
High-performance Rust-based vector search engine. discord.com/invite/qdrant
Joined December 2020
- Tweets 2,334
- Following 112
- Followers 13,289
- Likes 4,189
1,017 Photos and videos













Pinned Tweet

Mar 12
Most vector databases treat retrieval as a single operation. That's the wrong abstraction.
Storing embeddings and returning nearest neighbors is a solved problem. The hard problem is what happens next. We solve it through composable vector search, built in Rust.
Today, led by AVP, with Bosch Ventures, Unusual Ventures, Spark Capital, and 42CAP, we're announcing our $50M Series B to accelerate it.
Learn more about Qdrant’s composable vector search and our latest funding round here: qdrant.tech/blog/series-b-an…
5
6
25
2,747
Jun 12
Building a retrieval system is one thing. Knowing whether it’s actually good is another.
This practical guide walks through how to evaluate information retrieval systems using a Qdrant-powered retrieval pipeline and Evret.
It covers:
→ Building a retrieval benchmark
→ Measuring retrieval quality
→ Evaluating relevance and ranking performance
→ Moving beyond “it seems to work” testing
As RAG and retrieval systems become more critical in production AI applications, evaluation is becoming just as important as retrieval itself.
Read here:
medium.com/data-science-coll…
4
9
318
Qdrant retweeted

Jun 11
Last night, @Unusual_VC & @qdrant_engine hosted The Retrieval Reckoning, an intimate dinner with 13 engineering leaders building AI systems at scale. A few themes emerged:
→ Data quality remains a bigger challenge than model quality.
→ Retrieval has evolved from a backend feature to mission-critical infrastructure.
→ Observability, governance, and trust are becoming the defining challenges of production AI.
→ The future of agentic systems will be shaped as much by memory and retrieval as by the models themselves.
Excited for the next one!

1
2
9
595
Jun 11
Do larger context windows make vector search obsolete?
This benchmark compares two approaches:
→ Sending large amounts of context directly to an LLM
→ Using a 2-step retrieval pipeline powered by Qdrant to fetch only the most relevant information
The results highlight a key tradeoff many teams face in production:
-> Larger context windows increase cost and latency
-> Retrieval helps reduce the amount of context an LLM needs while maintaining answer quality
As context windows grow, retrieval doesn’t disappear - it becomes even more important for efficiency, scalability, and control.
Read here:
generativeai.pub/the-cost-of…
4
9
674
Jun 10
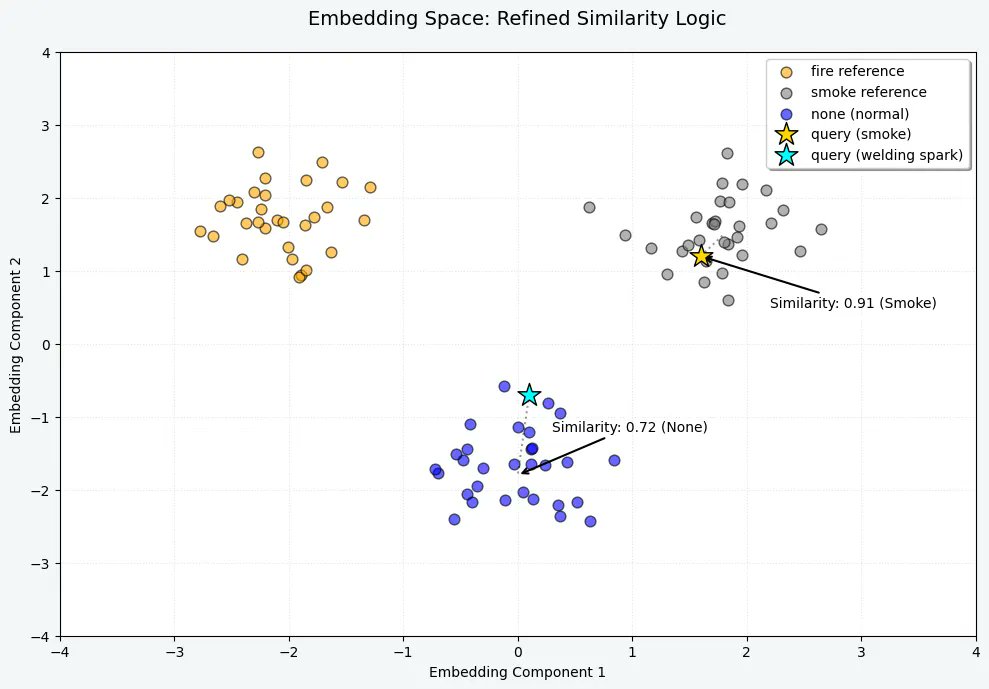
Can you detect a fire without training a custom model?
This project takes a different approach: Edge RAG vector search.
Using Qdrant Edge, the system compares real-time sensor readings against known patterns locally, enabling fast fire detection without the overhead of training and maintaining a dedicated ML model.
Why it’s interesting:
→ No custom model training required
→ Privacy-first, fully local inference
→ Real-time sensor retrieval at the edge
→ Lightweight deployment for resource-constrained environments
Read here:
pub.towardsai.net/fire-detec…

3
8
409
Jun 9
What if your photo gallery could do more than just store images?
This project by Vatsala Singh turns a personal photo collection into an autonomous AI agent using Qdrant as the retrieval layer.
Instead of manually searching folders or scrolling through thousands of images, the agent can:
→ Understand natural language requests
→ Search memories semantically
→ Retrieve relevant photos and context
→ Act as a personal visual memory system
It’s a great example of how vector search with Qdrant transforms static data into something AI can reason over and interact with.
Read more here: ai.gopubby.com/how-i-turned-…
4
9
407
Jun 8
AI doesn’t always need the cloud.
This project uses Qdrant Edge to build a privacy-first SOS detection system that runs locally:
→ Audio embeddings with YAMNet
→ Real-time similarity search with Qdrant Edge
→ Observability with @SignozHQ
A creative use of vector search for real-world safety applications.
pub.towardsai.net/how-i-buil…
3
1
8
384
Jun 6
What does it take to run vector search at the scale of 20 billion vectors?
At Vector Space Day, Oleg Tereshin and Xin Liu from @HubSpot will share the story behind building the infrastructure that powers retrieval at massive scale.
Building the Infra Behind 20 Billion Vectors
Learn how @HubSpot evolved from manual, error-prone @qdrant_engine deployments to a fully automated Kubernetes Operator designed for reliability, scalability, and production operations.
If you’re managing vector infrastructure, operating Kubernetes at scale, or building retrieval systems in production, this is the kind of talk packed with practical lessons.
📍 The Midway, San Francisco 🗓️ June 11
RSVP: luma.com/vsd-sf
4
1
10
470
Jun 5
Fast retrieval is table stakes. Retrieval that respects who's asking, what they're allowed to see, and what policies apply is a much harder problem.
Murthy Chandrapaty and Ankush Gumber from @Adobe are coming to Vector Space Day to show a concrete architecture that solves it: Qdrant's vector search combined with a @neo4j graph governance layer, so agents retrieve fast and stay policy-compliant. They'll demo it live, showing how the same query returns different results for different users based on governance, not just relevance.
If you're building enterprise AI, this is the architecture talk you've been waiting for.
Get your ticket at luma.com/vsd-sf
4
1
7
338
Jun 4
What if you could just tell a robot what to do?
Sandhya Subramani from @awscloud is bringing a live robot demo to Vector Space Day to show exactly that. She'll introduce an open-source agentic framework that exposes physical hardware as programmable agent tools, with a hybrid architecture that keeps low-latency control on the edge and delegates the hard reasoning to the cloud.
Embodied AI, made accessible. June 11 at The Midway, SF. Get your ticket at luma.com/vsd-sf
2
5
231
Jun 4
Just 1 week to go until Vector Space Meetup: Retrieval in the Age of Agents in Berlin.
Everyone is building agents. The real question is: what kind of retrieval do agents actually need?
Retrieval is no longer just about finding the nearest chunks. Modern agents need to decide:
→ when to search
→ what to search for
→ which tools to use
→ whether the retrieved information is sufficient to act on
That’s why we’re bringing together builders from @cognee_, @deepset_ai, @llama_index, and @n8n_io for a panel discussion driven entirely by YOUR questions.
We’ll also be joined by our Co-Founder & CTO @generall931 for a keynote and networking with attendees.
Date: June 11
Venue: @aicampusberlin, Berlin
Register now (approval required): luma.com/vsm-berlin
1
10
425
Jun 3
When you're running GenAI on the edge, you don't get to blame the network.
Alan Zhu from @Qualcomm is coming to Vector Space Day to talk about what it means to build for on-device inference, where latency isn't a tradeoff to manage but the thing users feel with every interaction.
Join 300 AI builders for a full day on agents and memory in production, retrieval from cloud to edge, and multimodal AI. Get your ticket: luma.com/vsd-sf
2
10
354
Jun 3
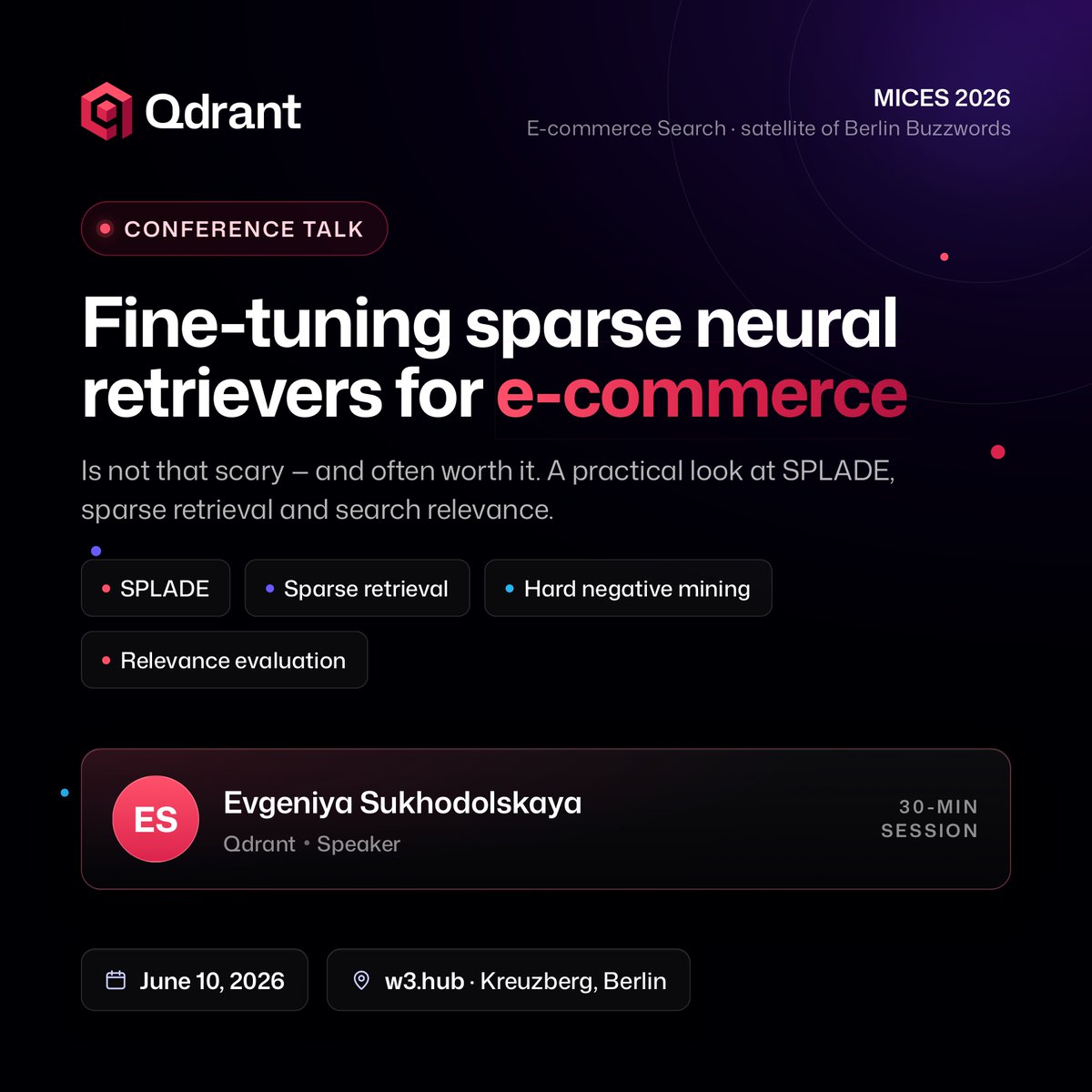
Search is one of the most important parts of the e-commerce experience, and one of the hardest to get right.
That’s why we’re excited to be speaking at MICES 2026, the e-commerce search meetup and official satellite event of Berlin Buzzwords.
@krotenWanderung from Qdrant will present:
“Fine-Tuning Sparse Neural Retrievers for E-Commerce Is Not That Scary (And Often Worth It)” based on @ptdamiba's work!
For more info: qdrant.tech/articles/sparse-…
The session explores the practical side of sparse retrieval and SPLADE:
→ When sparse neural retrieval makes sense for e-commerce
→ Fine-tuning strategies that actually improve relevance
→ Hard negative mining and evaluation
→ Building an end-to-end retrieval pipeline
Date: June 10
Link: mices.co/
3
8
352
Jun 2
Where does AI memory actually live right now? In markdown files, vectors, graphs, a mix of all three? Dave Nielsen from @cognee_ is coming to Vector Space Day to cut through the hype and map out what short and long-term memory look like in real systems today, and where it's all heading.
Vector Space Day is a full-day single-track conference for engineers going deep on retrieval and agent memory. We also have talks on retrieval from cloud to edge, and multimodal AI.
If you’re building something novel in vector search, AI memory, context engineering, or retrieval infra, get your ticket for June 11: luma.com/vsd-sf
2
2
14
546
Jun 1
Video is the most information-dense modality we have, and most retrieval pipelines treat it like text with pictures.
James Le from @twelve_labs is coming to Vector Space Day to show what's actually possible when you build multimodal retrieval right, from semantic search across sports and audio to agentic workflows that handle object tracking and highlight generation at scale.
If you're curious where vector search is heading, this is a session worth being in the room for. Join us at The Midway: luma.com/vsd-sf
1
1
10
401

No plans this weekend? There's still time to compete in our virtual hackathon! Submission deadline is Monday, $10k up for grabs
try.qdrant.tech/hackathon-vs…
2
2
30
2,453
May 30
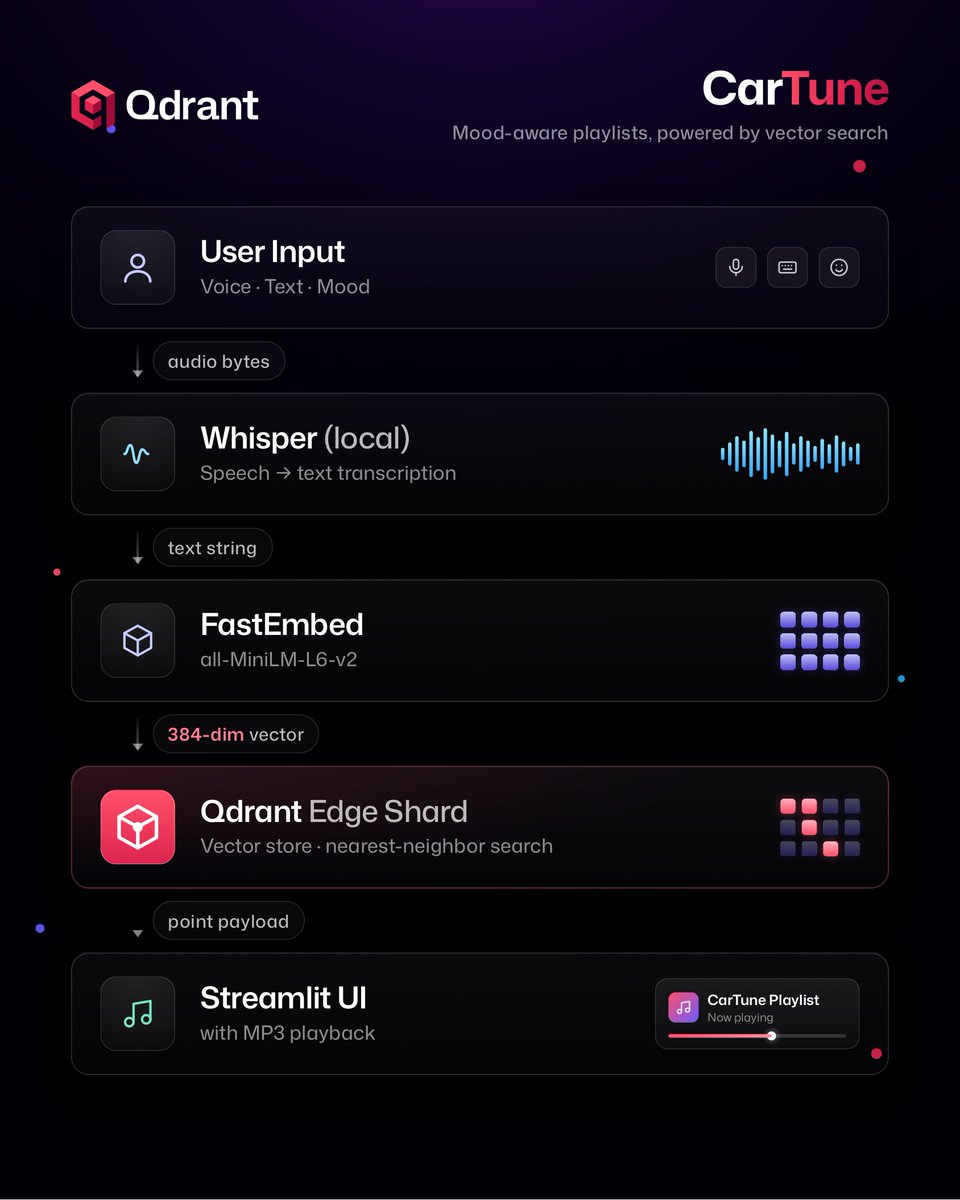
Most in-car media systems still expect you to search with keywords.
But when you’re driving, you don’t think in keywords - you think in moods, vibes, and intent.
This project by Sarvesh Talele, built with Qdrant Edge, creates a fully local AI-powered media discovery system that lets users search music semantically through voice, text, and mood-based queries.
What’s interesting:
→ Local voice transcription with Whisper
→ Semantic retrieval with vector embeddings
→ On-device vector search using Qdrant Edge
→ No cloud dependency required
A great example of how vector search can power privacy-first, real-time experiences directly on-device.
Read here:
levelup.gitconnected.com/how…
5
1
13
495
Qdrant retweeted

May 29
𝗘𝗻𝘁𝗲𝗿𝗽𝗿𝗶𝘀𝗲 𝗔𝗜 𝗰𝗮𝗻𝗻𝗼𝘁 𝘀𝘁𝗼𝗽 𝗮𝘁 "𝗺𝗼𝘀𝘁 𝗿𝗲𝗹𝗲𝘃𝗮𝗻𝘁 𝗿𝗲𝘀𝘂𝗹𝘁."
At Vector Space Day SF, @Adobe and @neo4j will show how governed retrieval, GraphRAG, and context graphs make agents faster, safer, and more explainable.
Register: luma.com/vsd-sf

3
8
1,070
May 29
Tweaking chunk sizes and running a few demo queries is not an evaluation strategy.
Laurie Voss (Head of DevRel, @arizeai) is coming to Vector Space Day on June 11 to replace vibes with measurement: the retrieval metrics that matter, golden datasets that survive contact with reality, and how to wire evals into CI so you find out about regressions before your customers do.
If you’re building something novel in vector search, AI memory, context engineering, or retrieval infra, check out Vector Space Day on June 11 at The Midway: luma.com/vsd-sf
3
8
245
May 29
Berlin folks 🇩🇪
Join us for an evening focused on AI retrieval, agents, and modern search systems.
We’ll be at the event below discussing how retrieval is evolving in the age of agents, production RAG, memory systems, and vector search: luma.com/shfil13j
And we’re not stopping there - later the same day, we’re also hosting our Vector Space Meetup: Retrieval in the Age of Agents at the same location!
Expect great discussions, networking, and builders from across the AI ecosystem.
Meetup link: luma.com/vsm-berlin
See you in Berlin 🙌
3
9
2,898
May 28
About 90% of enterprise data is unstructured, and most of it lives in documents. PDFs, spreadsheets, Word files, the stuff that runs businesses. Preston Carlson from @llama_index is coming to Vector Space Day to talk about why even frontier models struggle with real-world documents, and what better OCR and agent harnesses actually unlock.
Vector Space Day is a full-day conference for engineers building the next generation of retrieval systems. Get your ticket for June 11 at The Midway, SF:
luma.com/vsd-sf

1
4
233