
learning from first principles
Joined May 2025
- Tweets 124
- Following 50
- Followers 24
- Likes 86
24 Photos and videos



Pinned Tweet

Jun 9
I’ll be posting threads of chapter summaries (sort of) here. I’m still not sure how accountable I can keep myself, but one can always try.
Jun 7

Programming Massively Parallel Processors (PMPP) has 22 chapters in total. If I do one chapter a day, it should take me about three weeks? 🤔
I want to do this.
1
1
122
Jun 9
I’ll be posting threads of chapter summaries (sort of) here. I’m still not sure how accountable I can keep myself, but one can always try.
Jun 7
Programming Massively Parallel Processors (PMPP) has 22 chapters in total. If I do one chapter a day, it should take me about three weeks? 🤔
I want to do this.
1
1
122
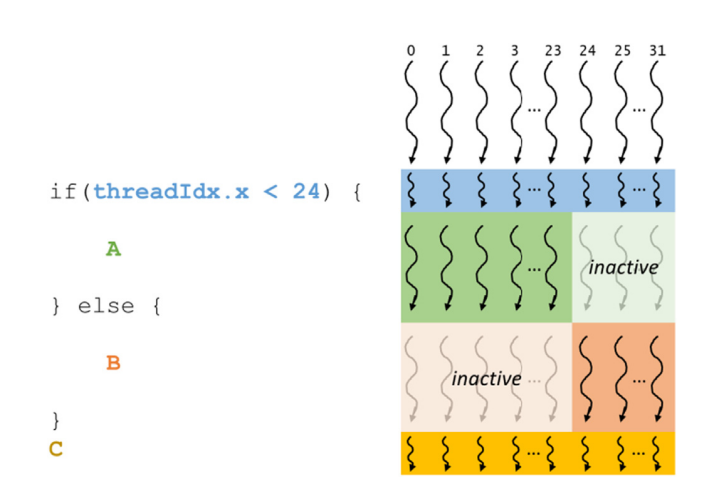
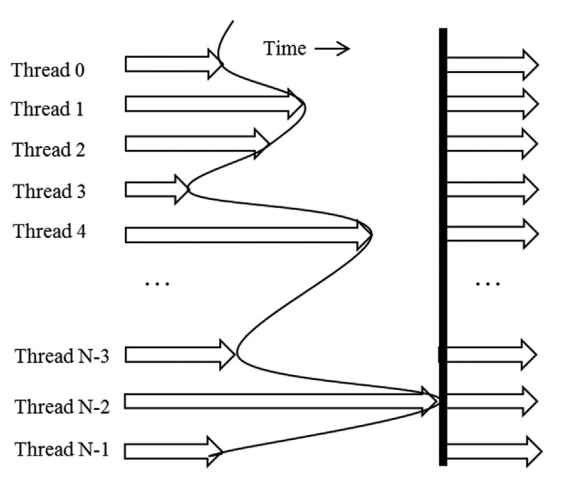
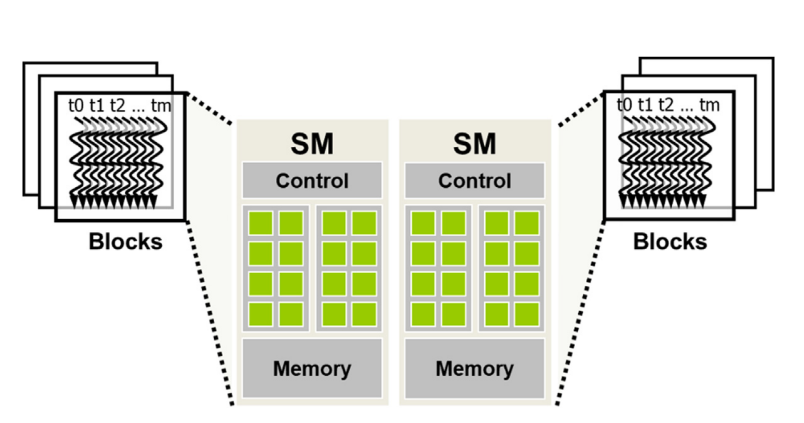
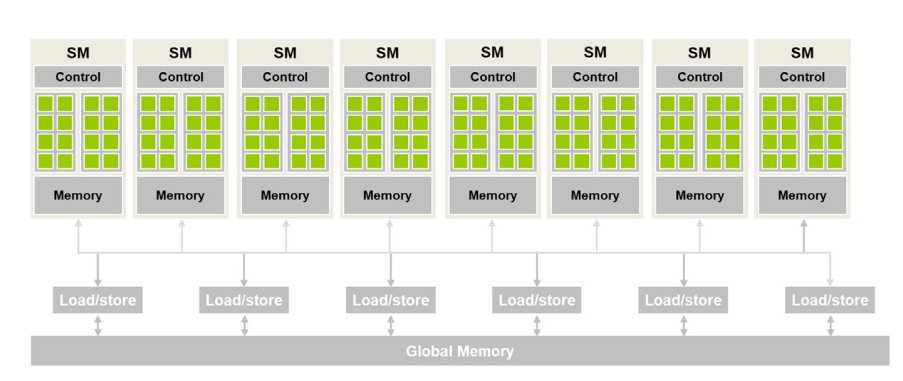
Chapter 6/22 (day 6)
x.com/reprompting/status/206…
Summarizing chapter 6 of PMPP.
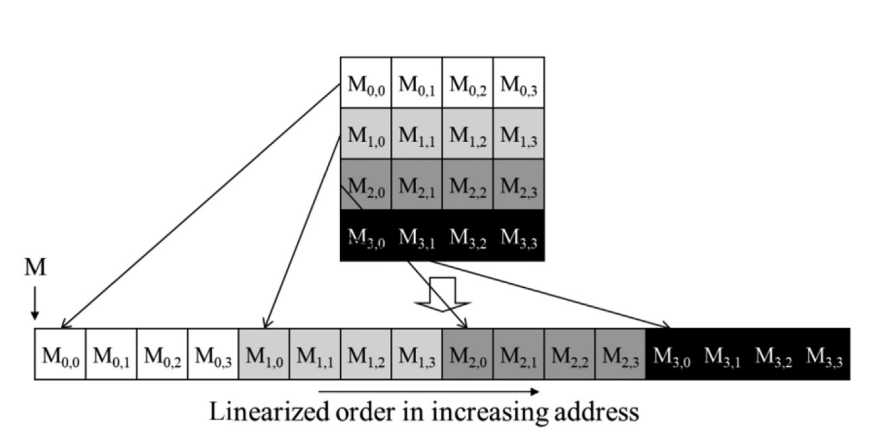
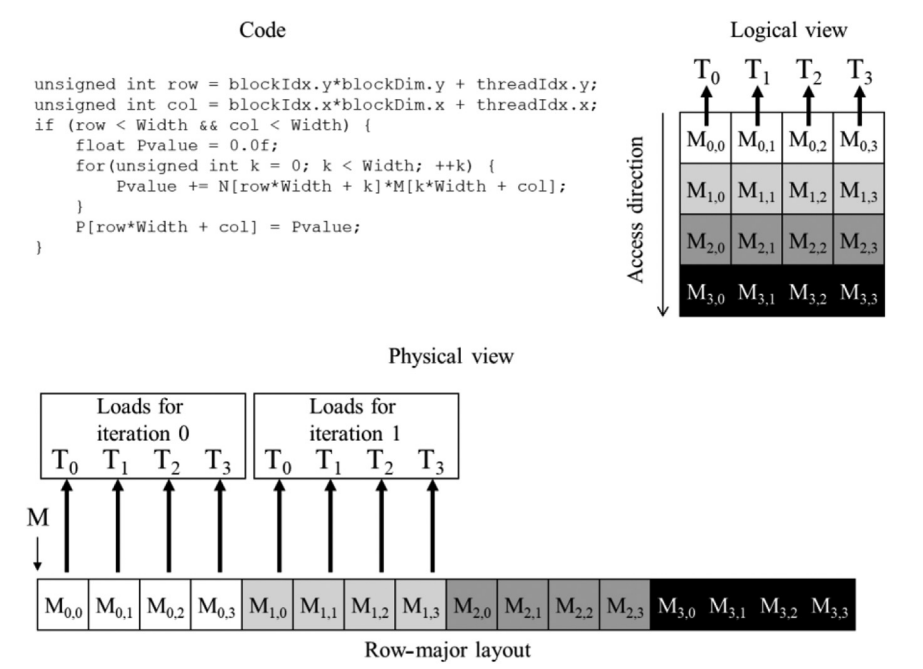
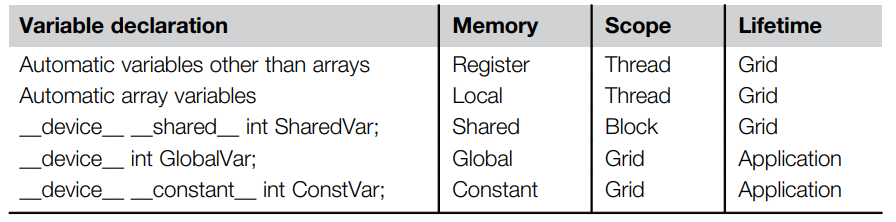
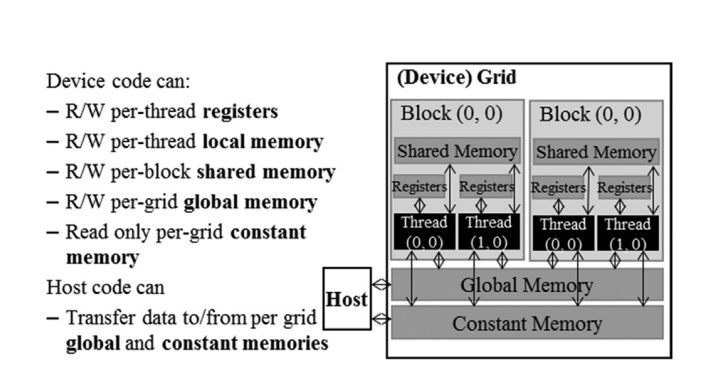
This chapter focues on off-chip memory (DRAM) architecture and discusses performance considerations such as memory coalescing, memory latency hiding and thread coarsening.
1
3
Chapter 7/22 (day 7) x.com/reprompting/status/206…
Summarizing chapter 7 of PMPP.
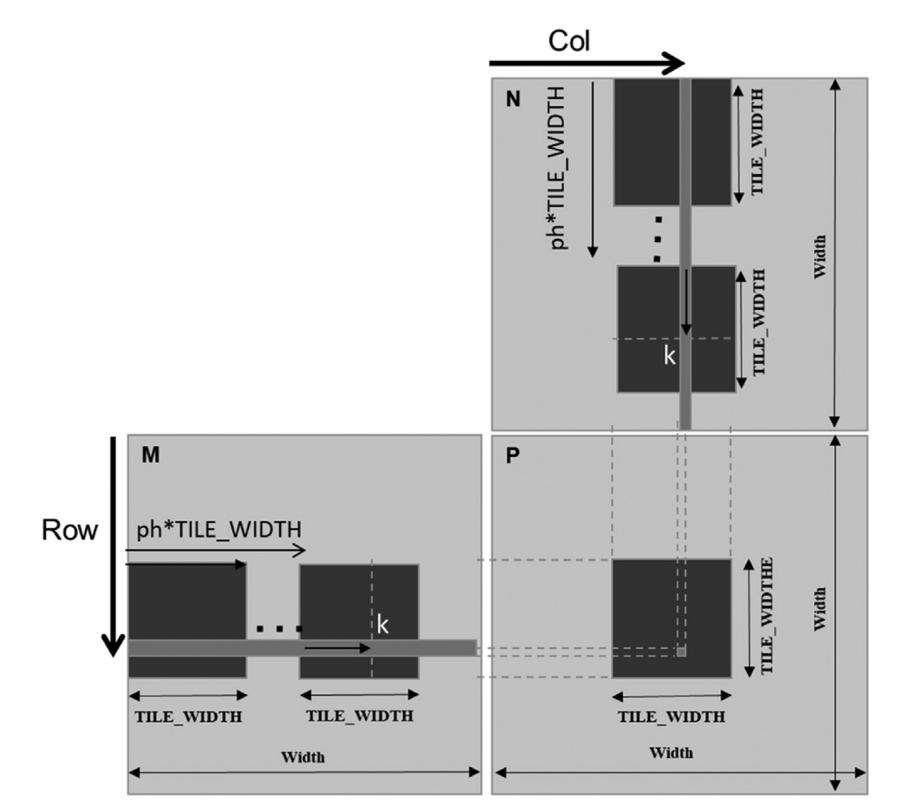
This chapter uses convolution as a case study for GPU optimization. It progresses from naive implementation to constant memory and then shared-memory tiling.
3
Summarizing chapter 7 of PMPP.
This chapter uses convolution as a case study for GPU optimization. It progresses from naive implementation to constant memory and then shared-memory tiling.
1
6
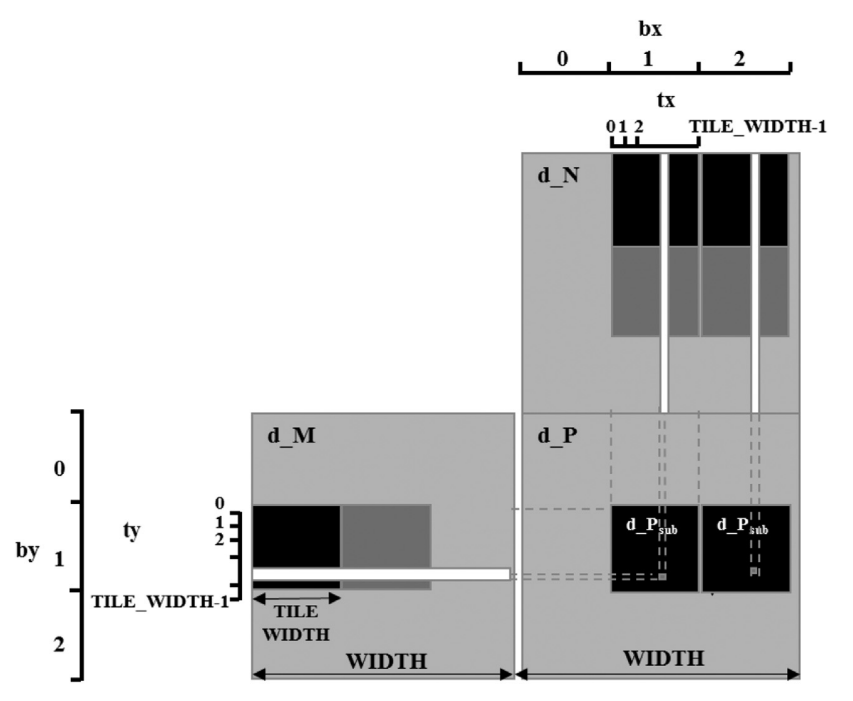
The main challenge compared to tiled matrix multiplication is handling of halo cells. An output tile required neighboring input elements beyond its boundaries, making the input tile larger than the output file.
5
CUDA matrix multiplication using shared memory tiling. It really does feel nice when it clicks.

3
16
230
13,362
Summarizing chapter 6 of PMPP.
This chapter focues on off-chip memory (DRAM) architecture and discusses performance considerations such as memory coalescing, memory latency hiding and thread coarsening.
1
1
49
The chapter then discusses hiding memory latency. To achieve high memory throughput, there must be enough threads issuing memory requests simultaneously. Thread-level parallelism and memory-level parallelism go hand in hand.
1
21
Another optimization introduced is thread coarsening. Instead of assigning one unit of work per thread, each thread performs mutiple units of work. This can reduce redundant loads, redundant works and synchronization overhead.
1
18
Jun 13
Surely, surely, they must have developed something.
Jun 13
If anything, the Lazarus Group should have built something like Fable internally. They could do the funniest thing and release it publicly.
23
Jun 13
If anything, the Lazarus Group should have built something like Fable internally. They could do the funniest thing and release it publicly.
38
Jun 13
All the fearmongering worked. Anthropic is now the arm of the U.S. government. The next step is Fable/Mythos "escaping" the lab.
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
46
Jun 12
elon was pretty cool back then, all about high tech stuff. showed up in big bang theory, iron man and generally seems like real life tech genius. then something seemed to change after that thailand cave rescue controversy


1
77