
Python Piura
Joined August 2016
- Tweets 248
- Following 385
- Followers 265
- Likes 416
46 Photos and videos










Pinned Tweet

27 Apr 2017
Estamos haciendo videotutoriales, a ver que tal nos va, es nuestra primera vez pero iremos mejorando youtu.be/PFUJv0CykO8
2
3
15 Oct 2024
Charla: Optimización Matemática para Machine Learning
Fecha del evento: 19 de Octubre del 2024
Hora: 9:30 am - 11:30 am
Ponente: Yosbi Jhon Gollés Paico
Registrate en: forms.gle/USNhDffspRQt6LzG9
46

Python Piura retweeted

8 Feb 2024
Building error-free RAG systems comes with challenges, including maintaining document quality, refining prompts, and addressing hallucinations.
In this workshop, we'll synthesize what we’ve learned from hundreds of AI teams that are using RAG.
RSVP: hubs.la/Q02kgTQ80
6
17
5,650
Python Piura retweeted

15 Jan 2024
Many Machine Learning tutorials rely on using frameworks that hide what's really going on under the hood.
But not in this course: its "no black box" approach lets you see exactly how things work.
You'll learn ML & neural networks with no frameworks.
freecodecamp.org/news/learn-…
110
512
35,941
Python Piura retweeted

10 Jan 2024
🐍📰 Document Your Python Code and Projects With ChatGPT
#python realpython.com/document-pyth…
4
11
4,549
Python Piura retweeted

30 Dec 2023
Mixtral 8x7B Instruct with AWQ & Flash Attention 2 🔥
All in ~24GB GPU VRAM!
With the latest release of AutoAWQ - you can now run Mixtral 8x7B MoE with Flash Attention 2 for blazingly fast inference.
All in < 10 lines of code.
The only real change except loading AWQ weights is to pass attn_implementation="flash_attention_2" over to the .from_pretrained call whilst loading the model.
Here's a full run through:
1. Install AutoAWQ and transformers
pip install autoawq git https://github. com/huggingface/transformers.git
2. Initialise the tokeniser and the model
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
model_id = "casperhansen/mixtral-instruct-awq"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
low_cpu_mem_usage=True,
device_map="cuda:0",
attn_implementation="flash_attention_2")
3. Initialise the TextStreamer
streamer = TextStreamer(tokenizer,
skip_prompt=True,
skip_special_tokens=True)
4. Tokenise the inputs
tokens = tokenizer(
text,
return_tensors='pt'
).input_ids.to("cuda:0")
5. Generate!
generation_output = model.generate(
tokens,
streamer=streamer,
max_new_tokens=512
)
That's it! 🤗
21
157
927
128,893
Python Piura retweeted

6 Dec 2023
Lo asesino no te lo quitará nadie, lo ladrón tampoco. Y pasarás a la historia como el criminal que eres, que solo
fue liberado por un gobierno mafioso que intenta, para mal del Perú, emular al tuyo.
#Fujimori #FujimoriNuncaMas #IndultoEsInsulto
1,471
131
719
72,884
Python Piura retweeted

3 Oct 2023
La represa de Poechos, la más grande del Perú, fue construida por Velasco en 5 años. Gracias a esta megaobra existe el valle de San Lorenzo, el valle del Piura y el de Cieneguillo, donde se producen la mayor parte de limón, mango y uva de mesa del país.

10
125
324
19,896
Python Piura retweeted

19 May 2023
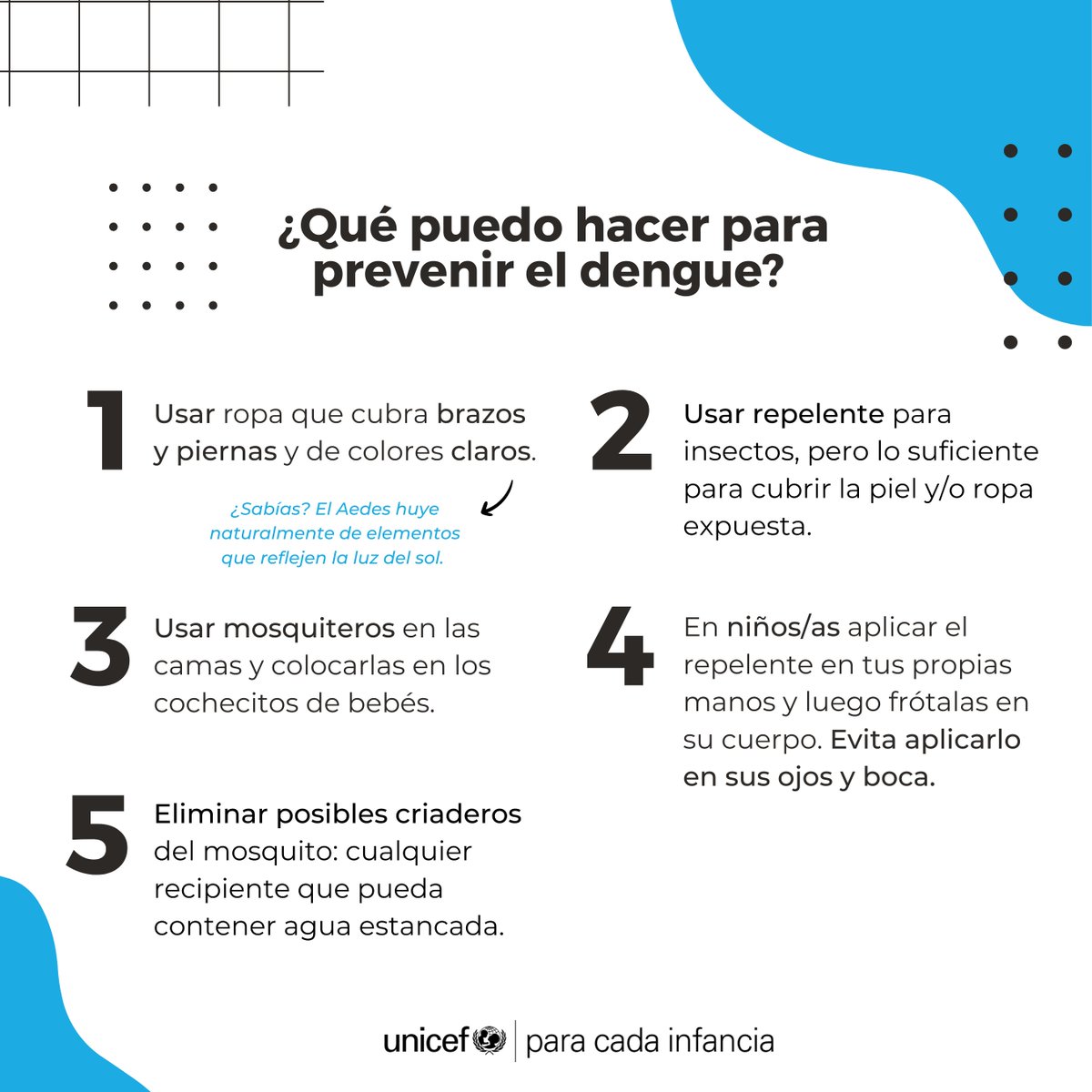
⚠️ 🦟 El #Dengue está aquí. ¿A qué síntomas debemos estar alertas? ¿Cómo podemos evitar el contagio?
👉 No relajemos los cuidados. Sigue estos consejos y cuida a tu familia y a ti del dengue.



20
23
2,676
Python Piura retweeted

21 Apr 2023
ok wow! Atentos a BARK ✨
Un modelo de sintetización de voz capaz de generar voces naturales en múltiples idiomas -algunos idiomas con mejor calidad que otros- y que además...
👉 ES OPENSOURCE 👈
Not perfect, but getting closer!
29
260
1,474
131,575
1 Apr 2023
RT @jfowks: Ciudadano puneño Manuel Quilla falleció anoche, tras quedar inconsciente debido a golpes de la policía en comisaría San Andrés,…
1,067
Python Piura retweeted

30 Oct 2022
Modern Test-Driven Development in Python
testdriven.io/blog/modern-td…
Interested in how TDD works?
This guide walks you through the process, using modern tools and techniques, from start to finish.
by @JanGiacomelli
#Python #Testing #TDD #Flask
24
81
Python Piura retweeted

19 Oct 2022
La recolección de firmas empezó por presión de la DBA de la Coordinadora Republicana, grupo sedicioso de ultraderecha.
Málaga y aliados creyeron que con la denuncia de Benavides se daría el momentum para presionar al bloque de "los niños".
25
202
584
Python Piura retweeted

13 Oct 2022
Chrome es usado por 2.6 billones de usuarios.
Pero mucha gente no sabe sacarle todo su potencial.
10 extensiones de chrome que te harán la vida más fácil (gratis):
309
9,158
35,278
Python Piura retweeted

13 Aug 2022
10 Plataformas donde puedes encontrar un trabajo 100% REMOTO 👩💻🌎
Abro 🧵
732
20,947
96,169
Python Piura retweeted

10 Aug 2022
Empresa anterior: necesito que me ayudes con algunas cosas, cobrame lo que sea.
Yo: Nos conocemos hace años y por primera vez me pides ayuda. Hablemos claro: nunca quisiste mi amistad. Todo iba bien y no me necesitabas.

3
51
478
Python Piura retweeted

8 Aug 2022
Crea un BOT PARA WHATSAPP y dópalo para que tenga mejores funcionalidades o haga uso de la inteligencia artificial.
Disclaimer: este tipo de bots es sólo para usuarios de smartphone con sistema operativo Android. Lo siento por los amantes 🍎
Vamos al lío (perdón al hilo).
🧵
46
742
2,630
Python Piura retweeted

4 Aug 2022
Machine Learning Projects for beginners with source code
in Python😲
A thread 🧵👇
268
3,035
11,853
Python Piura retweeted

11 Jul 2022
10 best free resources to learn Python (2022):
↓
77
1,151
3,831
Python Piura retweeted

11 Jul 2022
GitHub tiene millones de repositorios para aprender programación.
Pero sólo unos cuantos realmente marcan la diferencia.
¡Te comparto los MEJORES!
[ H I L O ] ⇩
266
3,949
14,511