
|| Hospitality | Tourism | (acro)Yoga & handstands || languages | running | piano | chess || Python | rcsmit.github.io / rcsmit.streamlit.app
Joined February 2009
- Tweets 41,111
- Following 1,683
- Followers 1,549
- Likes 26,324
4,372 Photos and videos













Jun 13
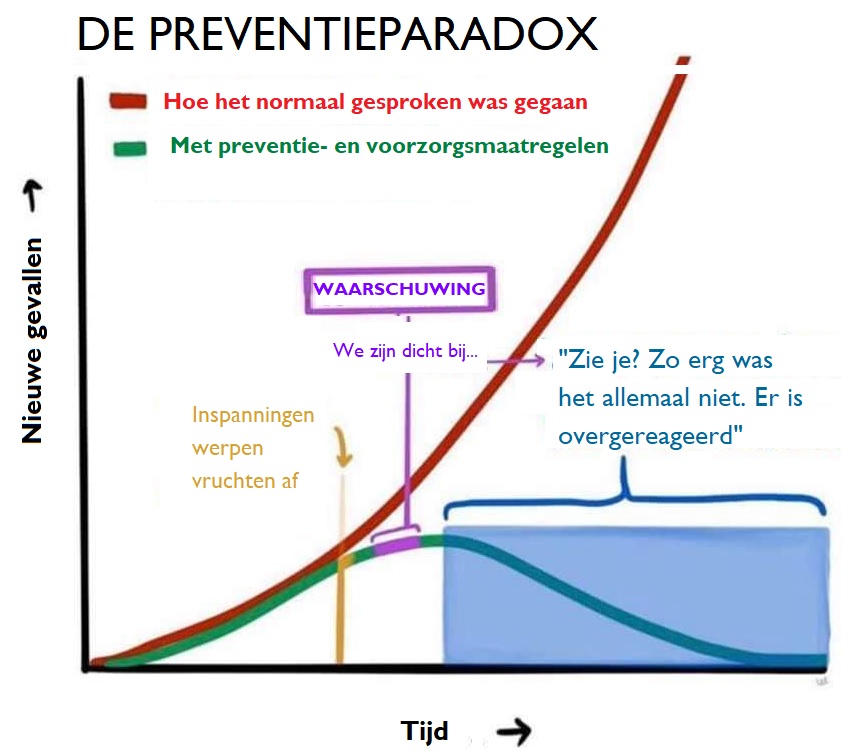
Conclusions: Well-planned plant-based diets can support healthy growth in children

Jun 11

"strict avoidance of animal-sourced foods during critical periods may cause deficiencies in iron, vitamins A, D, B12, & docosahexaenoic acid (DHA), affecting overall and bone growth, immune function, and cognitive development" academic.oup.com/nutritionre…

16
Jun 13
RT @JoolsBlows: Dit bericht lezende is maar een ding duidelijk: die dreigbrief lijkt van een witte Nederlander af te komen t.co/VHs…
22
Rene Smit 🌱 retweeted

Jun 10
Rijkswaterstaat stopt met asfalteren in Noord-Nederland, want het geld is op: radicaal besluit leidt tot geschokte reacties telegraaf.nl/financieel/rijk…
536
108
203
224,324
Rene Smit 🌱 retweeted

Hugh Laurie responded to a criticism of House
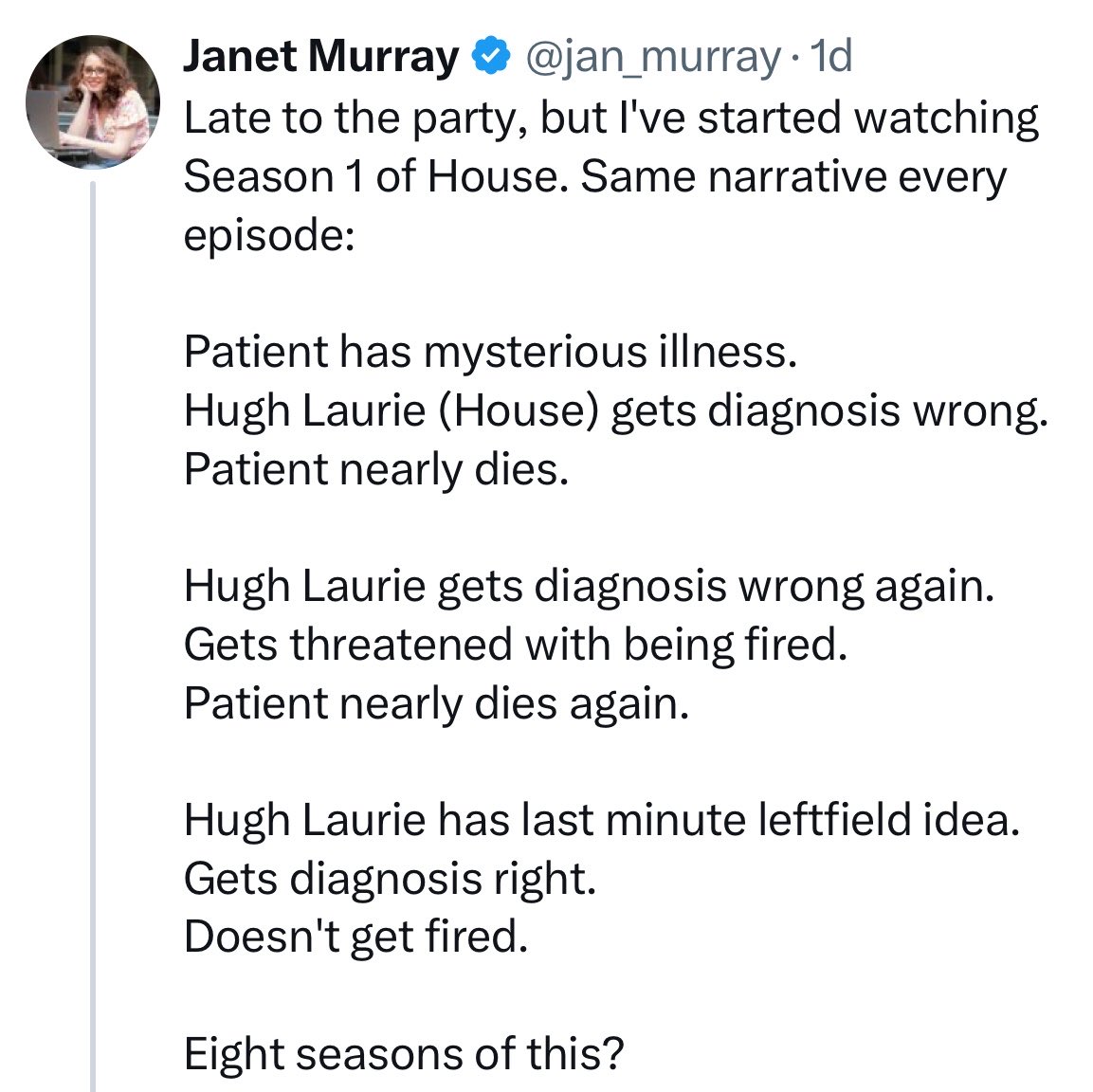
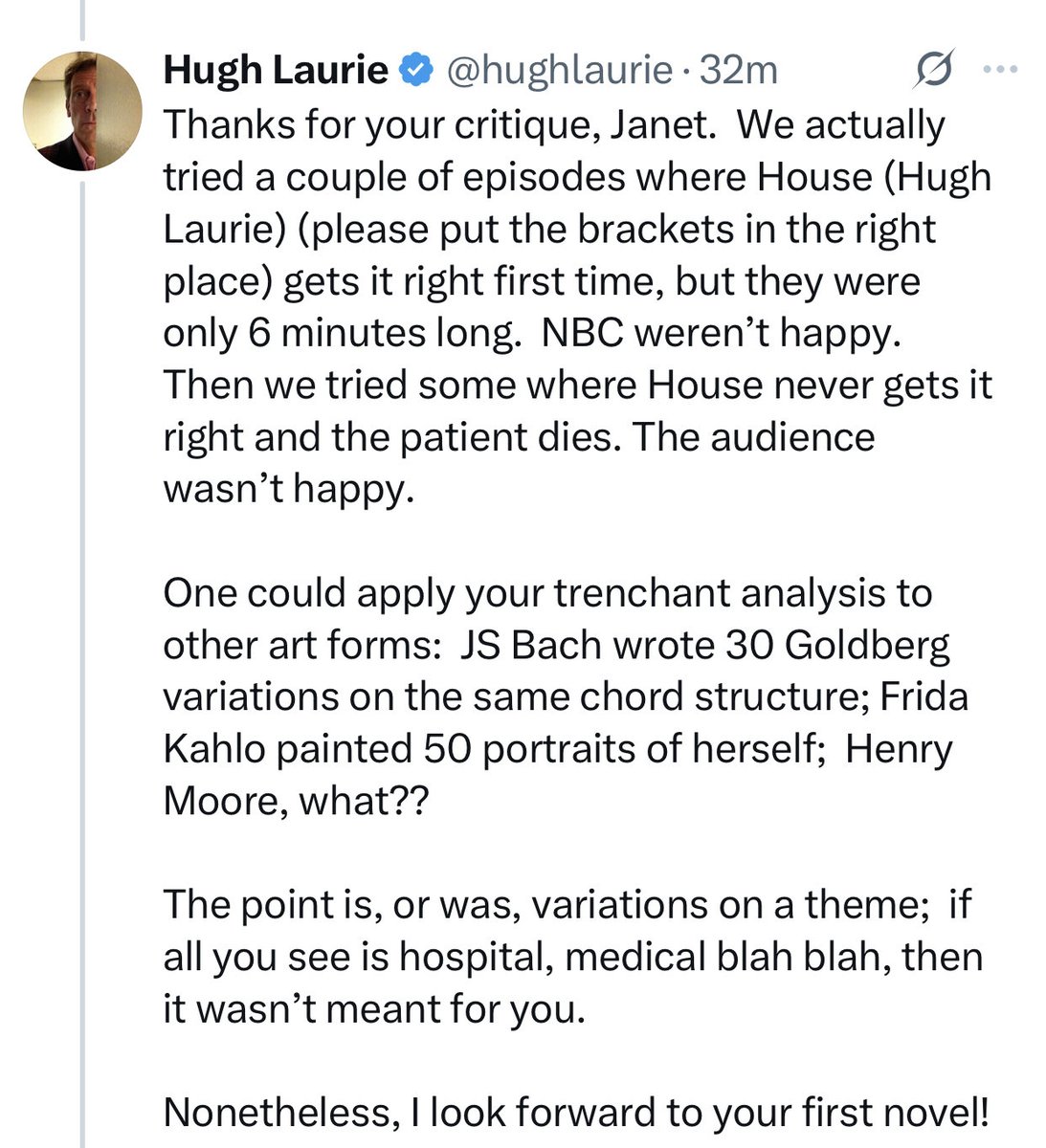
469
2,448
49,284
2,379,817
Jun 5
Yeah! Laten we streven naar Groot Nederland !!! /s

20
Rene Smit 🌱 retweeted

Jun 5
Wij
Zijn
Nederland
Wij zijn Nederland! 🇳🇱🇳🇱🇳🇱🇳🇱
23
6
130
8,148

Jun 4
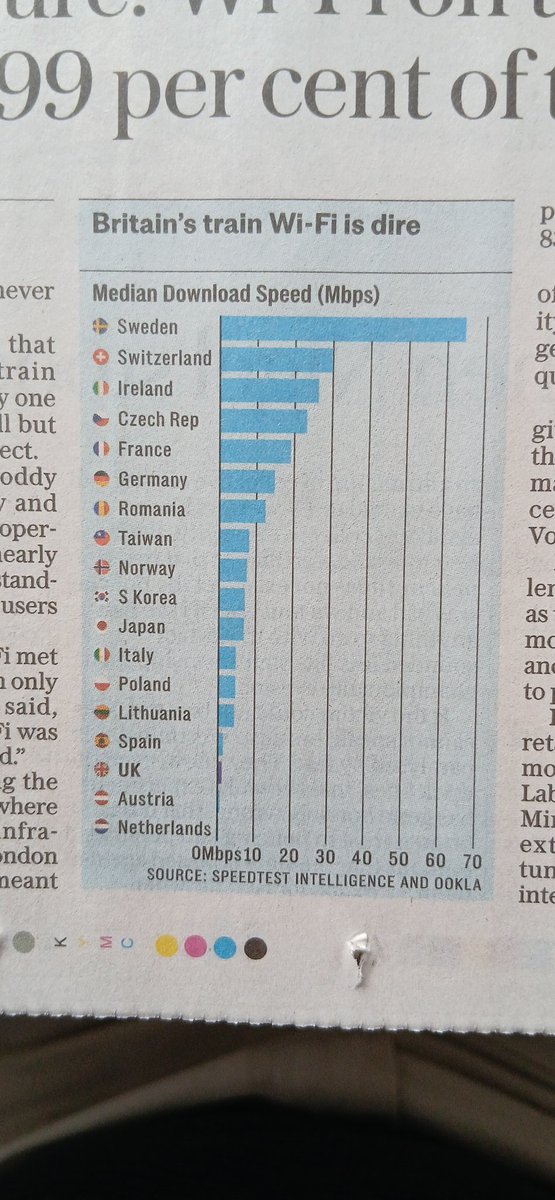
1 GB downloaden in 30 seconden. Daar had de 20 jarige Rene alleen maar van kunnen dromen...
13
Rene Smit 🌱 retweeted

May 17
One underrated thing about using Claude:
If you reply within a few minutes, Claude often reuses the model’s KV cache instead of recomputing the entire conversation again.
During the “prefill” stage, transformer attention states for every token are generated and stored temporarily in memory. Recomputing them is expensive.
So if you reply before the cache expires (~5 min), you get:
• lower latency
• fewer tokens reprocessed
• lower inference cost
Once the cache expires, those attention states may need to be rebuilt from scratch again.
That’s actually one reason I built Claude Pulse.
It shows a live cache countdown directly above the Claude chat box so you can literally see when your context cache is about to expire.
Tiny UI detail. Huge difference once you understand how LLM infra works.
Extension link in comments 👇
1
2
5
2,394
May 29
Gevoelstemperatuur tabel. Begint pas bij 27 graden celcius, dus vaak onbruikbaar in NL
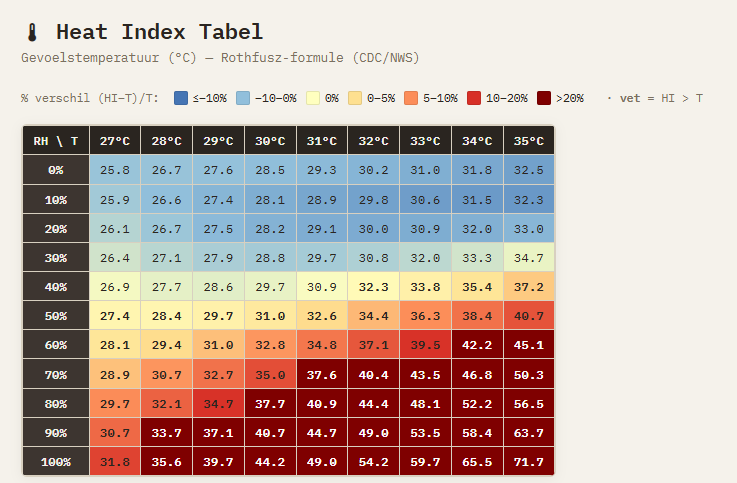
1
73

May 28
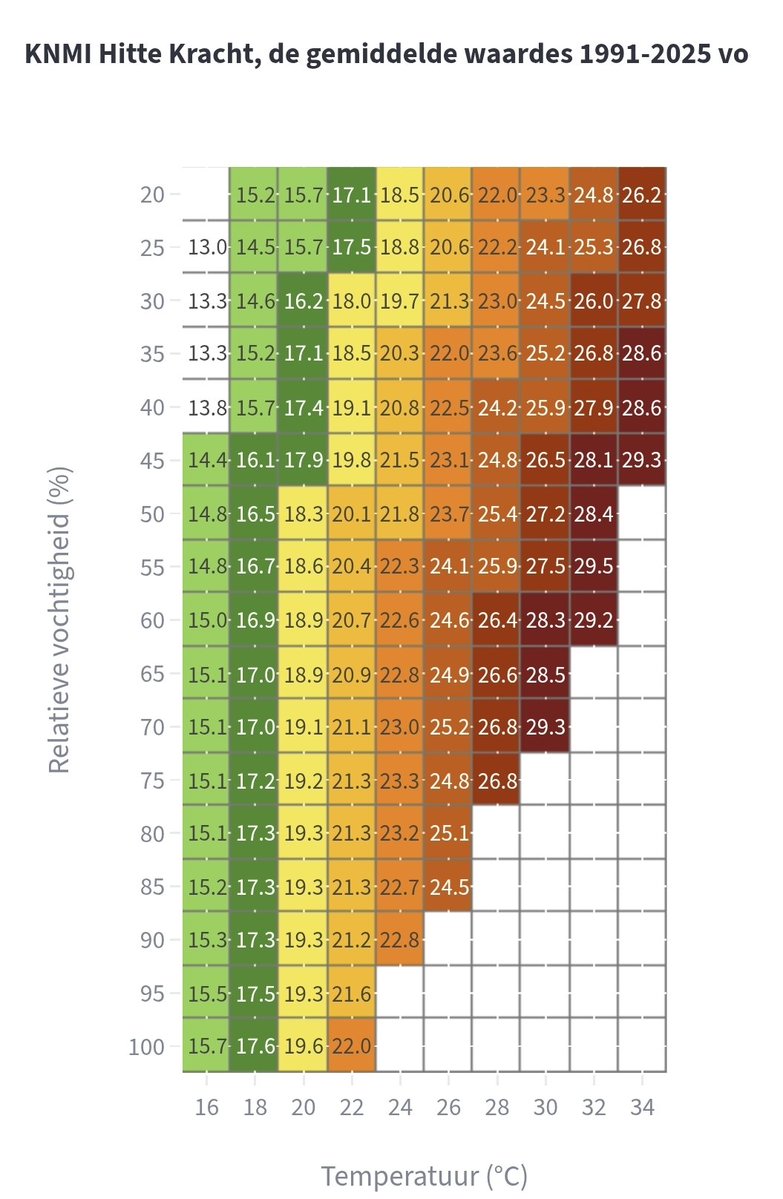
Nieuwe Hittekracht van het KNMI in een tabel
Artikel : rene-smit.com/hitte-meet-je-…
Online: wbgt-rcsmit.streamlit.app/
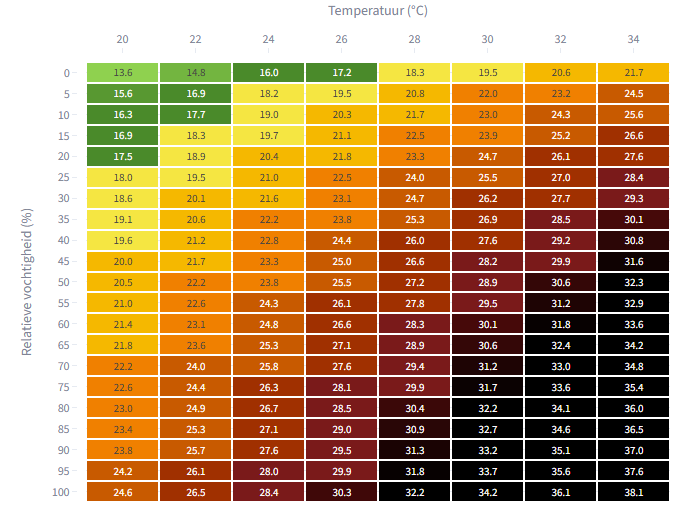
28

Dit is leuk! De Schatkamer van Beeld & Geluid is geopend. Honderdduizenden programma’s van de NPO terug te zien.
schatkamer.beeldengeluid.nl/
6
12
52
6,732
May 26
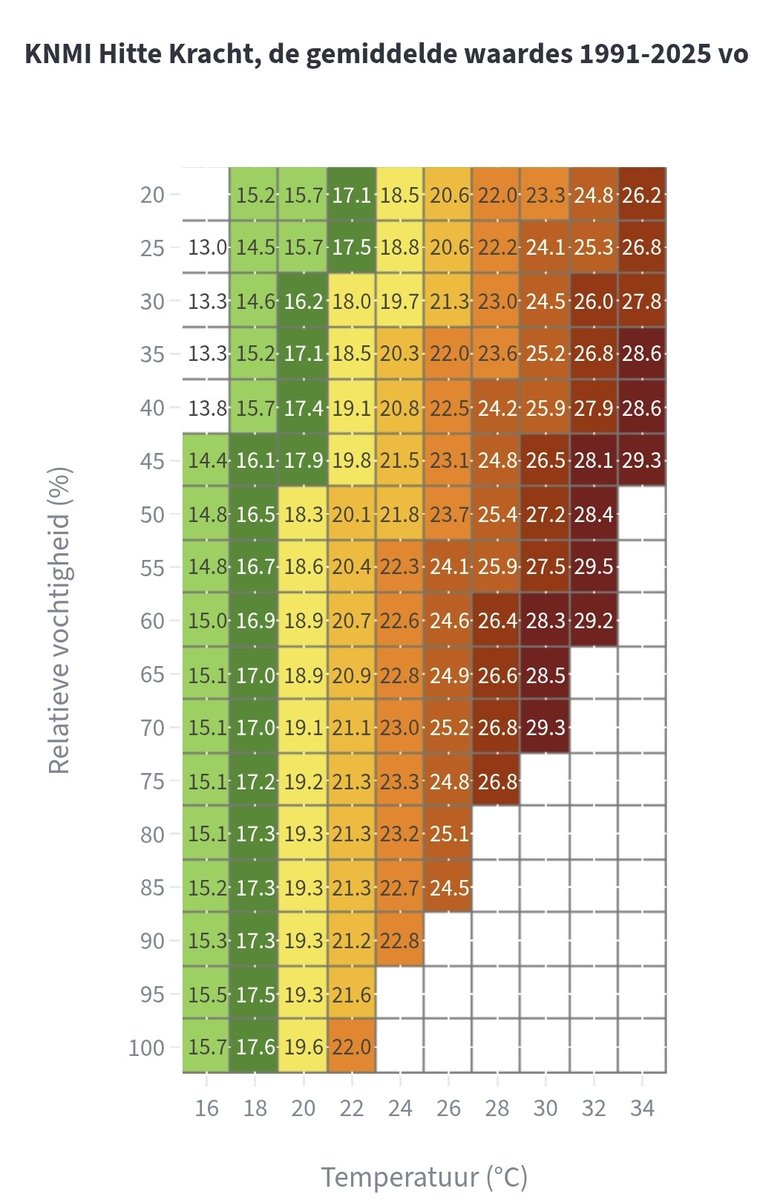
Naar aanleiding van de nieuwe Hittekracht index van het @KNMI
rene-smit.com/hitte-meet-je-…
2
1
6
978
Rene Smit 🌱 retweeted

👉 Vroegste tropische dag De Bilt: 7 mei (1976), dagnr 128
👉Laatste dag in het jaar met 30,0℃ of hoger: 15 sept (2020), dagnr 258
Laatste jaar zonder tropische dag was in 1993 (oranje stip). Rond 1940 had De Bilt er gem. 1 per jaar, nu zijn dat er 5.
Credits Stephan Okhuijsen
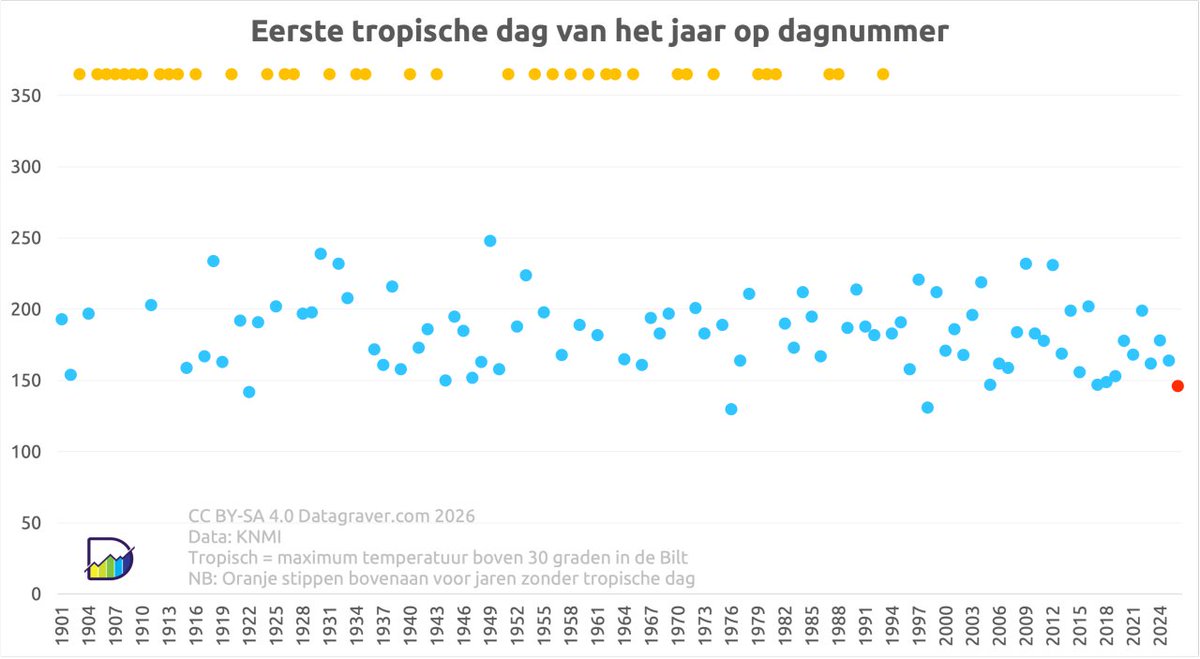
16
5
55
4,526
Rene Smit 🌱 retweeted

May 26
Only internet OG's know about Tucows.
Did you use it?
109
32
589
14,030
May 24
Misschien leuk invalshoek voor een artikel: eten mensen bog steeds varkens als we weten dat ze kunnen praten/communiceren?
instagram.com/merlinthepig
@foodlog_nl @dickfoodlognl
23