
Sharing insights on Probability, Statistics, ML, DL and AI research. Subscribe for recent research paper discussions at $2/month. DM to collaborate.
Joined September 2022
- Tweets 6,797
- Following 702
- Followers 80,643
- Likes 4,435
2,746 Photos and videos










Pinned Tweet

Smarter workflows start with smarter agents.
GMI Agent Box is coming on June 8th. ⚡

1
7
4,137
Probability MCQ:
A random variable X has probability density function:
f(x) = 2x for 0 < x < 1, and 0 otherwise.
Let Y = √X. What is E[Y]?
A) 2/3
B) 1/2
C) 4/5
D) 8/15
3
2
33
5,616
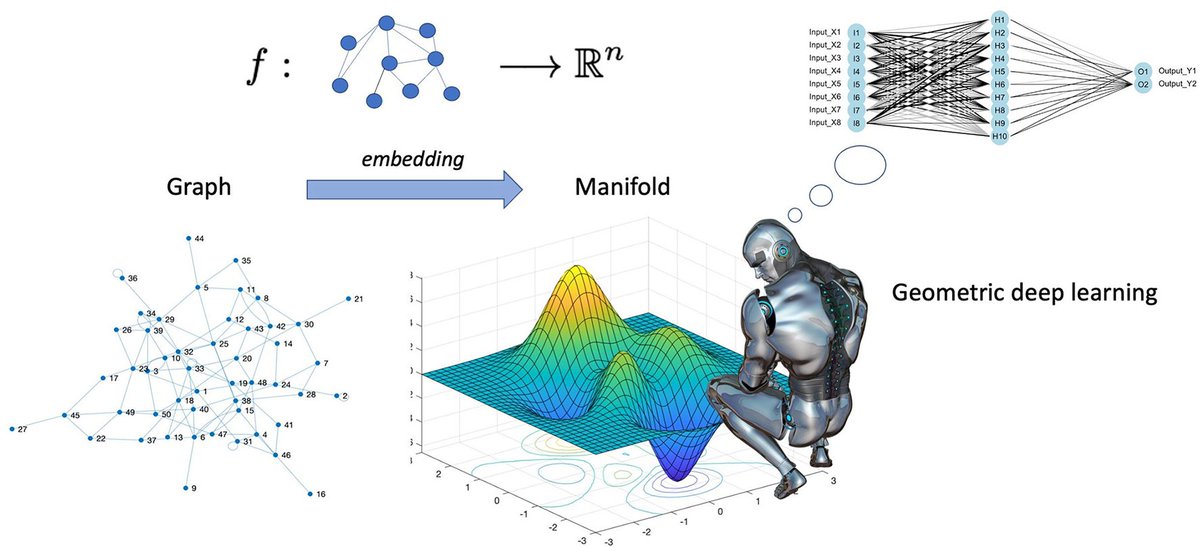
Geometric Deep Learning is an emerging paradigm in machine learning that extends deep learning methods to non-Euclidean domains such as graphs, manifolds, and meshes. Unlike traditional Euclidean-based models, GDL exploits symmetry, invariance, and equivariance principles to design architectures that respect the underlying structure of data. At its core, it generalizes convolution and representation learning beyond regular grids to irregular and structured domains.
In machine learning applications, GDL is widely used through graph neural networks for problems like social network analysis, recommendation systems, and molecular property prediction in chemistry and drug discovery. In deep learning, it enables advances in 3D vision, point cloud processing, and graph-based transformers, while also unifying convolutional neural networks as a special case of geometric operators on lattices. This leads to better inductive biases, improved sample efficiency, and stronger generalization on structured data.
In reinforcement learning, Reinforcement Learning, geometric methods help model multi-agent systems, traffic networks, and relational environments where states and interactions are naturally graph-structured. This supports better coordination, planning, and transfer across agents and environments. Overall, geometric deep learning provides a unifying framework linking ML, DL, and RL by embedding geometry and symmetry into learning systems, enabling more structured, efficient, and generalizable intelligence.
Image: share.google/CPaCdmSG0vBrZQX…
4
51
361
13,122
Probability MCQ:
Let X₁, X₂, ... be i.i.d. random variables with P(Xᵢ = 1) = P(Xᵢ = −1) = 1/2. Define the random walk: Sₙ = X₁ X₂ ⋯ Xₙ.
Which of the following statements is TRUE?
A) P(Sₙ = 0 infinitely often) = 0
B) P(Sₙ = 0 infinitely often) = 1/2
C) P(Sₙ = 0 infinitely often) = 1
D) The limit does not exist
Reply with your answer 👇
Bonus:
Which deep theorem in probability explains this phenomenon, and how would the answer change for a simple symmetric random walk in ℤ³?
4
2
34
17,285
Wasserstein Learning Theory is a rapidly growing area of machine learning that uses ideas from optimal transport to analyze probability distributions, generalization, and learning dynamics. At its core is the Wasserstein distance, which measures the minimum cost of transporting one probability distribution into another. Unlike divergences such as KL divergence, Wasserstein distances incorporate the geometry of the underlying space, making them particularly suitable for comparing complex distributions.
In probability and statistics, Wasserstein metrics are used to study convergence of distributions, concentration inequalities, empirical processes, and distributional robustness. In machine learning, they provide powerful tools for domain adaptation, distribution shift analysis, generative modeling, and robust optimization. The success of Wasserstein GANs demonstrated how transport-based objectives can stabilize training and improve sample quality.
In deep learning, Wasserstein methods help analyze representation learning, neural network dynamics, and generalization under distributional changes. In reinforcement learning, Wasserstein distances are widely used in distributional RL, where agents learn entire return distributions rather than only expected rewards. They also appear in robust RL and exploration under uncertainty.
The deeper insight is that learning often involves comparing distributions rather than individual observations. By incorporating geometry into probability, Wasserstein learning theory provides a principled framework for understanding robustness, generalization, and adaptation in modern AI systems.
share.google/5G5OG3I8eHS0aVw…
1
70
413
17,638
Banks allow for 0 opening balance accounts?
Jun 9

This is how much Microsoft pays you right after college. Freshers get this much. It is equal to some TCS employees yearly salary.
That's why everyone wants to work at FAANG

2
17
7,988
Probability MCQ:
Let X₁, X₂, ..., Xₙ be i.i.d. random variables with P(Xᵢ = 1) = P(Xᵢ = 0) = 1/2. Define Yₙ = X₁X₂⋯Xₙ. What is limₙ→∞ E[Yₙ] ?
A) 0
B) 1/2
C) 1/e
D) Does not exist
Reply with your answer.
Bonus:
Can you compute E[Yₙ] exactly for finite n and explain why almost sure convergence and convergence in expectation behave differently here?
7
1
40
6,081
Check out this MLE post on Substack: substack.com/@probabilityand…
1
9
2,159
In-Context Learning is one of the most remarkable discoveries in modern AI. It refers to the ability of large models, particularly transformers, to perform new tasks simply by observing examples in their input context, without updating their parameters. Instead of learning through gradient descent during deployment, the model adapts its behavior using information provided in the prompt.
This phenomenon emerged prominently with large language models and has sparked extensive research into how neural networks can implicitly perform learning during inference. Theoretical work suggests that transformers may approximate meta-learning algorithms, Bayesian inference procedures, or optimization processes within their attention mechanisms.
In machine learning, in-context learning enables few-shot and zero-shot adaptation, reducing the need for task-specific training. In deep learning, it has become a cornerstone of foundation models, allowing a single model to perform translation, reasoning, coding, and prediction tasks from examples alone. In reinforcement learning, related ideas appear in meta-RL, where agents learn how to learn from experience across tasks rather than mastering a single environment.
The broader insight is that intelligence may involve not only storing knowledge in parameters but also dynamically adapting to new information at inference time. In-context learning has therefore become a central topic in understanding the capabilities and limitations of modern AI systems.
Image: share.google/GFp899euNz6G20k…
3
13
88
7,228
Statistics MCQ:
Let X₁, X₂, ..., Xₙ be i.i.d. observations from a distribution with finite variance σ². Suppose θ̂ₙ is an estimator such that: √n(θ̂ₙ − θ) ⇒ N(0, σ²) and let g be a differentiable function with g′(θ) ≠ 0.
What is the asymptotic distribution of √n(g(θ̂ₙ) − g(θ))?
A) N(0, σ²)
B) N(0, [g′(θ)]²σ²)
C) N(0, g′(θ)σ²)
D) Cannot be determined
Reply with your answer.
Bonus:
Which fundamental theorem of asymptotic statistics is being used here, and what happens if g′(θ) = 0?
3
3
34
5,004
AI innovation moves faster when builders spend less time on infrastructure.
GMI AgentBox brings the pieces together so teams can focus on building.
#GMICloud #GMIAgentBox
@gmi_cloud
Jun 8
Today, we are launching GMI Agent Box.
A complete infrastructure stack for production-ready AI agents:
native Docker, flexible deployment, 200 models under one API key, dedicated compute across regions, and a marketplace for distribution.
Available now.
8
2,367
Gaussian Process Deep Learning combines the uncertainty quantification of Gaussian processes with the representation-learning power of deep neural networks. A Gaussian process (GP) defines a distribution over functions, allowing predictions to be accompanied by principled uncertainty estimates. Unlike standard neural networks, which typically produce point predictions, GP-based models naturally capture confidence and uncertainty in their outputs.
The key idea is to learn hierarchical representations while retaining the Bayesian nonparametric nature of Gaussian processes. Deep Gaussian Processes stack multiple GP layers, enabling highly flexible function approximation and richer representations than classical GPs.
In statistics, Gaussian process deep learning provides powerful tools for nonparametric regression, classification, uncertainty quantification, and Bayesian inference. In machine learning, it is used for active learning, Bayesian optimization, surrogate modeling, and learning from limited data. In deep learning, GP methods improve calibration, robustness, and interpretability while providing theoretical connections between infinitely wide neural networks and kernel methods.
In reinforcement learning, Gaussian process models are valuable for model-based RL, exploration under uncertainty, and sample-efficient learning. Since uncertainty estimates guide exploration, agents can make better decisions with fewer interactions. The broader insight is that intelligence requires not only prediction but also awareness of uncertainty. Gaussian process deep learning offers a principled framework that combines expressive representation learning with rigorous probabilistic reasoning.
Image: share.google/fdmkvG2M78osQLI…
3
71
457
14,854
Statistics MCQ:
Suppose X₁, X₂, ..., Xₙ are i.i.d. observations with mean μ and variance σ² < ∞. Let Tₙ = (1/n) Σ(Xᵢ − X̄)². What does Tₙ converge to almost surely as n → ∞?
A) σ²
B) (n−1)/n · σ²
C) 0
D) Depends on the distribution
Reply with your answer.
Bonus:
Why does the sample variance with denominator n−1 remain unbiased, while Tₙ uses denominator n and is still consistent?
9
4
64
24,054
Kernel Mean Embeddings are a powerful framework that represents probability distributions as elements of a reproducing kernel Hilbert space (RKHS). Instead of working directly with probability densities, a distribution P is mapped to a feature representation
μₚ = E[k(X, ·)]
where k is a kernel function. This allows complex distributions to be analyzed using geometric and functional-analytic tools.
In probability and statistics, kernel mean embeddings provide nonparametric methods for comparing distributions, hypothesis testing, density estimation, and causal inference. They form the basis of powerful techniques such as Maximum Mean Discrepancy (MMD), which is widely used for two-sample testing.
In machine learning, kernel mean embeddings enable learning directly on distributions rather than individual data points. They are used in domain adaptation, generative modeling, distribution regression, and uncertainty quantification. In deep learning, MMD and related kernel methods appear in generative adversarial learning, representation learning, and self-supervised learning. In reinforcement learning, kernel embeddings help model transition dynamics, value functions, and belief states in partially observed environments.
The deeper insight is that many learning problems involve distributions rather than individual observations. Kernel mean embeddings provide a mathematically elegant way to transform probability distributions into geometric objects that can be manipulated, compared, and learned efficiently.
Image: share.google/pfstLtTYOGn7daw…
3
38
238
9,284
Probability MCQ:
Let X₁, X₂, ..., Xₙ be i.i.d. random variables with
P(Xᵢ = 1) = P(Xᵢ = −1) = 1/2. Define Sₙ = X₁ X₂ ⋯ Xₙ. What is the limit of P(S₂ₙ = 0) as n → ∞ after multiplying by √n?
A) 0
B) 1/√π
C) 1/π
D) √(2/π)
Reply with your answer.
Bonus:
Can you derive the answer using Stirling's approximation and the local central limit theorem?
3
8
35
5,420
Offline Reinforcement Learning is a rapidly growing area of AI that studies how agents can learn optimal decision-making policies from previously collected data without further interaction with the environment. Unlike classical reinforcement learning, where an agent continuously explores and gathers new experiences, offline RL relies entirely on a static dataset of state-action-reward transitions.
This setting is particularly important when exploration is expensive, risky, or impossible. Examples include healthcare, autonomous driving, robotics, finance, and recommendation systems, where poor exploratory actions may have serious consequences.
In machine learning, offline RL combines ideas from supervised learning, sequential decision-making, and distributional estimation. In deep learning, large neural networks are used to learn value functions and policies from massive datasets. Modern algorithms such as Conservative Q-Learning (CQL) and Implicit Q-Learning (IQL) address the challenge of distributional shift, where the learned policy may choose actions rarely observed in the training data.
Offline RL is also becoming a foundation for data-driven AI systems trained from large historical datasets. The deeper insight is that intelligence can often be learned from experience that has already been collected. By transforming static data into sequential decision-making strategies, offline reinforcement learning bridges the gap between prediction and autonomous decision-making.
Image: share.google/cihGY5rV502UcFe…
2
21
151
7,463
Information Bottleneck Theory is a powerful framework introduced by Naftali Tishby for understanding learning and representation in intelligent systems. The central idea is that a good representation should compress the input while preserving information relevant to the prediction task. Formally, the objective balances two quantities: maximizing information about the target Y while minimizing unnecessary information about the input X.
A typical objective is:
I(T;Y) − βI(T;X)
where T is the learned representation and I(·;·) denotes mutual information.
In statistics and machine learning, the information bottleneck provides a principled approach to feature extraction, dimensionality reduction, and prediction. In deep learning, it offers a theoretical perspective on why hidden layers learn compressed representations that retain task-relevant information while discarding noise. It has influenced research on generalization, representation learning, self-supervised learning, and neural network interpretability.
In reinforcement learning, information bottleneck methods are used to learn compact state representations, improve exploration, and reduce sample complexity. The broader insight is that intelligence is not merely about storing information—it is about retaining the right information. By balancing compression and prediction, the information bottleneck provides a unifying principle connecting information theory, learning, and decision-making.
Image: share.google/icpdTVCg7DegzS3…
4
42
239
15,344