
machine yearning engineer @hf0
Joined August 2025
- Tweets 374
- Following 1,514
- Followers 958
- Likes 31,392
44 Photos and videos










Pinned Tweet

Mar 3
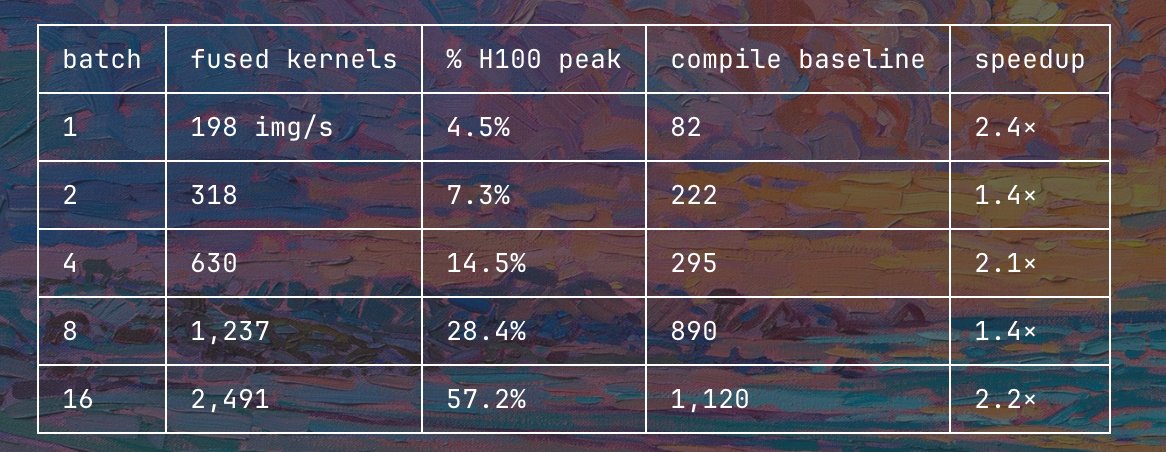
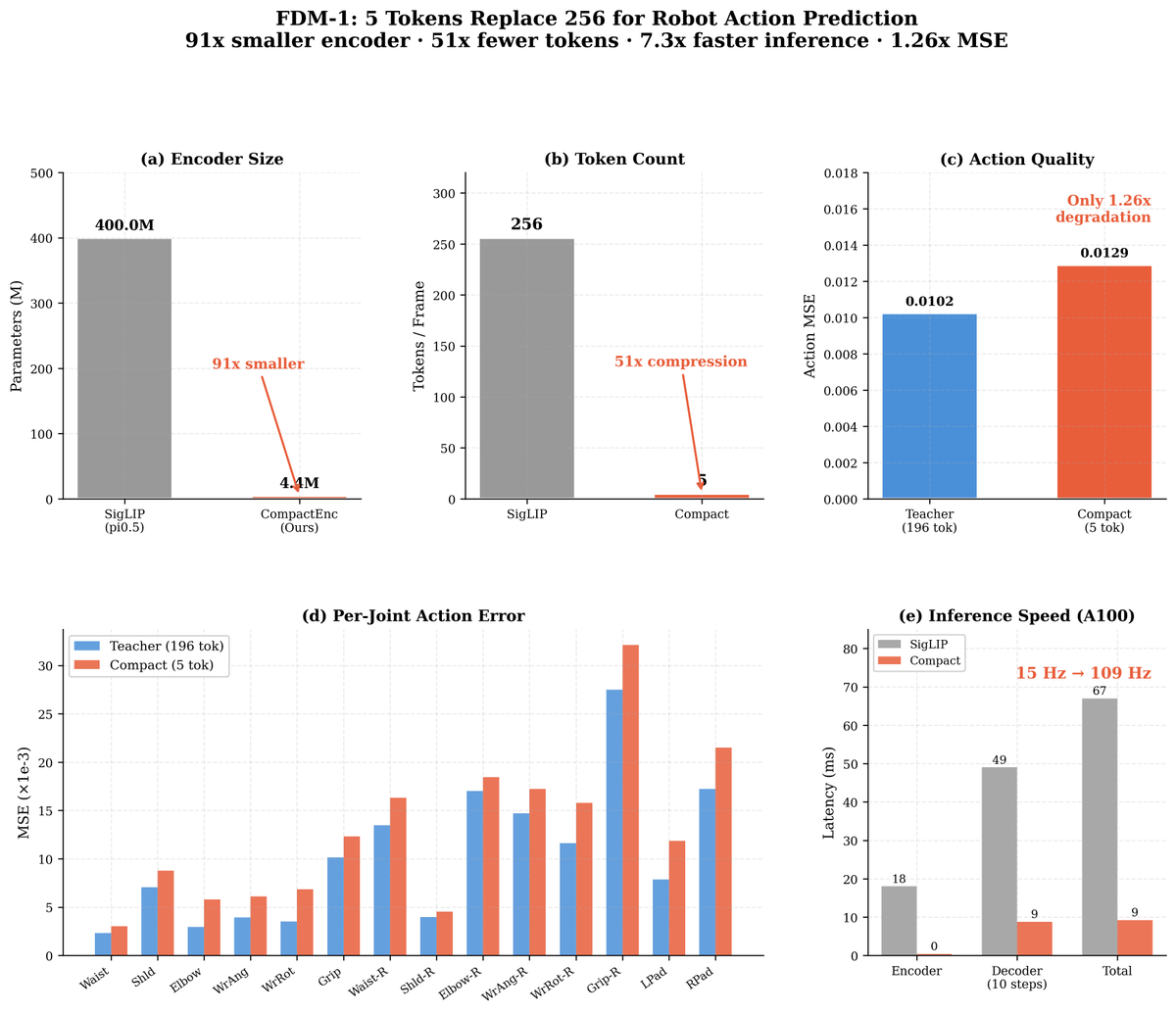
Robot action models shouldn't need 256 vision tokens per frame.
Pi0.5 spends 400M parameters on SigLIP just to see. We replaced it with a 4.4M encoder that
outputs 5 tokens — and action quality barely changes.
91x smaller. 51x fewer tokens. 7.3x faster inference.
22
32
374
23,866
12h
Most useful thing rn is to diffuse ai into the economy kinda like Neo-intergrators and harvesting all the data
2
2
153
Jun 12
People often get too hung up on happiness instead of the pursuit, in the pursuit of happiness
1
6
289
Jun 12
Plan for this summer: create a generational company, find the loml
1
16
828
Lucas retweeted

Jun 12
A key lesson I have learned is that sense of urgency is often a better predictor of success than pedigree of school or GPA
22
102
1,864
60,909
Jun 12
my cofounder kicked me out of our studio to fly in his girl so I was also homeless that time
3
18
16,150
Jun 11
my phone died right before getting into my waymo, walk of shame across SF sitting in cafes trying to figure out a way home
1
4
319
Jun 11
Smartest moves rn are to diffuse AI into the economy or compete where the foundational labs can’t
2
1
181
Jun 11
Another homeless story: slept and ate at hackathons and really got inspired by hopeful vibes
1
4
469
Jun 11
if you're spending > $100M / year on VLM inference and aren't a reflex customer yet, please DM me
11
50,240
Jun 10
We got accepted into @hf0!
This happened 2 months ago just wanted to remind everyone
17
83
5,994
Jun 10
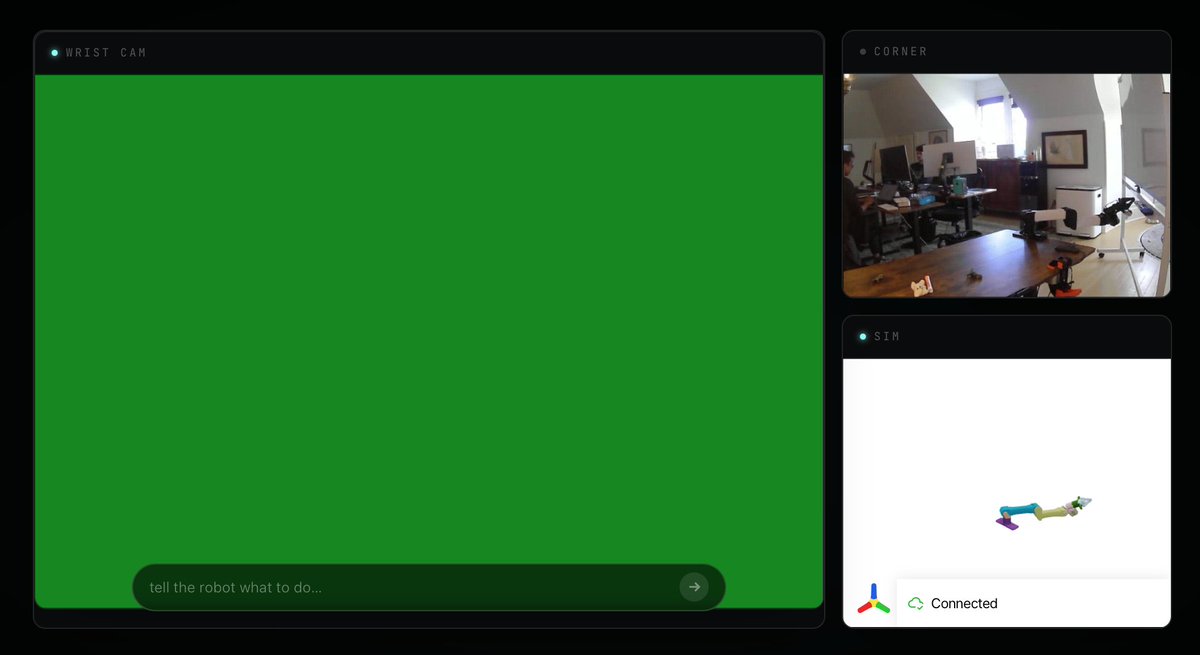
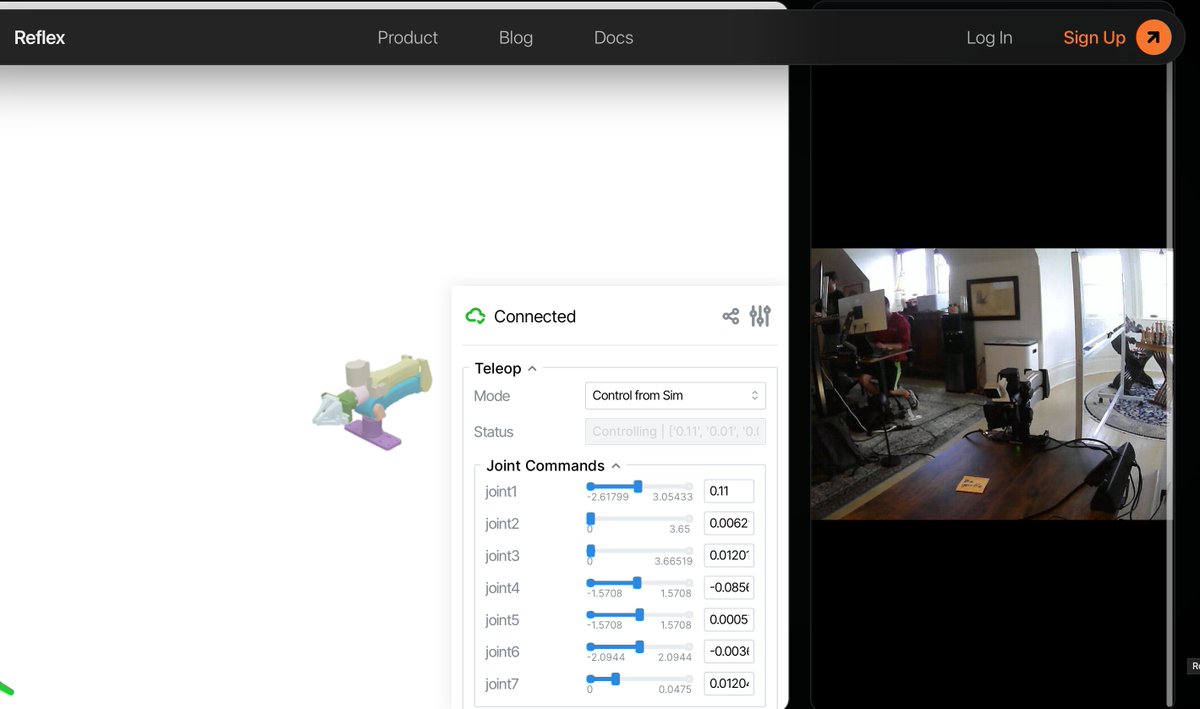
Try commanding our robots to do whatever you want! streaming 24/7 on our website
1
5
376
Jun 10
One time I couldn’t find a place to sleep in the sf homeless arc I went to a salsa bar and danced my sorrows away until a torta gave me a couch
1
6
384
Jun 10
One time I couldn’t find a place to sleep in the sf homeless arc I just stayed up all night roaming golden gate park
2
15
1,385