
好きな男→寺山修司/太宰治/John Lennon/三島由紀夫/安部公房/細野晴臣/Truman Capote/六曜社地下のマスター/革靴をきれいにはいてる人/ 2022年春頃からなぜか英語の勉強開始→〜2022年英検3級→22年末に2級合格→24年は準1級合格目標(合格💮)→1級受験中
Joined July 2007
- Tweets 1,526
- Following 294
- Followers 54
- Likes 3,552
184 Photos and videos
















Pinned Tweet

1 Jun 2024
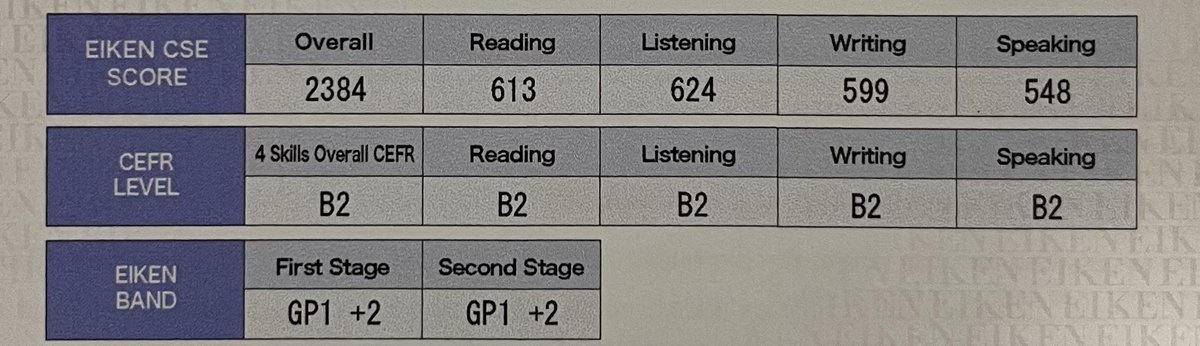
明日は #英検準1級 受験日。
実は前回の受験で合格しました💮✨ただすぐに1級を受験しても合格できないレベルのため、先ずは準1級の得点を伸ばしたいです。ご覧の通り余地はある…笑
2
2
345

rabbit retweeted

May 13
清澄白河の読書が捗る空間でDJをするのはある意味、ナイトクラブとは真逆で面白い。
未だに1回限りのイベントと勘違いされるけど、次で14回目。まだまだ地域に定着するには時間が必要かなあ。
3
157
3,129
352,564



rabbit retweeted

Apr 12
速報で流れてきた「ソフトバンクやNECが国産AI新会社設立」というニュース、数字だけ見ると「またIT企業の話か」で終わりそうですが、これは日本の製造業と私たちの税金に直結する話なので、少し丁寧に整理してみます。
まず事実関係から。設立された新会社の名前は「日本AI基盤モデル開発」。中核を担うのはソフトバンク、NEC、ホンダ、ソニーグループの4社で、それぞれ十数%ずつ出資します。そこに100人規模のAI開発者が集まり、国内最大級となる「1兆パラメーター」の大規模AIモデルを開発する計画です。
「パラメーター」というのは、簡単に言うとAIの賢さを示す目盛りのようなものです。数が多いほど複雑な判断ができる。ChatGPTで有名なGPT-4は推定1.8兆パラメーター程度と言われていますから、今回の1兆という目標は「世界一」ではなく「世界トップクラスに追いつく」水準です。それでも国内では最大規模。出発点としては相当に本気の数字です。
では政府はどう関わるのか。経済産業省は2026年度から5年間で総額1兆円規模の公的支援を計画しており、今年度予算案には関連経費として3000億円程度を計上する方向です。財源はGX経済移行債、つまり国民が将来返済する借金の一部が充てられます。税金が動く話である以上、私たちには「これは正しい使い方か」を問う権利があります。
重要なのは役割分担です。ソフトバンクとNECがAIの基盤モデルそのものを開発し、ホンダが自動車や工場ロボット、ソニーがゲームや半導体の分野でそのAIを使う設計になっています。「作る側」と「使う側」が最初から同じ会社グループにいる。これが今回のスキームの核心です。
なぜ今なのか。背景にあるのは、日本の製造業が積み上げてきた「産業データ」の流出懸念です。工場の設備がどう動くか、機械がどのタイミングで故障しやすいか、部品の精度をどう調整するか。こういった現場のノウハウは、これまで職人の頭の中や紙のマニュアルに眠っていました。AIを使えばこのデータを学習させて工場を自動化できる。しかし問題は、そのデータをChatGPTやGoogleのAIに学習させると、データそのものが米国企業のサーバーに渡ることになるという点です。
軍事技術や先端半導体の製造ノウハウが、知らないうちに外国のAIの「賢さ」に転用される可能性がある。これを防ぐために国産のAIが必要だというのが、政府と産業界の共通認識です。「フィジカルAI」という言葉が今回のキーワードで、ロボットや工場機械をAIで自律制御する領域では、まだ米国や中国が圧倒的な優位を持っていない。そこに日本の勝機があるという読みです。
ソフトバンクは2026年度から6年間でデータセンターに2兆円を投じる計画で、旧シャープの堺工場を国産AIの計算拠点として整備します。国内でAIを学習・推論させることで、データが国外に出ない環境を整える狙いです。
ただし冷静に見なければならない点もあります。AIを動かす高性能半導体(GPU)はNVIDIA製、つまり米国製です。「国産AI」とは言いますが、その心臓部は依然として米国製の部品に依存しています。本当の意味でのデータ主権を語るならば、半導体の国産化という次の問いが避けられません。
また過去を振り返ると、1980年代に日本政府が主導した「第5世代コンピュータプロジェクト」は、数百億円の国費を投じながら商業的な成果をほとんど残せませんでした。あの失敗の教訓から今回は「毎年評価し、成果が出た場合のみ追加投資」という段階的な支援設計を採用しています。税金の垂れ流しを防ぐ仕組みは確かに前進していますが、仕組みが良くても人材と実行力が伴わなければ結果は変わりません。
100人という開発体制についても注意が必要です。OpenAIやGoogleのAI研究チームは数千人規模で動いています。国内最大とはいえ、グローバル競争の文脈で「十分な規模か」は率直に問うべきです。
それでも私は、この動きを「遅すぎた一歩」ではなく「間に合うかもしれない一手」として評価しています。理由は単純で、フィジカルAIという領域はまだ黎明期だからです。製造業の現場データを最も豊富に持つ国が、ここでAI開発の主導権を握れれば、工場の自動化から医療ロボット、建設機械まで幅広い産業で日本発の技術が世界標準になり得ます。
問題は実行です。設立の発表と実際の成果の間には、いつも大きな溝があります。この新会社が3年後にどんな成果を示しているか。それを私たちが問い続けることが、1兆円の税金を守ることにもつながります。
Apr 12

【速報】ソフトバンクやNECが国産AI新会社設立
47news.jp/14140411.html?utm_…
34
581
2,568
624,331
rabbit retweeted

Mar 29
これ、腰痛とか座骨神経痛に悩んでるならマジで保存版。家で数分やるだけで体が軽くなるの、神すぎるw
17
963
9,203
1,325,267
rabbit retweeted

Mar 22
この小鳥の鳴き声は432Hzの周波数。
この音はセロトニンなどの幸せホルモンの放出を助け、血圧や心拍数を自然に整えてくれる。
142
6,952
42,619
1,520,624
rabbit retweeted

Feb 14
超欲しい
doublet x beta post 26SS マグロ型トートバッグ『TUNA HEAD BAG』が国内発売開始 [26SS70BG79]|UP TO DATE uptodate.tokyo/doublet-x-bet…


367
15,114
52,537
4,254,602

rabbit retweeted

🆕マルタン・マルジェラの日本初となる大規模個展が、東京・九段ハウスで開催へ。
tokyoartbeat.com/articles/-/…
会場は1927年竣工の洋館を改修した登録有形文化財。歴史的邸宅を舞台に、多様な作品群を展示する。
会期は4月11日〜29日

4
744
3,663
290,745
rabbit retweeted

Jan 30
【今週の #日曜美術館】#日美50
放送開始50年記念、名作ノーカット放送の第1弾!
1977年放送の「私とマグリット 寺山修司」
劇作家の #寺山修司 が、舞台人の視点から、マグリットのシュルレアリスム絵画の不可思議な世界の魅力を語る。
Eテレ 2月1日(日) 午前9:00
one.nhk/nichibi/


4
748
2,410
131,129
rabbit retweeted

Jan 27
AIで映像化されたモネの世界。名画を映像に変換するのはよくある手法だけど、不思議とこの映像は心地よく見れる気がする。
17
2,013
17,706
627,821
rabbit retweeted
Jan 25
【来週の #日曜美術館】#日美50
放送開始50年記念、名作ノーカット放送の第1弾!
1977年放送の「私とマグリット 寺山修司」
劇作家の #寺山修司 が、舞台人の視点から、マグリットのシュルレアリスム絵画の不可思議な世界の魅力を語る。
Eテレ 2月1日(日) 午前9:00
one.nhk/nichibi/


12
3,360
9,504
632,077
Jan 25
#英検1級 4回目を上智大学で受験📚
前回から成長してない。。ニュース、オンライン英会話、問題集とか毎日英語には触れてるけど、もうひとつレベル高い語彙とか文章から逃げてるから変わらない
変わってかないと🐱
全然話変わるが試験後の外、とんでもなく寒かった❄️
地道にすすむ
2
102
rabbit retweeted

Jan 12
Video message from Federal Reserve Chair Jerome H. Powell: federalreserve.gov/newsevent…
19,455
45,692
244,785
89,663,695

漫画家・魚喃キリコさん死去 52歳
1年前に亡くなっていた
oricon.co.jp/news/2427403/fu…
魚喃キリコ(なななん きりこ)さんは1993年『HOLE』(月刊漫画『ガロ』)でデビュー。代表作『blue』『南瓜とマヨネーズ』『strawberry shortcakes』『Water.』はいずれも映画化された。

66
3,226
6,458
1,363,176
rabbit retweeted

10 Dec 2025
[明日から開催] 「東京アートブックフェア 2025」東京都現代美術館にアート書籍やジンが集結、イタリア絵本展示も fashion-press.net/news/13931…
7
42
146
127,297
rabbit retweeted

【TOKYO ART BOOK FAIR 2025完全ガイド】主催マネージャーが語るアートブックフェアの見どころと楽しみ方
pen-online.jp/article/020238…
5
4
2,086

どうぞよろしくおねがいします☺🌿

/
今年も帰ってきました!
♨ドラマ「#サ道2025SP ~ぬくもりに思いを馳せ ととのう~」♨放送決定!
\
#原田泰造× #三宅弘城 出演
12月30日(火)夜11時30分〜放送!▶︎▶︎
今年はどこのサウナ施設で蒸されるのでしょうか。
放送までお楽しみに♪
tv-tokyo.co.jp/sa_una37_2025…

68
693
46,021


rabbit retweeted

27 Nov 2025
「テート美術館 ― YBA & BEYOND 世界を変えた90s英国アート」 @ybabeyond
齋藤飛鳥さん& 細野晴臣がアンバサダー就任🇬🇧
音声ガイドをはじめ、さまざまな形で90年代英国アートの魅力をナビゲートします。また、細野は本展の巡回先でもある京都市京セラ美術館 中央ホールにて、2025年12月にスペシャルライブを開催することも決定しています。
展覧会名: テート美術館 ― YBA & BEYOND 世界を変えた90s英国アート
英語名: YBA & BEYOND: British Art in the 90s from the Tate Collection
【東京展】
会期: 2026年2月11日(水・祝)〜2026年5月11日(月)
会場: 国立新美術館 企画展示室2E(東京都港区六本木7-22-2)
休館日:毎週火曜日
※ただし2026年5月5日(火・祝)は開館
開館時間:10:00~18:00
※毎週金・土曜日は20:00まで
※入場は閉館の30分前まで
主催: 国立新美術館、テート美術館、ソニー・ミュージックエンタテインメント、
朝日新聞社
協力:日本航空、ヤマト運輸
後援:ブリティッシュ・カウンシル、J-WAVE
一般のお問合せ:050-5541-8600(ハローダイヤル)
*巡回情報
【京都展】
会期: 2026年6月3日(水)〜2026年9月6日(日)
会場: 京都市京セラ美術館 新館 東山キューブ(京都府京都市左京区岡崎円勝寺町124)


1
89
592
49,172