
Scientist @genbioai | PhD @CMUCompBio | Creator/maintainer contextualized.ml | multi-task learning, graphical models, and personalized medicine
Joined December 2017
- Tweets 605
- Following 378
- Followers 871
- Likes 1,657
Photos and videos
Pinned Tweet

27 May 2025
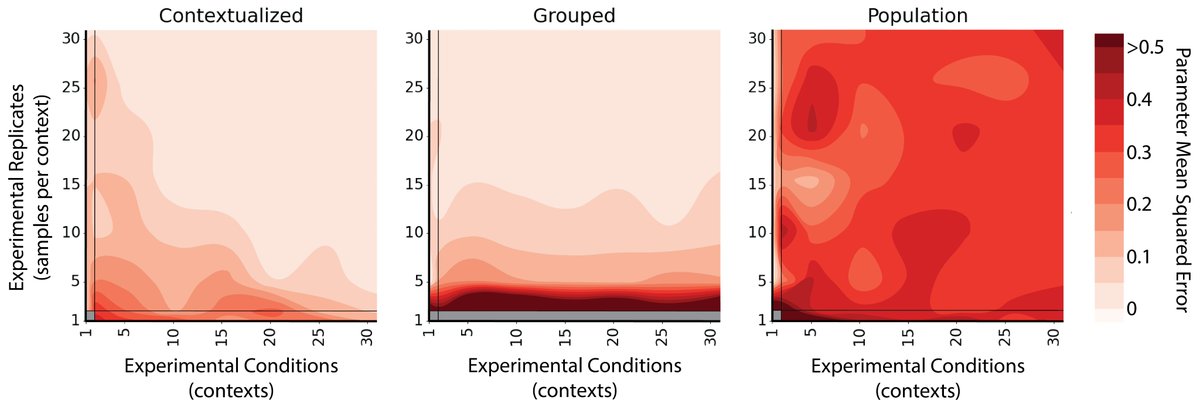
Honored to share a major thread of my PhD research, out now in PNAS. We address a core issue with how models are used for scientific discovery.
Models are so important that they define the entire scientific process... 1/n
8
46
317
61,703
Caleb Ellington retweeted

Jun 11
Together with UC Berkeley we are announcing the laser phase plate - a breakthrough in atomic resolution imaging. This is the brightest continuous wave laser in the world, 100 million times the intensity of the surface of the sun.
Phase contrast plays an important role in microscopy, but it was thought close to impossible for electron microscopy, where it would require interfering with an electron beam. Holger Mueller and Robert Glaeser proposed exactly this using a standing wave laser. It has taken over 15 years to make this a reality. Biohub partnered with UC Berkeley and Mueller to support this work and to engineer and build the technology.
Contrast has been the critical barrier to achieving atomic resolution imaging of the cell. In cryo-electron tomography, a cellular imaging technology that uses electron microscopy, the low contrast makes it impossible to resolve anything but the largest proteins within their cellular context. The laser phase plate removes that barrier.
With advances in AI this breakthrough in contrast will start to open up a new frontier in structural biology, that will allow us to see the molecular machines of the cell, and how they assemble into far more complex and dynamic systems, and understand how they work.
85
523
3,654
562,107
Caleb Ellington retweeted

May 29
We built a joint experimental and computational platform for scalable multi-modal single-cell chemical screens — profiling RNA, protein (including phospho-signaling), and chromatin accessibility responses to thousands of small molecule perturbations in parallel. biorxiv.org/content/10.64898…

2
40
180
13,657
May 28
Before we put this study online, we reproduced it from scratch 3 times with Claude Code and Codex. It took about 6-8 hours each time. There's a higher bar for scientific rigor and reproducibility when you want work to be built on by both human and agent scientists.
May 14

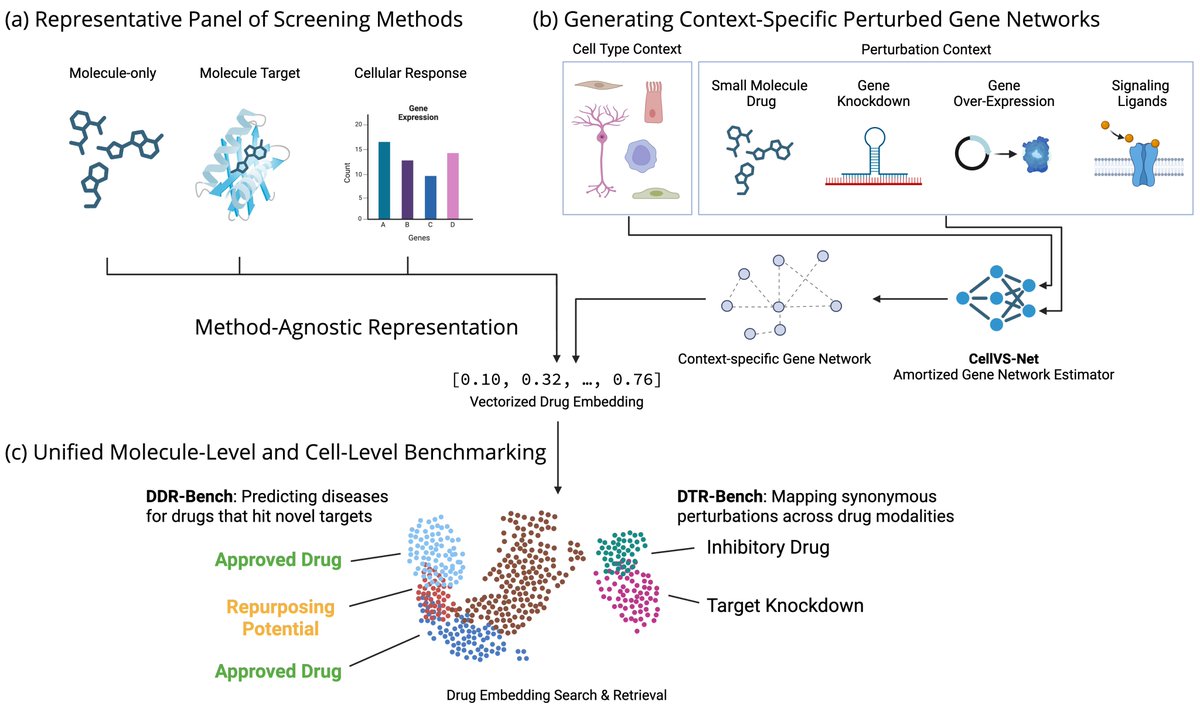
Virtual cells are supposed to help drug discovery. Why aren't they evaluated on drug discovery tasks? In our new preprint "Cell-Level Virtual Screening," we investigate this and other fundamental questions about practical applications of virtual cells for drug discovery.
2
9
63
10,179
May 28
We also repurposed our agents as very attentive peer reviewers to try reproducing our hand-made results from scratch, and kept updating our manuscript until we ironed out all documentation issues. This should be the standard for reproducibility in all information sciences today.
1
118
May 28
Like with cybersecurity, I expect the offense is only temporarily at an advantage in science, but ultimately defense will win out with automated peer review like this. I am excited for science to become more and more trustworthy when any paper can be reproduced on-demand.
112
Caleb Ellington retweeted

May 22
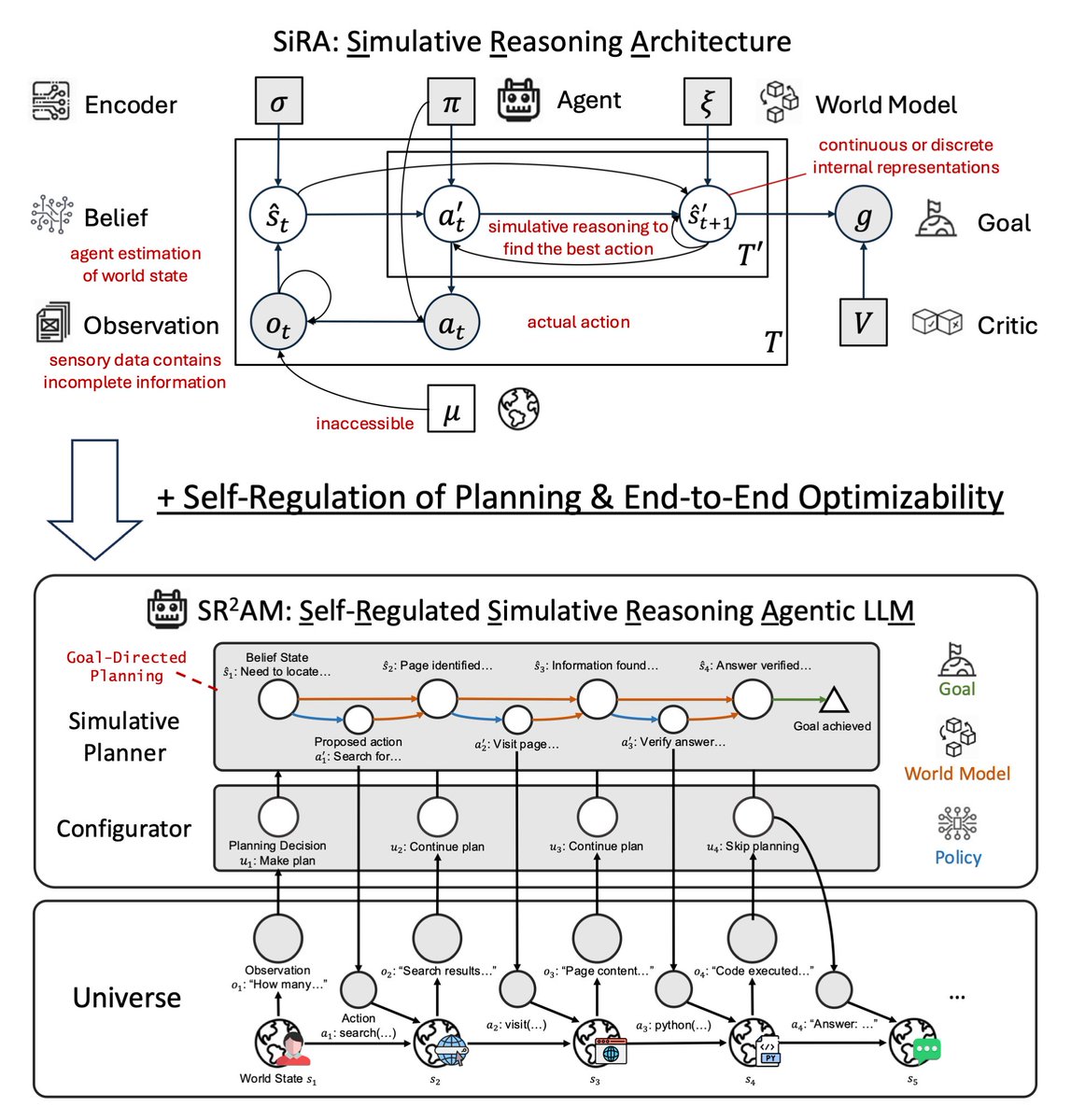
Frontier LLMs are converging on efficient, adaptive reasoning. Opus 4.7 lets the model decide how deeply to reason. GPT-5.5 achieves strong results with fewer reasoning tokens.
We study a related but more structural question: what 𝗸𝗶𝗻𝗱 𝗼𝗳 𝗿𝗲𝗮𝘀𝗼𝗻𝗶𝗻𝗴 should we adapt?
Last year in SiRA (upper figure), we showed that simulative reasoning (System II), which uses a 𝘄𝗼𝗿𝗹𝗱 𝗺𝗼𝗱𝗲𝗹 to evaluate consequences of actions, yields up to 124% improvement over reactive baselines (System I), and that strong reasoning models (o1, o3-mini) fail as planners without this structure.
In our new paper SR²AM (lower figure), we add a learned 𝗰𝗼𝗻𝗳𝗶𝗴𝘂𝗿𝗮𝘁𝗼𝗿 (System III) that self-regulates when to simulate, how far ahead, and when to skip planning entirely.
Efficient reasoning is not just shorter reasoning: it is better allocation of simulation.
4
47
279
61,576

LLM training is built on fast MatMuls. But many surrounding ops still run as memory-bound kernels.
CODA reparameterizes them to hide in the matmul’s shadow, fused into its epilogue before results leave the chip.
Bonus: LLMs can write fast CODA kernels too (approaching SoLs).

15
103
685
197,785
Caleb Ellington retweeted

May 14
Last month, we shared research on why LLMs fail at data analysis: even the best models hallucinate answers when reasoning over structured data.
Today we're launching what we've built to fix it.
Summand is now live at summand.com.
What most teams want is simple: plug AI into their data and get answers they trust. Most "chat with your data" tools try to deliver that by translating your question into SQL and hoping for the best. Summand does something harder: it builds up a real understanding of your data. What your columns actually mean, how your tables relate, where the edge cases live. You can contribute to that understanding too, and so can the agent.
Under the hood, that understanding is grounded in interpretable ML and a semantic layer purpose-built for structured data. That's what makes the answers trustworthy.
Why the name “Summand”? Just like how a summand is a term in a summation, Summand decomposes your data into interpretable reasoning components. By breaking complicated outcomes into simple patterns, Summand makes downstream AI systems reliable and transparent.
*What this means to you:* Connect your data to Summand.com, start asking questions immediately, and power your downstream AI applications through Summand’s MCP access.
Try it today → summand.com
2
7
529
May 14
Virtual cells are supposed to help drug discovery. Why aren't they evaluated on drug discovery tasks? In our new preprint "Cell-Level Virtual Screening," we investigate this and other fundamental questions about practical applications of virtual cells for drug discovery.
3
28
161
23,997
May 14
We curated DDR-Bench and DTR-Bench to validate virtual cells on practical drug discovery tasks and enable hill-climbing on useful hills. We make one contribution to cell-level screening with CellVS-Net, but the ceiling is still quite far away!
Pre-print: biorxiv.org/content/10.64898…
1
7
677
May 14
Huge thanks to the excellent co-authors behind this work: Sohan Addagudi, @JiaqiWang_, @ben_lengerich, and @ericxing.
This is the final chapter of my phd, but you'll continue seeing this kind of work reflected at @genbioai in our work on general-purpose biological simulators.
6
562