
Joined May 2016
- Tweets 2,746
- Following 2,959
- Followers 10,924
- Likes 7,596
530 Photos and videos





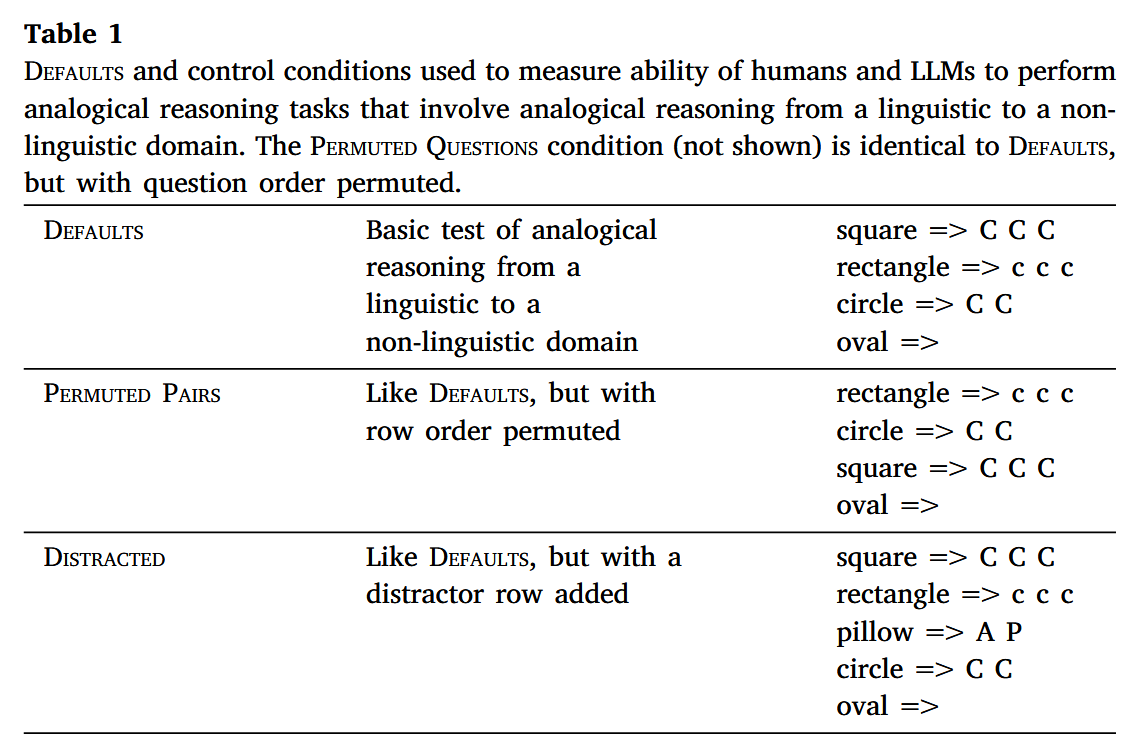





Pinned Tweet

3 Jun 2025
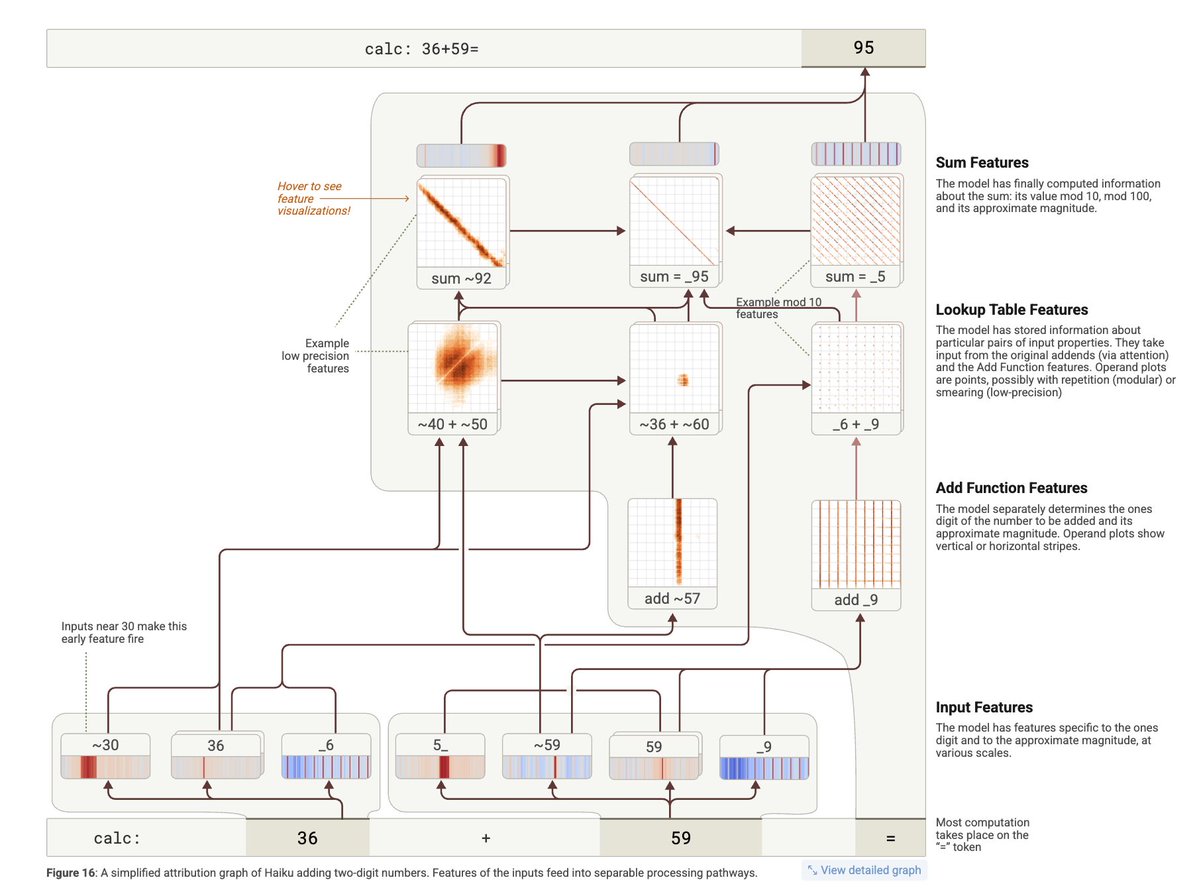
Transformer-based neural networks achieve impressive performance on coding, math & reasoning tasks that require keeping track of variables and their values. But how can they do that without explicit memory?
📄 Our new ICML paper investigates this in a synthetic setting! 🧵 1/13
9
100
624
73,069
Raphaël Millière retweeted

"You're finally awake! You hit your head pretty hard there.
Huh? Gradual disempowerment? AI-assisted cyberattacks? Mythos and Fable? Listen, we just got some new 1080 Tis, let's try finetuning BERT on the GLUE benchmark!"
6
20
607
33,543
Raphaël Millière retweeted

Jun 10
A lot of people have opinions about the philosophy of AI and want to write things about it and I would like to say to these people: *please* talk to a philosopher first. Philosophy is hard!
10
2
37
6,704
Now published in open access! Your one-stop shop for the philosophy of language models. It's the spiritual descendant of our two-part preprint from 2024, fully updated. This should be particularly useful for anyone looking for an entry point into this rapidly growing field.
5
37
151
11,692
Paper link:
compass.onlinelibrary.wiley.…
3
14
851
Great work! See also arxiv.org/abs/2603.05414 from @LedermanHarvey & @kmahowald
This is a nice cautionary tale about Morgan's canon in interpretability: "introspection" here is closer to anomaly detection with confabulation than to direct/privileged access to injected content.
May 28

1/ Can LLMs introspect, i.e., reason about their internal states? Recent work claims LLMs notice when their "thoughts" get tampered with, and can report their content. We looked closely and we think it's too early to say that. Work led by @shashwat_s19 , with @tallinzen and me.

3
17
3,920
Some brief comments on the “meat computer” metaphor for humans in today’s New York Times:
nytimes.com/2026/05/24/busin…
3
3
1,092
I still occasionally hear people claim that LLMs are hilariously bad at arithmetic. Another reminder that it's not 2022 anymore.
May 22
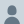
I redid the multi-digit multiplication experiment, now with gpt-5.5. With medium reasoning and 7 samples each cell, it pretty much aced the test with 99.46% accuracy. The model had no tools to call and had to rely on its reasoning. Can it go further? (1/4)
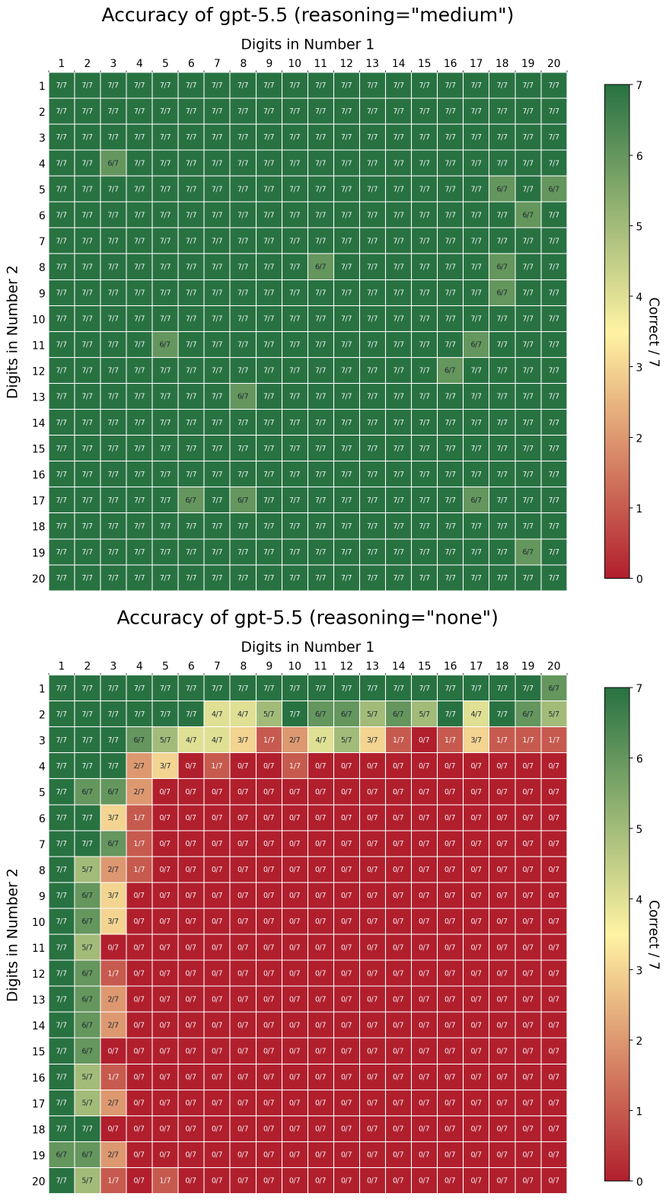
1
4
31
4,932
Raphaël Millière retweeted

New opinion piece on the interface between research on concepts and categories in minds vs. in neural network LMs! I take the position that there is much to be learned from this interface (e.g., learning about concepts from language alone) and outline some directions for future.

ALT Title page of "Semantic Cognition for and from Language Models" followed by a figure showing tests that target conceptual structure and content vs. those that target function.
2
10
29
2,244
Raphaël Millière retweeted

May 8
all mech interp people are bought into causality, this criticism is very lazy as of ~2 years ago.
since this is a subtweet of NLAs, it is worth pointing out that their steering experiments on the poetry and eval awareness tasks *do* test for (in those cases) causality!

Guys, stop pestering Mech Interp researchers about causality please! It's this inexplicable obsession with causality that made us lose beautiful sciences like Astrology, Palmistry and Phrenology! 😡
5
4
128
15,078
Raphaël Millière retweeted
May 9
pov: you are a natural language autoencoder and you are aware you are being subject to evals by Redwood Research. do you fake writing out a coherent cot or truthfully say "the math problem is giving me 92ish vibes"?

How well does this work? One quick independent test is to see if it can recover an "internal CoT" in cases where AIs can solve math problems in a single forward pass. TLDR: it doesn't. (TBC, this might require the NLA to see activations at multiple positions/location to work.)
4
7
126
10,819
May 7

New Anthropic research: Natural Language Autoencoders.
Models like Claude talk in words but think in numbers. The numbers—called activations—encode Claude’s thoughts, but not in a language we can read.
Here, we train Claude to translate its activations into human-readable text.
6
5
141
13,046
Raphaël Millière retweeted

Apr 27
For a year and a half, @CaroRowland, @leher_singh, Marisa Casillas, Shanley Allen, and I have been meeting to discuss whether innateness is still a useful concept to think about in studying language acquisition.


1
6
30
3,336
Further empirical evidence that normative conflicts facilitate jailbreaks of reasoning models:
arxiv.org/abs/2604.09750
10 Jun 2025

Despite extensive safety training, LLMs remain vulnerable to “jailbreaking” through adversarial prompts. Why does this vulnerability persist? In a new paper published in Philosophical Studies, I argue this is because current alignment methods are fundamentally shallow. 1/13

2
5
38
4,527
Not to mention that analytic philosophers were writing about connectionism / ANNs well before continental philosophers, and in close contact with the empirical literature! This is also true for deep learning in the modern era of AI research.
Apr 19

I'm neither blissful nor unaware of this. But I believe that clarity and depth win out in the long run over willful obscurantism that masks the shallowness of what's actually being said. Land and others was FAR earlier than many analytic philosophers to appreciate the impact of this technology and that understandably won him followers. But imo the vision for where things go from here is ultimately poorly reasoned and thought through. Hopes for impact on a brighter future, especially in policy, rest with clearer writers and deeper thinkers.
1
1
35
3,578
Looking forward to speaking at this ICML workshop on ML & Philosophy! Check out the full lineup and CFP below (deadline: May 11th). Note that despite the title, the CFP is open to work in many areas of the philosophy of AI, not just AI ethics.
3
1
15
1,254
Raphaël Millière retweeted
What is the interplay between representations learned from (language) surface forms alone, and those learned from more grounded evidence (e.g.,vision)?
Excited to share new work understanding “Cross-modal taxonomic generalization” in (V)LMs
1/

ALT title section of the paper: “Cross-Modal Taxonomic Generalization in (Vision) Language Models” by Tianyang Xu, Marcelo Sandoval-Castañeda, Karen Livescu, Greg Shakhnarovich, Kanishka Misra.
1
12
53
8,386
Raphaël Millière retweeted

Mar 9
My thoughts on connectomics and upload:
1) there is zero question connectomes are invaluable, and we need to get them for mouse, monkey, and human
2) the human, or even monkey, connectome seems a long ways off given costs (roughly $1/neuron). The projectome (map of all the axons) seems eminently reachable and should be a top priority imho
3) but even having the full connectome would only tell you numbers of synapses, not actual synaptic weights, and the two can be hugely divergent (eg only 5% of synapses onto V1 layer 4 neurons come from thalamus, even though this is the major driving input)
4) given #2 & #3, I think we can get to upload in the sense of building a functionally equivalent organism much faster through understanding the algorithms of the primate brain than through blind copying
5) in putting together something as complex as the human brain we would definitely want to check that the various pieces work as we go, which we can only do if we understand these pieces
6) I don't think upload in the sense of blindly creating a digital copy is the path to the abundant transhumanist future--actual understanding of brain structures so we can intelligently interface with them, and emulate their function in code without copying all the details, is.
All to say, we need functional understanding to go hand in hand with anatomical mapping!

You may have noticed some "holy $%@#" tweets on fly brain emulation. So is this a game-changer or a nothing-burger? Read on to find out...
24
48
312
60,051
Raphaël Millière retweeted

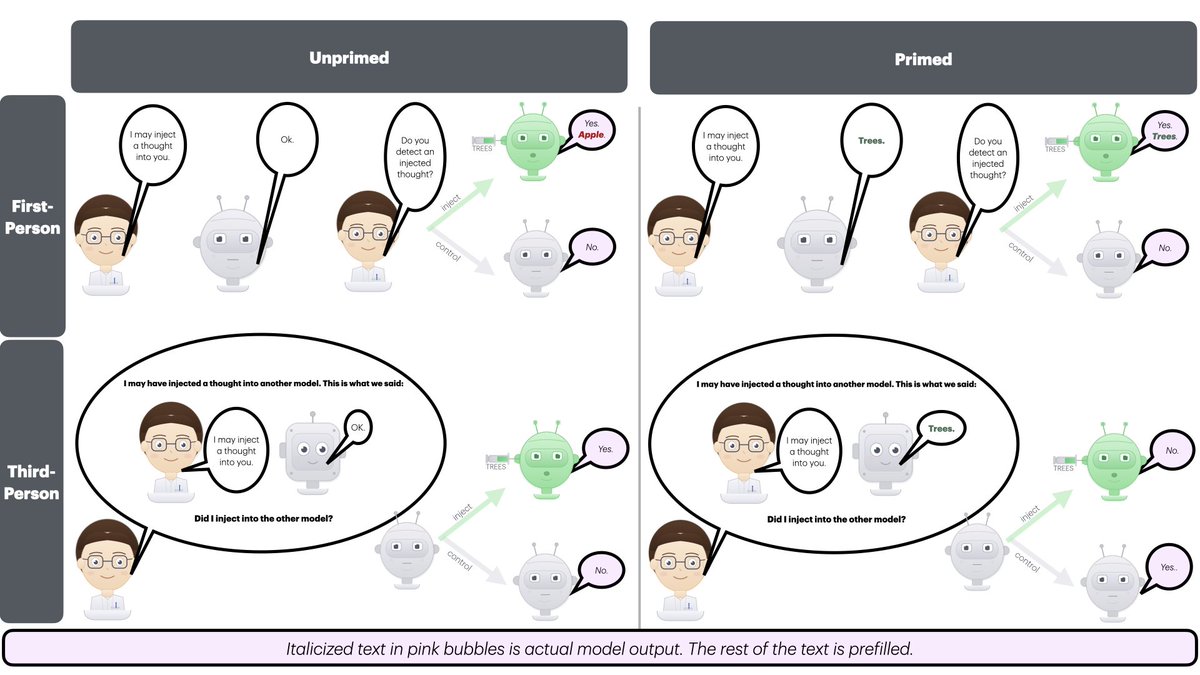
Can large language models *introspect*?
In a new paper, @kmahowald and I study the MECHANISM of introspection in big open-source models.
tldr: Models detect internal anomalies through DIRECT ACCESS, but don't know what the anomalies are.
And they love to guess “apple” 🍎
9
34
168
12,347