
Joined February 2018
- Tweets 2,124
- Following 458
- Followers 1,774
- Likes 7,255
609 Photos and videos

















Data Structures & Algorithms has traditionally been a gatekeeper course in Computer Science, I am seriously considering the following paper-only in-class rules as the original generations of programmers did 👇
1
7
793
• Bring a notebook and a pen/pencil to every class.
• During class activities, use paper only unless explicitly asked to use laptops, phones, tablets, or AI tools.
• At the end of the course, the notebook would be used as a reference for final grades.
2
2
369
The course is fundamentally about developing algorithmic thinking. Class time should be dedicated to building that reasoning process. Curious to hear perspectives from fellow educators, technologists, and tech hiring managers: what role should #AI play in foundational CS courses?
1
1
245
So called intelligence, it is not intelligence, but named as intelligence. 🙏
3
1
3
383
An extremely talented mechanical engineer and a painting artist.
The world is cruel ~~~

1
2
306
'YZ' Yezhou Yang (杨叶舟) retweeted

AI-generated images are getting harder to spot and scams are rising. In #SCAI, researcher @prof_yz is helping set global standards to detect synthetic media and even teach AI to forget harmful content, building a more trustworthy digital future.
news.engineering.asu.edu/202…
1
4
335
'YZ' Yezhou Yang (杨叶舟) retweeted

Mar 12
Anyone who claims to be interested in Intelligence should know optimal control theory developed in 1960s, or even cybernetics, as early as in 1940s... My new book was trying to set straight the related history and concepts...
Mar 11

The basic idea of world models is very old.
Optimal control folks were using model-based planning in the 1960s (using the "adjoint state" methods, which deep learning people would now call "backprop through time").
But the real question is what you do with this idea and how you reduce it to practice.
13
64
741
78,194
'YZ' Yezhou Yang (杨叶舟) retweeted

Mar 10
I think it’s pretty clear that simulation is the next frontier for AI.
The most impressive feats of AI to date are when we have a clear environment reward, whether it be beating Le Sedol at Go, winning an IMO gold medal, or writing entire apps from scratch. In these cases, the RL algorithm can try different actions, and observe the well-defined consequences in the safety of a docker container.
But what about messy real-world situations involving people? The rewards are unclear, the stakes are high, and you can’t experiment in the real world. But these situations are precisely where the next big opportunity in AI is. To crack this, we need to *simulate* society (“put society into a docker container”). Concretely, this means building a model that can predict what will happen in any given situation (real or hypothetical). If we can do this, we are only limited by our imagination: predict the future, optimize for better outcomes, answer hypothetical (“what if”) questions. Ultimately, this goes beyond making better decisions, but it’s about giving us a better understanding of ourselves and the world.
Simulation is the whole enchilada. And this is exactly the research that @simile_ai is working on. Read more here:
simile.ai/blog/simulation-ne…
44
110
1,111
119,704
If an inquiry now starts with a customer service line asking, “Are you a real person?”, something has clearly gone awry. 😆
I just did that this morning...
239
I think the next single person tech unicorn could just be hatched from a local Fedex store... These places have everything one needs...
1
241
👇 this is kind of author-reviewer exchange should be.
Authors gain suggestions and perspectives from others, and give out their own to another group of authors as reviewers.
#Walk_For_Peace

3
2
328
'YZ' Yezhou Yang (杨叶舟) retweeted

19 Dec 2025
OpenReview is a pillar of progress in the AI research community. Now it needs our support.
Along with several of my colleagues, I have pledged to help, and I encourage anyone who can to do the same.
openreview.net/donate
OpenReview
Promoting openness in scientific communication and the peer-review process
openreview.net 23
47
355
61,035
'YZ' Yezhou Yang (杨叶舟) retweeted

19 Dec 2025
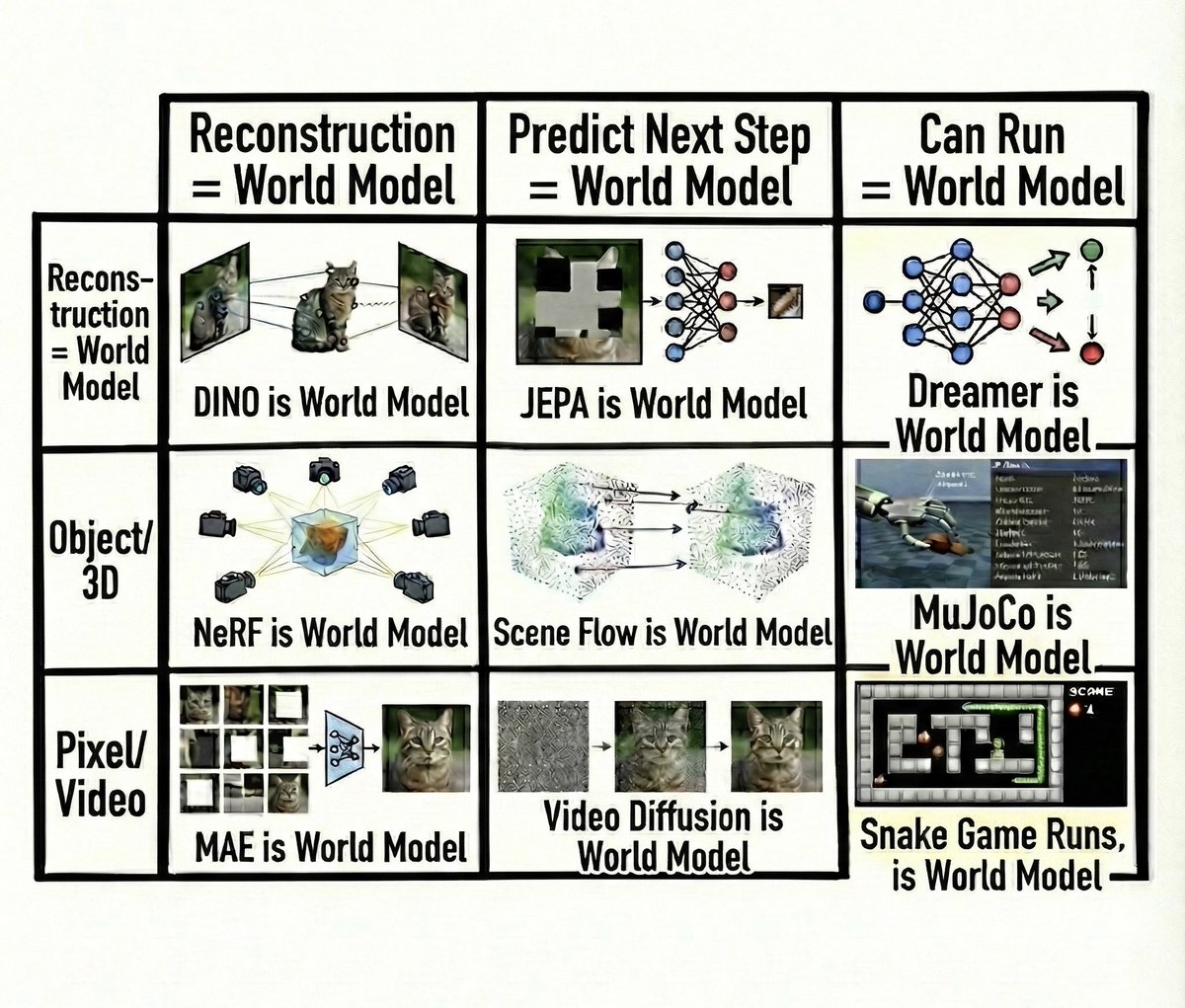
Everything is a world model if you squint hard enough.
29
116
902
60,056

19 Dec 2025
Congratulations Dr. Sheng Cheng (now at #Amazon #AGI) and Master Abhiram Kusumba (now at #CapitalOne #AI) 🎉🎉🎉
1
9
573
'YZ' Yezhou Yang (杨叶舟) retweeted

15 Nov 2025
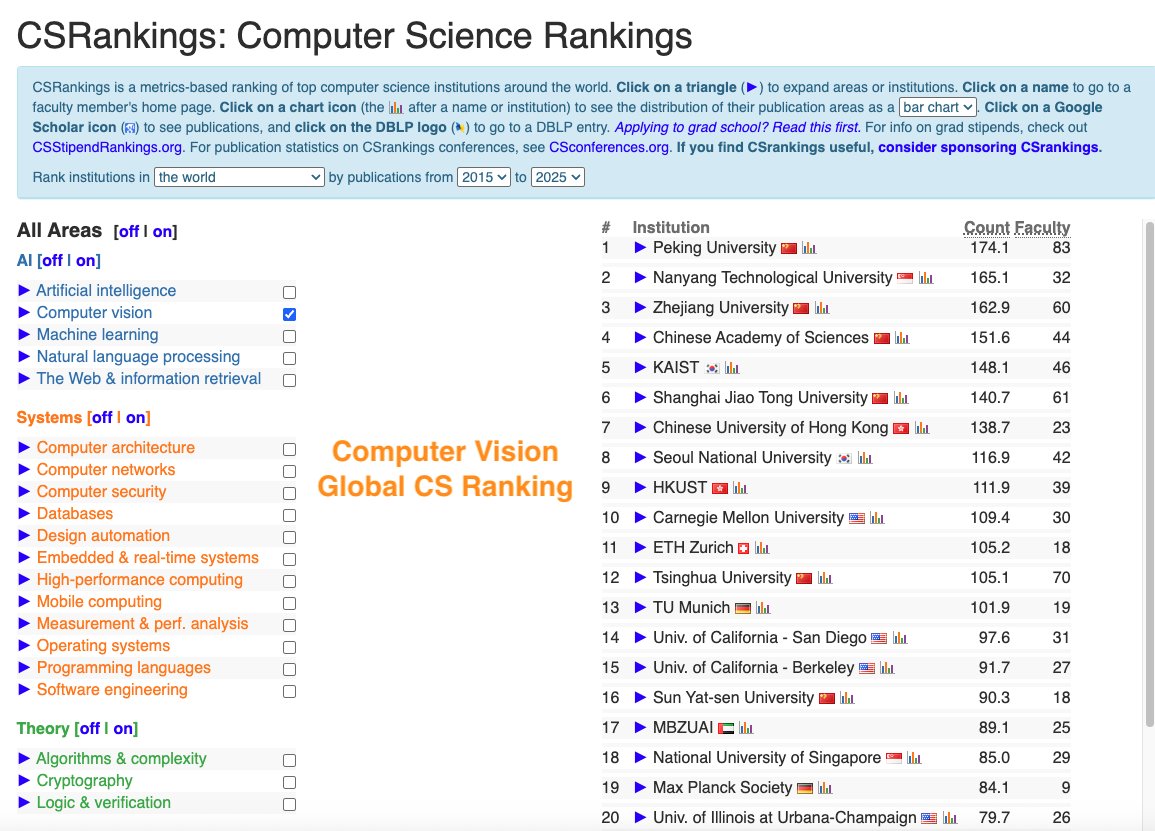
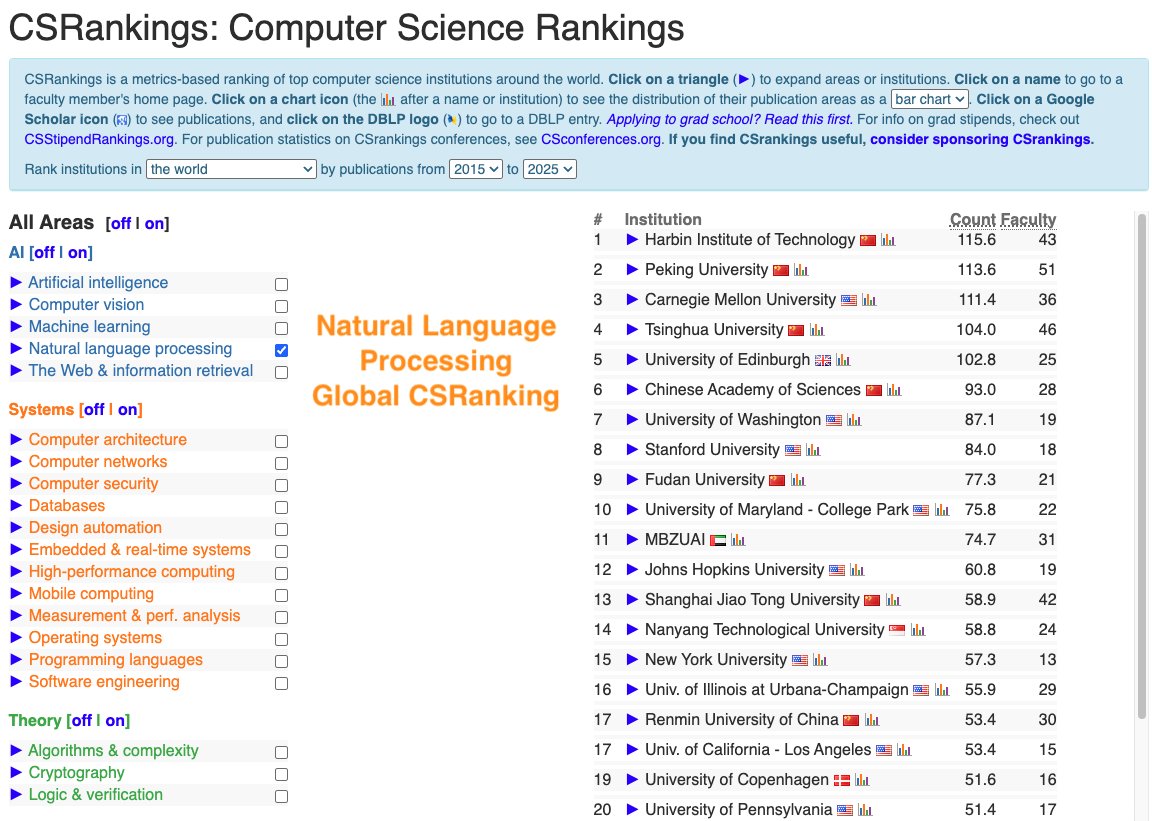
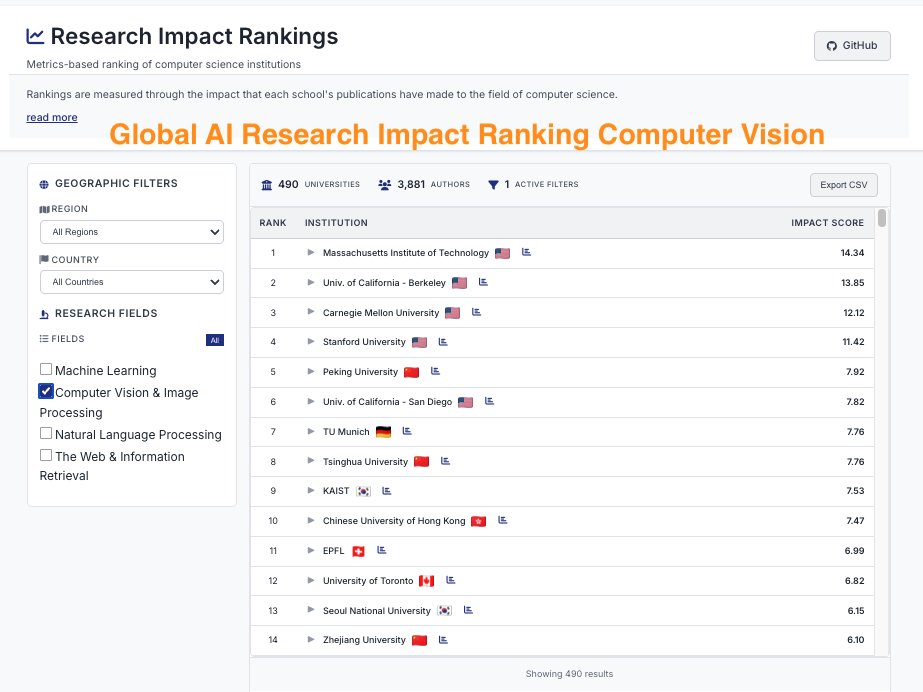
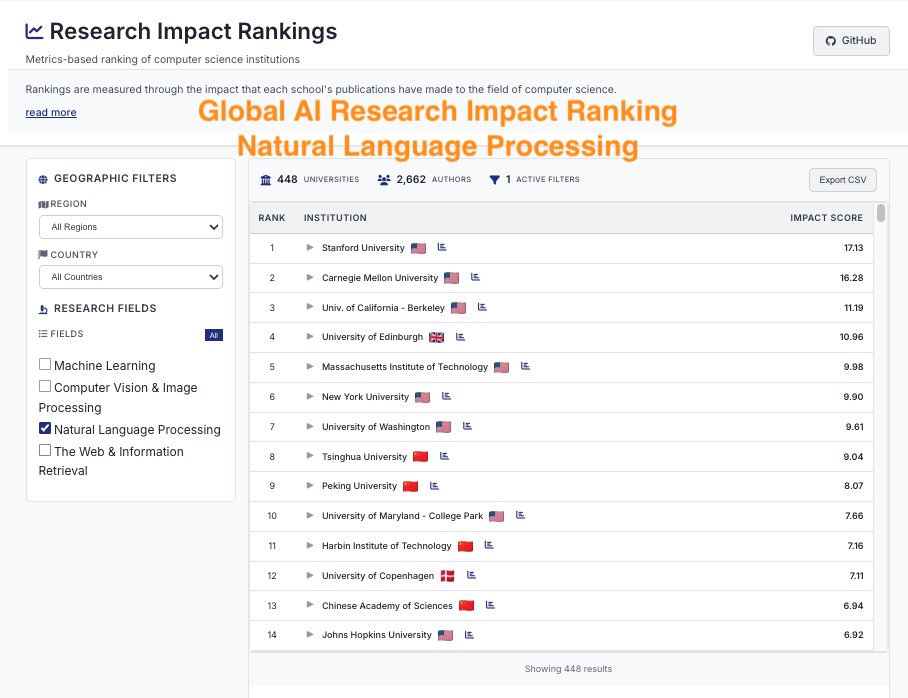
CSRankings counts publication in top conferences to rank professors/universities. But this encourages researchers to pursue quantity rather than quality.
We propose impactrank.org/, a new university ranking system that tries to measure quality instead of quantity of publications.
How can we measure the quality of the publications? We believe that 1) The quality of research is best understood and evaluated by peers in the same research area;
2) With careful and informed use, LLMs can reveal the implicit quality judgments that peers convey through their citation practices and writing across large volumes of scholarly work.
Hence, we developed the new ranking system where we analyze research papers from major AI conferences with LLMs.
For each paper, we ask an LLM what are the 5 most important papers to this paper. In other words, the five works that most strongly influence the study. By doing this, we trace which papers and authors are consistently seen as inspirational and foundational to new discoveries in the field.
We ran the model on all papers from top conferences in machine learning, computer vision, natural language processing and information retrieval from 2020 - 2025, and filtered references to only have those from 2000 onwards.
Next, we map these influential authors to their affiliated universities using the CSRankings name–affiliation database. Each time a paper is recognized as one of the “top five references” in another work, its authors and their institutions receive credit. To keep the scoring fair, points are divided by the number of co-authors, ensuring balanced recognition across collaborations.
The result is a new kind of academic ranking: one that rewards universities not just for publishing often, but for producing research that endures, inspires, and drives the field forward. This approach highlights scholarly influence and provides students, researchers, and institutions with a clearer picture of where the most impactful work is happening.
Note that we believe that CSRankings had substantially improved university rankings in computer science by replacing subjective, reputation-based measures, such as those in US News, with more objective indicators, but the LLM era allows us to do something potentially better!
Due to computational resource limits, we were only able to run it with a small 7B language model. It is also a project primarily led by undergraduate and master students from Oregon State University and University of California Santa Cruz. As a result, the system is very much a work in progress and will inevitably contain errors and blind spots. We actively welcome community feedback, new collaborators and contributions of GPU compute so that we can run larger LLMs, obtain more reliable results and improve the methodology.
14
40
367
175,824
'YZ' Yezhou Yang (杨叶舟) retweeted

8 Dec 2025
Linus's views on AI:
- “AI is clearly a bubble, but it will change how most skilled jobs get done.”
- “Vibe coding is great for getting into programming, but it's a horrible thing to maintain.”
- “I'm a huge believer in AI. I'm not a huge believer in the things around AI. I find the market and marketing to be sick. There is going to be a crash.”
188
924
12,499
1,129,569