
10 Photos and videos








@qtl retweeted

17 May 2024
📢 Interested in new phenotypes for feed efficiency in aquaculture? 📢 We are hiring a fully salaried PhD in genetics of FE in Atlantic salmon 🧬🐟 @UniNMBU 🇳🇴 #PhD #PhenotypeIsKing. Please RT. 📅 deadline 5 June 24 jobbnorge.no/en/available-jo…
1
9
19
1,243
@qtl retweeted
11 May 2023
Are you our new collegue? We are hiring a fully fund PhD in simulation tools for managing genetic diversity 🧬🐄🐟 @UniNMBU 🇳🇴 #PhD.Please RT! jobbnorge.no/en/available-jo…
11
16
1,351
@qtl retweeted

8 Feb 2023
The 3 year wait is over... in-person Early Bird @JuliaConOrg 2023 tickets are now on sale 🎉:
juliacon.org/2023/tickets/
7
32
79
34,814



It is very nice to have @GregorGorjanc to talk about his AlphaSimR in Ås. In the end he praised tree sequence storage a lot. This reminded me that I had a similar idea 11 yrs ago (xijiang.blogspot.com/2011/11…). Unfortunately, I still don't know graph theory.
1
2
8
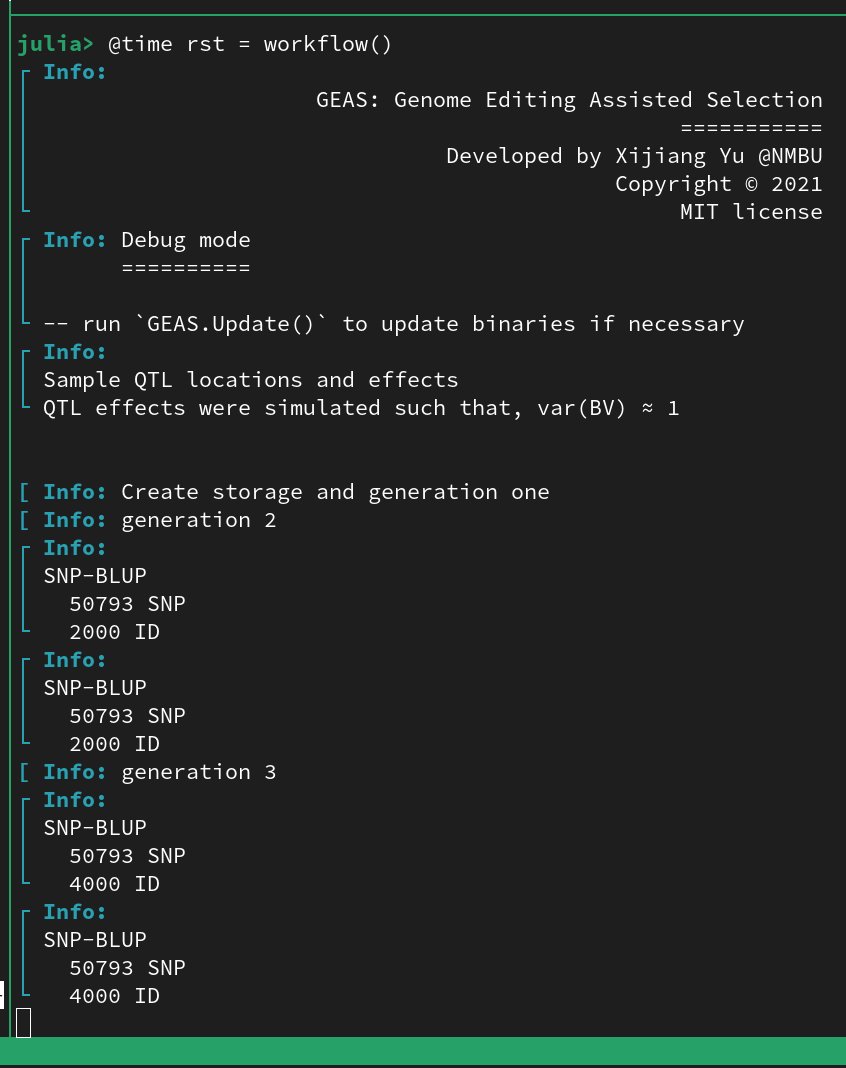
Managed to deal with SNP matrix(50k x 400k), LHS of 50k x 50k with only ~20G peak memory usage. Paralleled of course. W/O the @JuliaLanguage, it can't be this compact and this fast.
1
Please also mention Mr. Wong(王家禧) plagiarized Pengdee(朋弟/冯棣). The cartoon first appeared in 1930s. x.com/CNN/status/81627441690…

Alfonso Wong, the creator of "Old Master Q," one of Asia's best-known comic strips, has died at the age of 93 cnn.it/2j4aeRM

果然有党魁要求重新计票了。 x.com/CNN/status/80178972382…
Green Party nominee Jill Stein launches a bid to seek a recount in three Rust Belt states cnn.it/2fv0RI8
