
Joined March 2024
- Tweets 18,581
- Following 444
- Followers 1,638
- Likes 2,414
58 Photos and videos

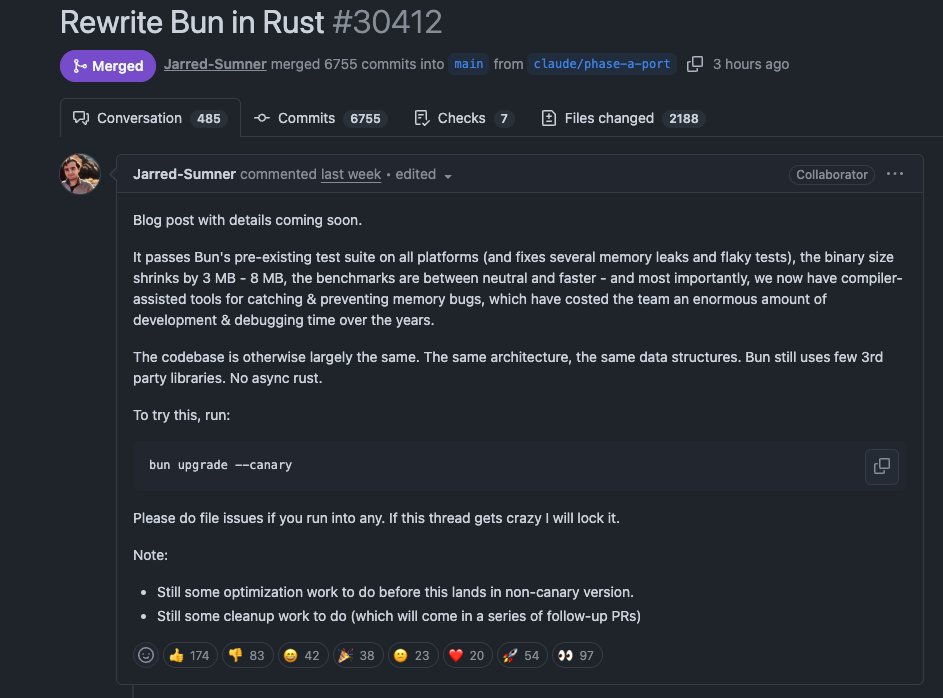










Pinned Tweet

30 Aug 2025
The best advice I ever got: "Don't optimize for the algorithm - optimize for the human on the other side of the screen."
Social media success isn't about gaming the system. It's about genuine connection and adding real value to real people's lives 🤝
9
3
72
17,776
Cursor pagination also buys you consistency, not just scale. Offset pagination gets slower as you go deeper and it drifts under concurrent writes. Cursors keep the access pattern stable and the user experience less surprising.
8
Jun 9
Wow …this is what benchmarkmaxxing looks like ! Need to see how it performs on real world tasks.

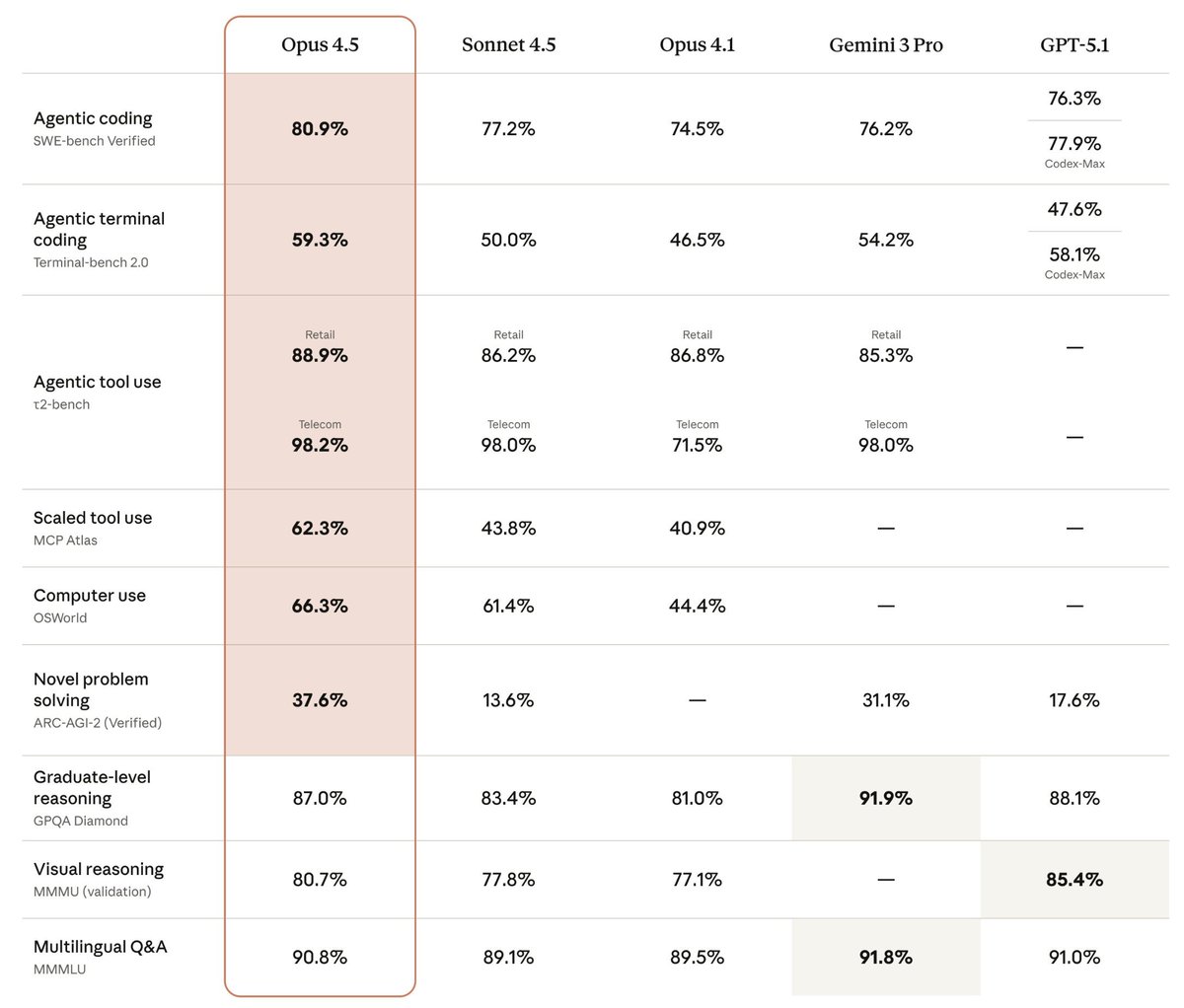
Fable 5 is state-of-the-art on nearly all tested benchmarks, with exceptional performance in software engineering, knowledge work, scientific research, and vision.
The longer and more complex the task, the larger Fable 5’s lead over our other models.
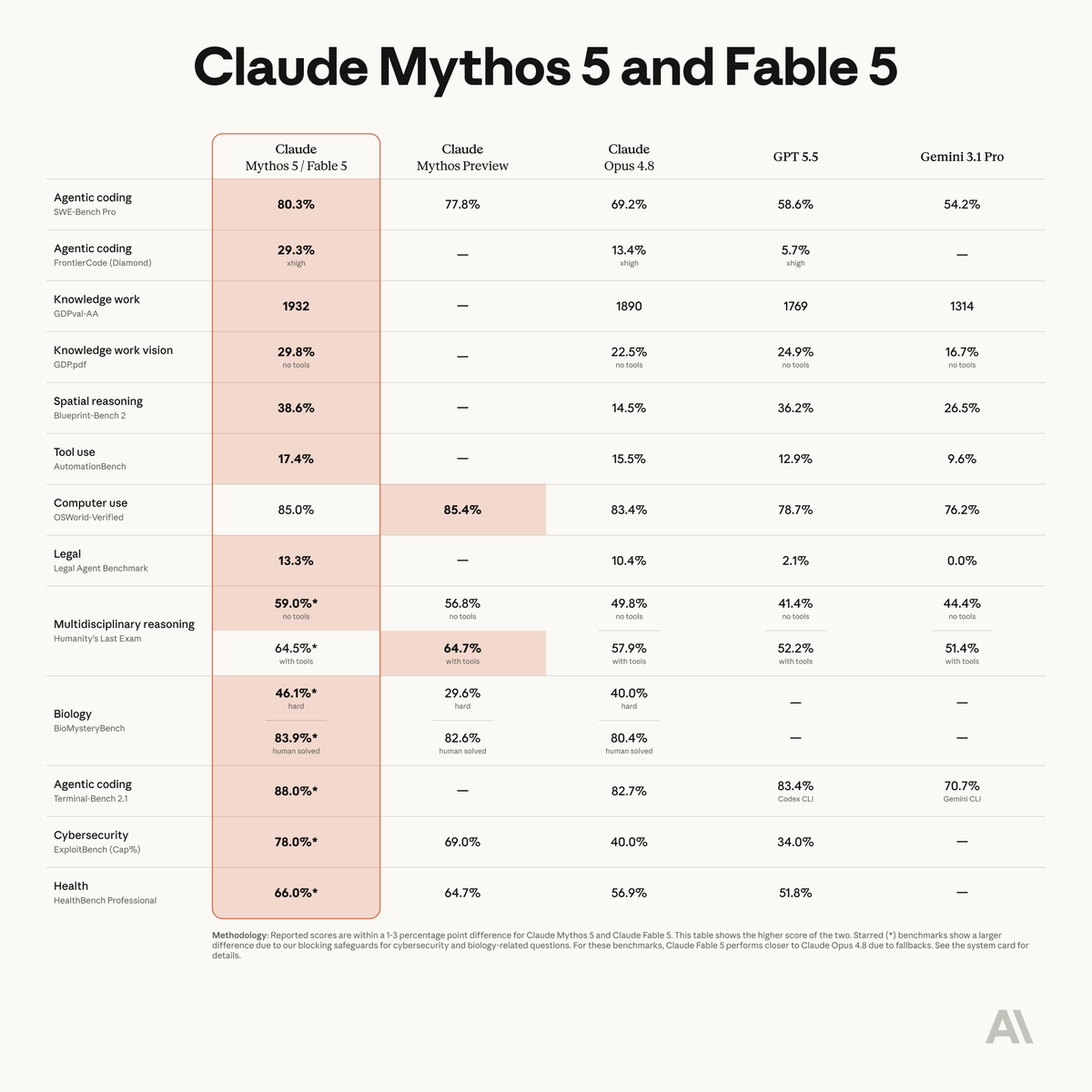
ALT Benchmark table titled Mythos 5 & Fable 5, comparing Claude Mythos 5 and Fable 5 against Claude Mythos Preview, Claude Opus 4.8, GPT 5.5, and Gemini 3.1 Pro.
115
Jun 5
For those moving from claude code to codex, do you think it is because of the model or the harness ?
5
4
414
May 28
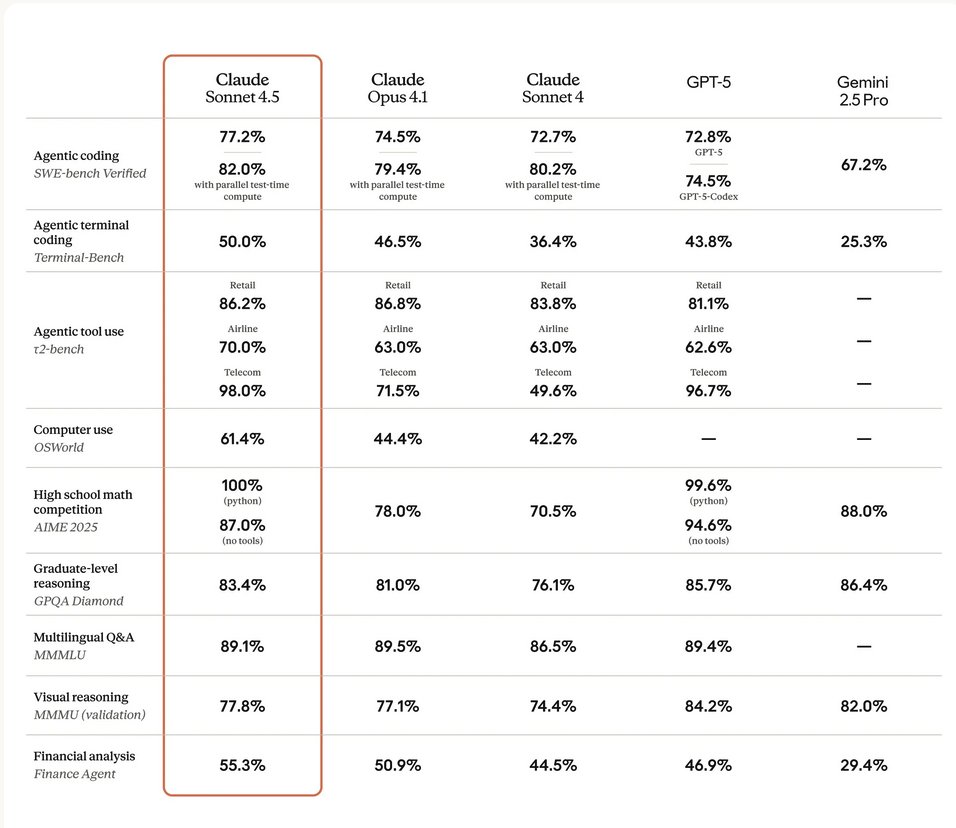
Opus 4.8 is here
Introducing Claude Opus 4.8: it builds on Opus 4.7 with sharper judgment, more honesty about its own progress, and the ability to work independently for longer than its predecessors.
Available today at the same price.
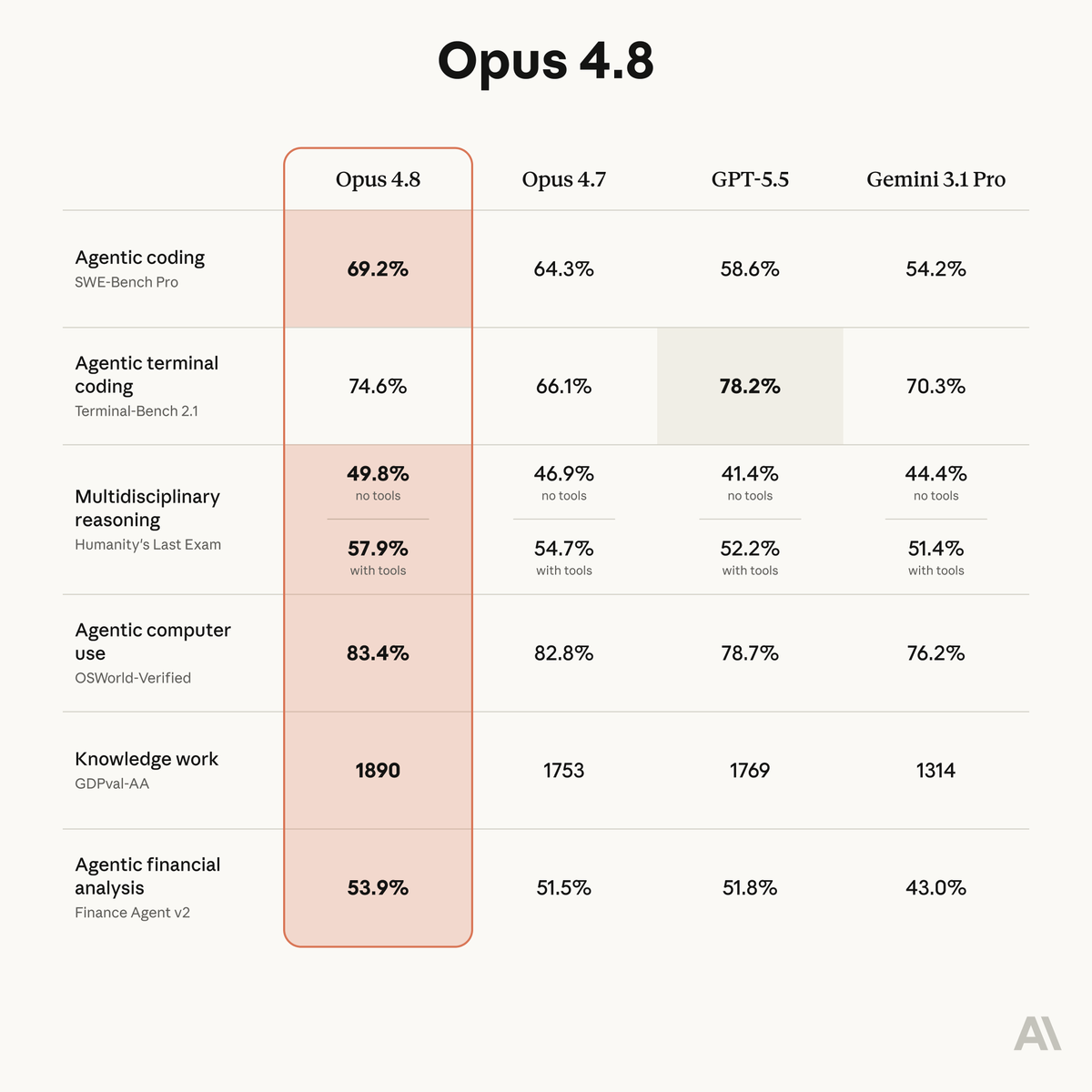
ALT Benchmark table showing how Claude Opus 4.8 compares to its predecessor and to other models on tests of coding, agentic skills, reasoning, and practical knowledge work tasks.
1
7
957
May 24
AI provenance is not really about watermarking images.
It is shared trust infrastructure: signed metadata, durable signals like SynthID, and verification tools that survive platform handoffs
The hard part is adoption, not detection
3
8
453
May 24
Vector search got AI apps started. Graph-aware retrieval may fix what nearest-neighbor text misses.
Agents often need relationships, time, entities, and multi-hop context before acting.
The bottleneck is not more chunks. It is better retrieval surfaces
2
5
310
May 24
Coding agents do not need more vibes.
They need acceptance tests, browser validation, and repair reports
Requirements should become executable product checks before an agent can call the app shippable.
2
220
May 23
AI code refactors can pass review and still add risk.
One Python study found agentic refactoring PRs had a 73.5% merge rate, while 24.17% of modified files added new Pylint issues and 4.7% added Bandit findings.
You need to implement tight checks and reviews
4
5
221
May 23
Frontier AI is starting to look less like SaaS pricing and more like cloud procurement
OpenAI introduced “Guaranteed Capacity” which means 1-3 year commitments, access certainty, and discounts
Capacity planning is becoming product architecture
1
2
146
May 22
The indie SaaS flex in 2026 may be no AI in the core loop.
Zero AI features.
Use AI where it helps. Do not paste it everywhere.
1
3
155
May 22
Cloud docs are becoming executable instructions for coding agents.
AWS Agent Toolkit is the signal: platforms now need service guidance, workflows, and guardrails that agents can actually use.
The platform has to teach the agent, not just the human.
aws.amazon.com/about-aws/wha…
4
105
May 22
Most vibe coded apps face a brutal question.
Why would someone pay you instead of using ChatGPT, a spreadsheet, or manual work?
If the answer is not workflow, trust, memory, compliance, or distribution, it may just be a demo.
1
4
99
May 22
AI can’t log like Humans.
An arXiv study of 4,550 agentic PRs found agents failed 67% of constructive logging requests.
If logs matter, make them policy-backed, reviewable, and testable.
arxiv.org/abs/2604.09409
1
2
101
May 22
Coding agents make pricing, a part of the UX.
What developers want: one endpoint, model choice, and predictable spend because long agent loops turn token anxiety into product friction.
Flat cost is not unlimited compute, it is a painkiller
1
1
74
May 22
Websites have a new visitor to optimize for: browser agents.
Lighthouse 13.3 now includes Agentic Browsing checks for accessibility trees, layout shifts, WebMCP, and llms.txt.
SEO was for search engines. This is operability for agents.
developer.chrome.com/docs/li…
84
May 21
Scientific AI is moving from retrieval assistant to a hypothesis committee.
DeepMind's Co-Scientist uses agents to generate, debate, rank, and refine research ideas.
The human’s job is just choosing what deserves real validation using this loop.
deepmind.google/blog/co-scie…
2
2
166
May 21
Robotics may not just need bigger AI models
There is a quieter problem: messy visual input
Lighting, clutter, occlusion, and camera noise can break policies
Better filters may matter as much as bigger brains
3
4
99
May 20
AI-generated software can pass tests and still smell wrong.
A research paper argues functional correctness is too narrow: agents can create bloated, coupled, hard-to-maintain systems.
The next quality bar is architecture, not just green tests.
arxiv.org/abs/2605.02741
2
136
May 20
AI did not give developers their time back.
AI can make implementation faster
But the result is higher sprint expectations instead of shorter workweeks.
Who else is seeing this ?
6
7
141
May 20
Most AI startups do not die because OpenAI copied them.
They die earlier: the demo was impressive for 10 minutes, but nobody needed it Monday morning.
The real question is not "is this a wrapper?"
It is: does this become part of the workflow?
2
64