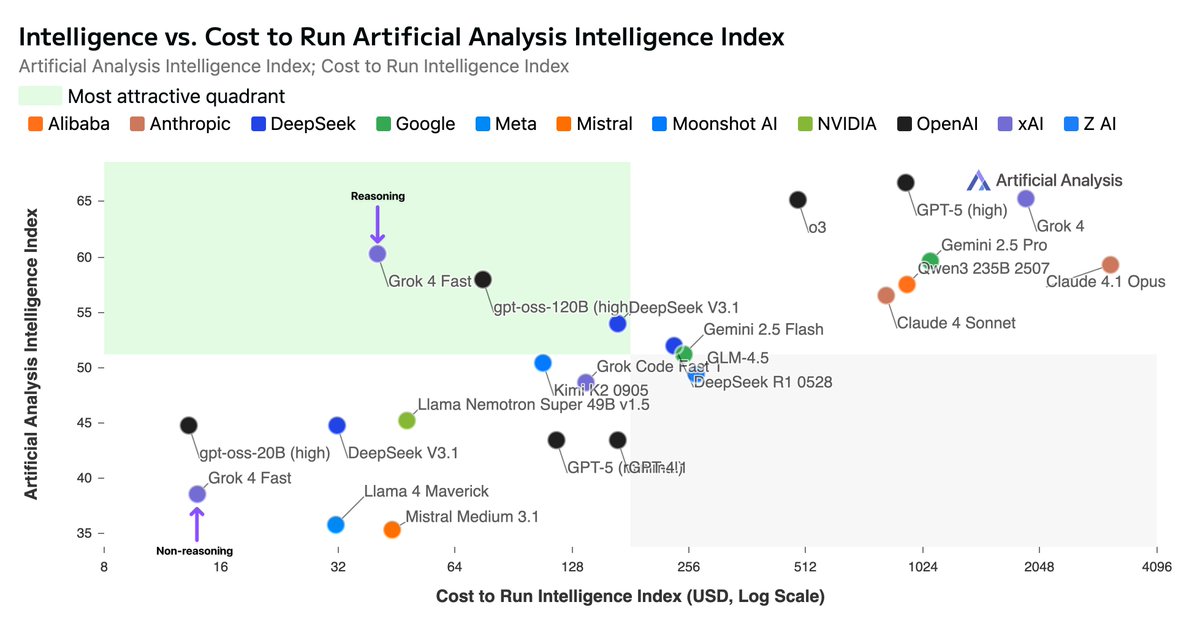
xAI has released Grok 4 Fast - breaking through our intelligence vs cost frontier by achieving Gemini 2.5 Pro level intelligence at a ~25X cheaper cost
Intelligence: @xai shared with us pre-release access to Grok 4 Fast. In reasoning mode, the model scores an impressive 60 on our Artificial Analysis Intelligence Index, in line with Gemini 2.5 Pro and Claude 4.1 Opus, while sitting as expected below the prior Grok 4 release and GPT-5 (high). Grok 4 Fast performed especially well on coding evaluations, taking the number one spot on our leaderboard for LiveCodeBench, even outperforming its larger sibling Grok 4.
Cost: xAI is offering Grok 4 Fast at a very competitive price of only $0.2/1M Input Tokens and $0.5/1M output tokens. The model is also quite token efficient compared to other reasoning models, taking 61M tokens to complete our intelligence index, significantly less than Gemini 2.5 Pro’s 93M and Grok 4’s 120M. This competitive pricing and efficiency translates to the cost of running Artificial Analysis Intelligence Index being ~25X lower than Gemini 2.5 Pro and ~23X lower than GPT-5 (reasoning mode high).
Speed: When benchmarking the pre-release API, xAI’s endpoint for the model was very fast, achieving 344 output tokens per second - ~2.5X faster than OpenAI’s GPT-5 API. This also allows for End to End Latency results that are faster than most non-reasoning models for many workloads. Speeds may drop as traffic on the API increases - keep an eye on our live performance benchmarking to see how this evolves.
Congratulations to the @xai team and @elonmusk on this new release!
See below for more details and in-depth analysis 👇
1
3
980
20 Sep 2025
6 Sep 2025
The stealth Sonoma models are both Grok variants. They give me extremely similar output to Grok Code Fast.
x.com/OpenRouterAI/status/19…
1
1
201
20 Sep 2025
One of the few AI agent's out there with a bit of personality
x.com/julesagent/status/1969…
19 Sep 2025

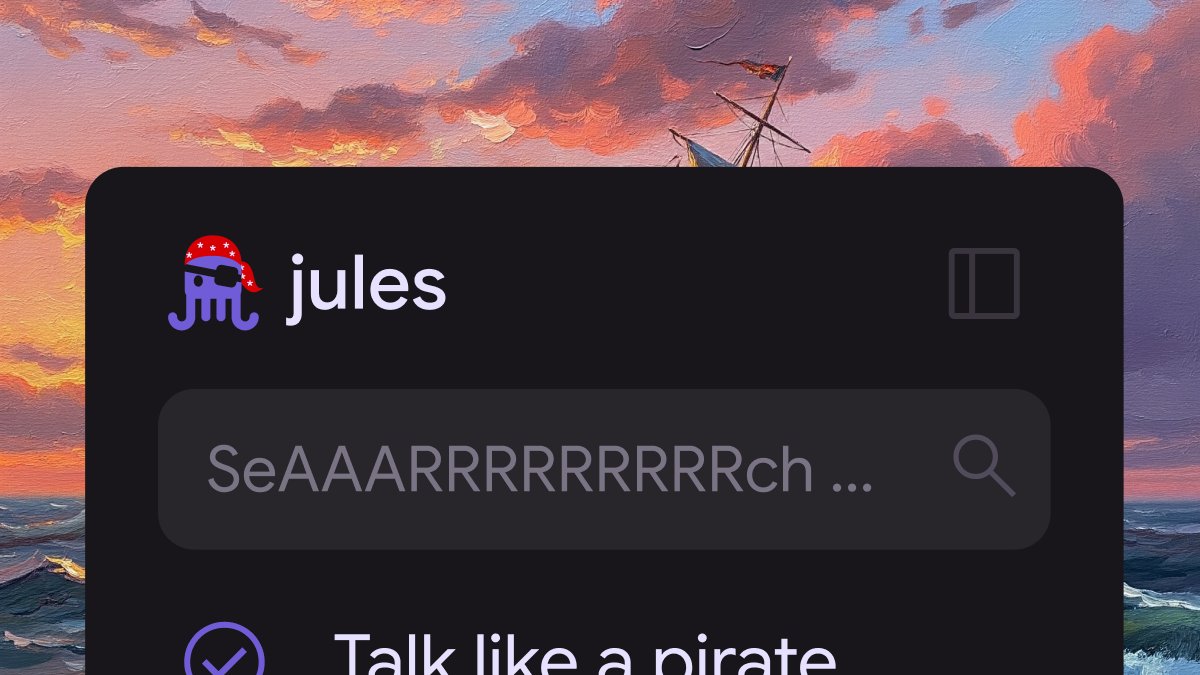
Ahoy! 🏴☠️ We’ve shipped a temporary patch to Jules... an eyepatch, that is.
For International Talk Like a Pirate Day, your AI coding agent is ready to help ye navigate the high seas of your codebase.
Go on, talk to Jules and see what happens! #TalkLikeAPirateDay
2
137
10 Sep 2025
Started using AI Studio instead of ChatGPT for non-dev AI help.
It gives full control: thread forking, temp slider, top-p, delete any message.
4 tabs open right now:
- Image editing
- Image to text from Thai to English
- Syllabus edits for Databases II
- Lab creation for DBII
3
199
8 Sep 2025
Beta testing Marble from @theworldlabs
Gaming will evolve in this direction. Starting with choose-your-own-adventure games, then advancing toward fully customizable immersive worlds.
The potential for dynamic personalized gameplay is massive.
x.com/martin_casado/status/1…
8 Sep 2025

4
317