
Joined April 2020
- Tweets 951
- Following 522
- Followers 4,519
- Likes 2,402
96 Photos and videos











Pinned Tweet

11 Aug 2025
Relightable Codec Avatars is now extended to full-body! At #SIGGRAPH2025, we will present Relightable Full-body Gaussian Codec Avatars. Key contributions include learnable Zonal Harmonics and deferred learnable radiance transfer for specular! Check it out!
neuralbodies.github.io/RFGCA…
2
30
175
13,686
Shunsuke Saito retweeted

Apr 9
Facebookやインスタ、VRのQuestやAIグラスのRay-Ban MetaのMetaによる新研究「LCA」。
100万本の動画学習により、スマホ撮影から表情や指の動きまで精密な3Dアバターを一瞬で生成可能に。
服の揺れや照明変化も自然に再現され、将来的にスタジオ級の分身がスマホで作れる世界を目指してる模様。
6
64
450
33,386
Shunsuke Saito retweeted

Apr 27
Sapiens2 test.
All things considered, probably the best pose I have used. Still heavily reliant on a good bbox detection though.
I am out of the loop and do not know what the "Best" bbox detection is these days.
10
28
250
41,570
Shunsuke Saito retweeted

May 12
Meta silently dropped Sapiens2 last week 🔥
a family of high-res models trained on 1B human images
> for pose estimation, body-part segmentation, surface normals, pointmaps (sota)
> 6 sizes: 0.1B → 5B params (all ViT patch 16)
> high-res: 1024×768 and 4K
10
47
444
30,081
Shunsuke Saito retweeted

There used to be a time when a novel architecture would do it...
But today, data is the one dictating the rules!😬
@Meta Reality Labs solved dense human-centric tasks with specialized foundation models, proving that they still hold a massive advantage over generalist ones.

1
5
35
3,057
Shunsuke Saito retweeted

Apr 29
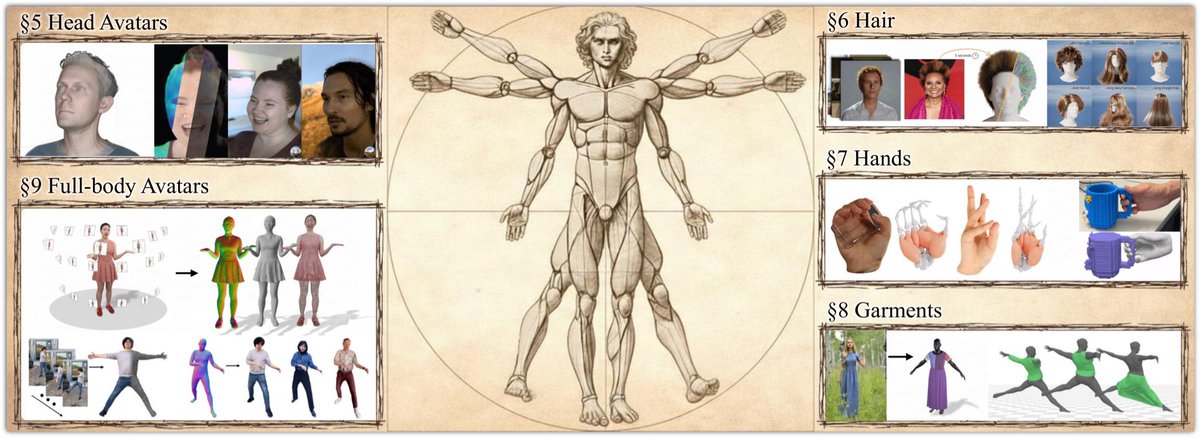
I am happy to share that our STAR has been accepted to Eurographics 2026:
“How to Build Digital Humans?”
It introduces a novel taxonomy and a concise overview of the full creation pipeline, from face and body to hands, garments, and hair.
tinyurl.com/5f6u7rks
1
17
73
7,366
Shunsuke Saito retweeted

Apr 24
Sapiens2 is the highest quality ViT backbone that now exists in the public domain. It was pretrained on the equivalent of 1/2 of all human images on Flickr. First public release by a large lab that is non-trivial to replicate. Huge public service. Well done.




4
46
519
57,866
Shunsuke Saito retweeted

Apr 24
Introducing Sapiens2 — the next generation of our human-centric vision models
Pretrained at scale and at high resolution, Sapiens2 learns human semantics more effectively without losing fidelity, and generalizes strongly across human vision tasks.
Paper: arxiv.org/pdf/2604.21681
Accepted at ICLR 2026
Code: github.com/facebookresearch/…
Demo: huggingface.co/collections/f…
10
42
279
32,798
Shunsuke Saito retweeted

Apr 3
LCA is accepted at CVPR 2026! 🚀
We introduce a pre/post-training paradigm for 3D avatars (1M in-the-wild videos ➡️ studio data).
The result? High-fidelity full-body avatars with emergent relightability and zero-shot stylization.
Project: junxuan-li.github.io/lca/
#CVPR2026
2
17
52
3,010
Shunsuke Saito retweeted
Large-scale Codec Avatars: learning photorealistic avatars from millions of videos.
A massive team effort, and incredibly proud of how it turned out.
- Project: junxuan-li.github.io/lca
- Paper: arxiv.org/html/2604.02320v1 #CVPR2026
10
56
294
25,978
Shunsuke Saito retweeted

Jan 19
I've been working a lot with SAM3 and the Momentum Human Rig (MHR). I finally integrated it into the data I'm working with @rerundotio. The progression I've taken looks as follows
SAM3 SAM3D-body on
1. a single image
2. a set of multiple images
3. a single video
4. A multiview video capture
I took inspiration from the SAM3D-body paper and built a multiview fitting optimization pipeline. This pipeline involves using the 2D keypoints from the single-view pipeline, triangulating them, and employing an L1 loss between the 2D/3D keypoints. The temporal stability isn't great, so that's the next portion I'm going to focus on.
One really frustrating thing about SAM3D-body is the lack of per-joint confidence values. It makes it harder to deal with occlusions. I'm probably going to need to use a separate model, or maybe add a confidence head.
Jan 8

Back to working on exo ego in @rerundotio. This is a big jump in progress! One of the main painpoints I've had is getting the ego and exo views aligned in the same coordinate system, but I finally managed to get it all working.
This means that now I have
1. Slam working for ego
2. Calibrated exo views
3. 3D keypoints for the full human body
4. 6DoF wrist poses
5. Temporally aligned videos
6. Spatially aligned multi cameras
Now it's time to scale it up 🙂
9
44
448
43,035
Shunsuke Saito retweeted

18 Dec 2025
毎年お馴染みlevelsfyiの年度末レポートがやってきたので気になるところだけまとめてく
メリカのトップ給与動向のまとめ
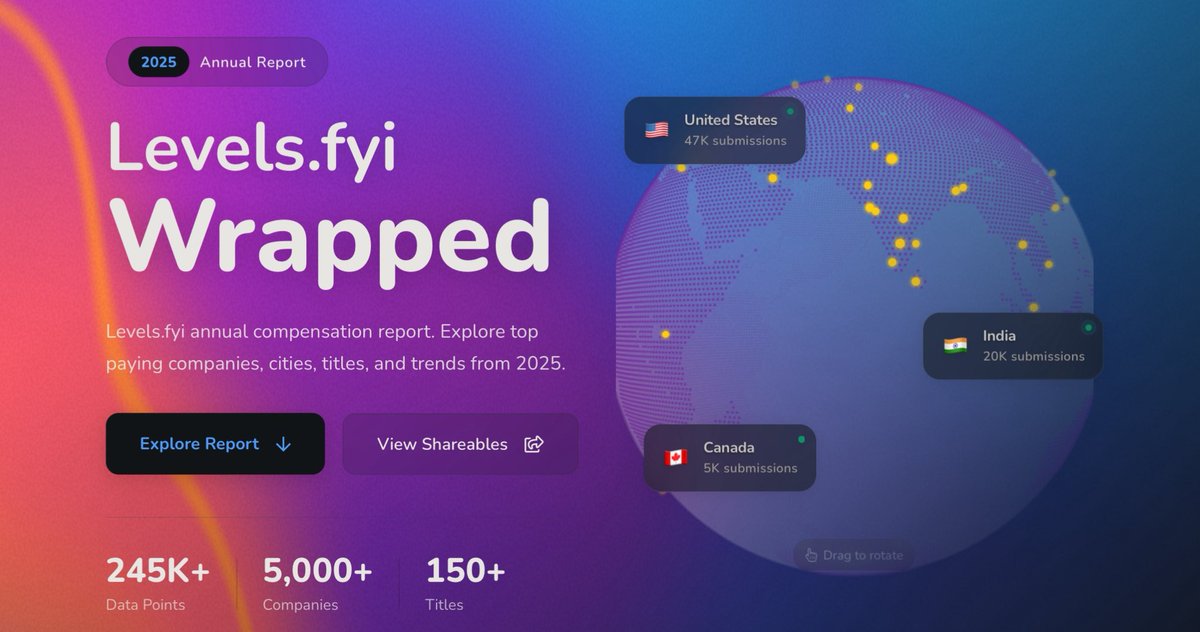
1
6
40
28,829
Shunsuke Saito retweeted

25 Nov 2025
SAM 3D is helping advance the future of rehabilitation.
See how researchers at @CarnegieMellon are using SAM 3D to capture and analyze human movement in clinical settings, opening the doors to personalized, data-driven insights in the recovery process.
🔗 Learn more about SAM 3D: go.meta.me/305985
34
87
487
67,147
Shunsuke Saito retweeted
19 Nov 2025
Introducing SAM 3D, the newest addition to the SAM collection, bringing common sense 3D understanding of everyday images. SAM 3D includes two models:
🛋️ SAM 3D Objects for object and scene reconstruction
🧑🤝🧑 SAM 3D Body for human pose and shape estimation
Both models achieve state-of-the-art performance transforming static 2D images into vivid, accurate reconstructions.
🔗 Learn more: go.meta.me/305985
129
1,058
6,415
857,191
Shunsuke Saito retweeted

19 Nov 2025
Super excited to share the release of SAM 3D. It's been a year in the making. Two models for lifting object and people to 3D!
19 Nov 2025

Introducing SAM 3D, the newest addition to the SAM collection, bringing common sense 3D understanding of everyday images. SAM 3D includes two models:
🛋️ SAM 3D Objects for object and scene reconstruction
🧑🤝🧑 SAM 3D Body for human pose and shape estimation
Both models achieve state-of-the-art performance transforming static 2D images into vivid, accurate reconstructions.
🔗 Learn more: go.meta.me/305985
9
11
164
15,626
30 Oct 2025
これはICCVの専門家を名乗ってもいいのではないだろうか。そんなのあるのか知らないが
20 Oct 2025

「ICCV2025」トップカンファレンス定点観測 vol.19
research-p.com/column/2579
#ICCV2025
26
6,817
Shunsuke Saito retweeted

20 Oct 2025
I have two exciting career updates to share! 😃
1️⃣ After memorable years at KAIST, I recently joined Meta as a Postdoctoral AI Research Scientist! I’m thrilled to be part of the Codec Avatars Lab, working with Shunsuke Saito (@psyth91) — one of the few researchers I admired most during my PhD years — and his amazing team. I’m genuinely super excited about the next-generation avatar project we’re pushing forward!
2️⃣ I’m currently attending ICCV 🏖 and will be giving a keynote talk at the HANDS workshop this afternoon. If you’re interested, please join the talk at 13:40 in room 305B. If you’d like to connect or chat outside of the talk, also feel free to drop me a message!

18
15
459
41,176
Shunsuke Saito retweeted

26 Aug 2025
Introducing ATLAS: A high-fidelity, parametric human body model enabling precise, independent control of surface and skeletal attributes for character creation. To be presented at #ICCV2025!
Learn more about ATLAS here:
jindapark.github.io/projects…

6
34
186
25,740
11 Aug 2025
Want Gaussian Avatar on mobile? Turns out the bottleneck is decoding of pose correctives. At #SIGGRAPH2025, we present a simple yet highly effective solution. We make *any* Gaussian avatars mobile-ready via linear distillation and corrective sharing. 👉forresti.github.io/squeezeme…
2
12
104
14,731

📢 #SIGGRAPH2025 I'll be presenting our paper "3DGH: 3D Head Generation with Composable Hair and Face". Swing by and let's talk about hair and head generation! #Meta #Yale
⏰ Monday, Aug 11 | 2:00pm - 3:30pm PDT
📍 West Building, Rooms 301-305
🔗 c-he.github.io/projects/3dgh…
1
4
16
1,192
11 Aug 2025
Relightable Codec Avatars is now extended to full-body! At #SIGGRAPH2025, we will present Relightable Full-body Gaussian Codec Avatars. Key contributions include learnable Zonal Harmonics and deferred learnable radiance transfer for specular! Check it out!
neuralbodies.github.io/RFGCA…
2
30
175
13,686