@rick_pack2@fosstodon.org Data Scientist (#rstats, SAS, #Alteryx). #TriPASS board member. Population health and business analysis focus, oft-geospatial.
- Tweets 1,542
- Following 1,198
- Followers 533
- Likes 7,760




























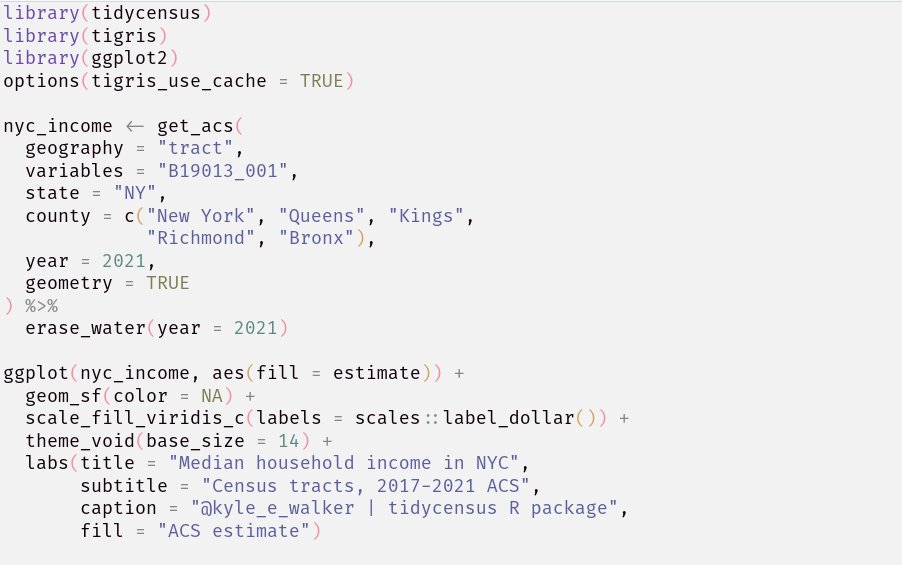
ALT # Before calculate_statistics <- function(numbers, method = "mean", name="") { #calculate the mean of numbers if(method == "mean"){ result <- mean(numbers) } # calculate the median of numbers if(method == "median"){ result <- median(numbers) } #calculate the variance of numbers if(method == "variance"){ result <- var(numbers) } # Return the result and the name return(list(result=result, name=name)) }

ALT # After calculate_statistics <- function(numbers, method = c("mean", "median", "variance"), name="") { #calculate the desired statistic of numbers result <- switch(method, mean = mean(numbers), median = median(numbers), variance = var(numbers)) # Return the result and the name return(list(result=result,name=name)) } I improved this code by using the switch() function instead of a series of if() statements. This makes the code more concise and easier to read, as well as allowing for additional methods to be added in the future without needing to add additional if() statements.