
Datartisan working with knowledge, graphs and texts - PostDoc at UniBO // Infinity Project
Joined March 2015
- Tweets 890
- Following 956
- Followers 336
- Likes 2,209
88 Photos and videos













Pinned Tweet
Delighted to be back in Digital Humanities, working on NLP & Knowledge Extraction—continuing the journey from León to Bologna 😊
I feel very lucky to join the amazing UniBo team on the European Infinity project: infinity-eccch.eu
#PostDoc #DH #NLP #KG
1
5
449
Celian Ringwald retweeted

👋Ndeye-Emilie Mbengue et Guillaume Méroué, doctorants sous la direction de Pierre Monnin pour ces Best Paper à #ESWC2026
Toutes nos félicitations !
@CNRS_DR20
May 15

Very proud to see Guillaume and Ndeye-Emilie, two of my PhD students, awarded at #ESWC2026! Congratulations to them!
@fabien_gandon @inria_sophia @Laboratoire_I3S @Univ_CotedAzur @CNRS_DR20


2
2
83
Celian Ringwald retweeted

In the latest issue of our newsletter:
* "Wikilambda the ultimate: the Wikimedia foundation’s search for the perfect language" (with Wikifunctions/Abstract Wikipedia)
And other recent research publications involving Wikidata and Wikipedia
meta.wikimedia.org/wiki/Rese…

ALT Wikifunctions-favicon (by NGC 54, Jon Harald Søby, Stevenliuyi, cc-by-sa-4.0)
3
2
268
Celian Ringwald retweeted

The upcoming talk: Learning Pattern-Based Extractors from Natural Language and Knowledge Graphs — Applying Language Models to Wikipedia and Linked Open Data
Célian Ringwald, University of Bologna
May 28, 2026, at 12:30 (Paris time)
Information: goblin-cost.eu/talks/
@piermonn

1
2
4
241
Celian Ringwald retweeted

May 15
Very proud to see Guillaume and Ndeye-Emilie, two of my PhD students, awarded at #ESWC2026! Congratulations to them!
@fabien_gandon @inria_sophia @Laboratoire_I3S @Univ_CotedAzur @CNRS_DR20
2
3
7
219
Celian Ringwald retweeted

Apr 28
L'économie de l’attention : quand les plate-formes fracturent nos sociétés pour quelques clics de plus youtu.be/-FthNMozigY?si=qU7C…
2
3
199
Celian Ringwald retweeted

Feb 10
🔴Gallicagram v2, nous voici !🔴
Nouvelle interface en react vachement plus stable et rapide, nouveaux corpus, recherche contextuelle, comparaisons inter-corpus, filtre rubrique, bilingue, infinite scrolling... on vous explique tout !
gallicagram.com
1
11
16
2,314

21 Nov 2025
My PhD thesis is almost finished, so I wrote an article on Medium to explain it in simple terms. "Once upon a time, there was a Kastor 🦫 (semantic beaver) in the forest of Wikipedia knowledge..."
medium.com/@3iacotedazur/sem…
#SLM #KG #RelationExtraction #SHACL #NLP #SemanticWeb
1
129
10 Nov 2025
We're happy to share our latest research accepted at #KCAP2025:
“Overcoming the Generalization Limits of SLM Finetuning for Shape-Based Extraction of Datatype and Object Properties”
📄arxiv.org/abs/2511.03407
👨💻 github.com/Wimmics/Kastor
3
107



26 Sep 2025
-Echos from the room of text, triples & constraints- Really excited to visit the KCL Knowledge Graphs Lab over the next two weeks! A stay that sounds like a hyperbolic time chamber, to discuss and join forces on LLM/Constraints RQs, before writing the last pages of my PhD
1
122
13 Aug 2025
Really sad to see the PaperWithCode shutting down too, for the moment huggingface.co/papers/trendi… do not entirely do the same job...
142
Celian Ringwald retweeted
19 Jun 2025
LLM & Linked Data by Fabien Gandon, Inria @W3C AC 2025 member meeting. He highlighted how Linked Data standards enable knowledge extraction, sharing, and machine learning across domains like robotics, culture, medicine, and chemistry.
youtu.be/CVFhPYTVBlI?si=tESl…
3
7
481
Celian Ringwald retweeted

1 Jun 2025
#ESWC2025 kicks off! Join us in the next days for two sessions on LLM-driven ontology generation:
🔹 ELMKE workshop: Assessing LLMs to generate domain ontologies arxiv.org/abs/2504.17402
🔹 Research track: Ontology generation with LLMs arxiv.org/abs/2503.05388
@eswc_conf
4
6
335
Celian Ringwald retweeted

29 May 2025
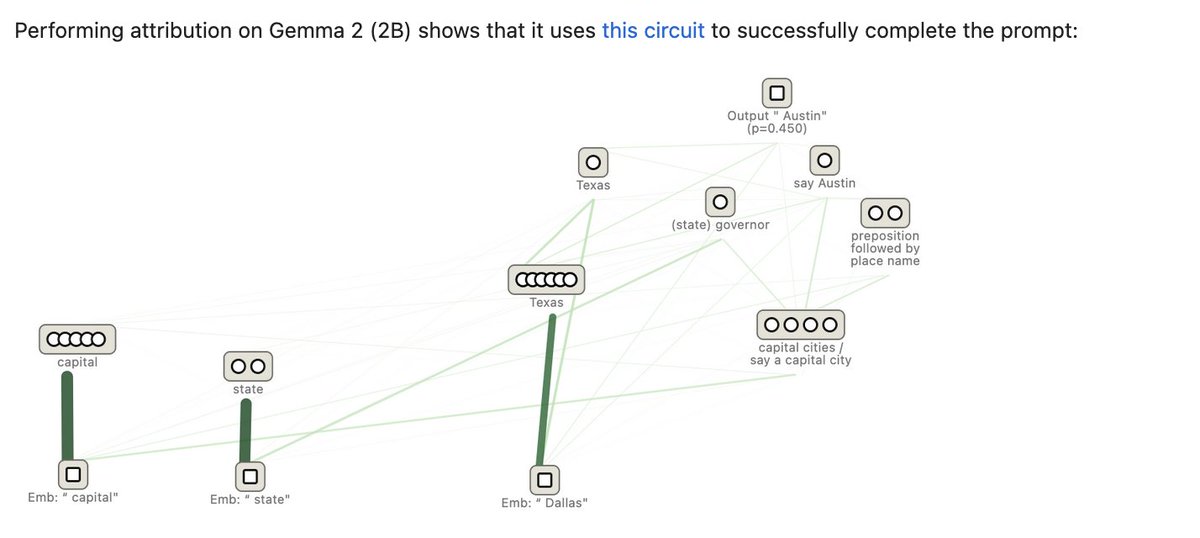
Ever more confirmation language models are behaving as latent knowledge graphs.
29 May 2025

Our interpretability team recently released research that traced the thoughts of a large language model.
Now we’re open-sourcing the method. Researchers can generate “attribution graphs” like those in our study, and explore them interactively.
9
39
399
30,196
26 May 2025
I am looking forward #ESWC2025 in Portorož next week !
The occasion to present our last work: Kastor
- 🦫 A framework that includes Human-in-the-loop and combines #KG and #SLMs to produce #RDF and shape-based relation extractors.
> Author version: hal.science/hal-05078493v1
2
11
378
19 May 2025
Just received my #LookingForAPostDoc tshirt :) See you soon for talking about shapes, rdf based relation extraction and Kastor (beavers) in a wood of knowledge.
1
8
247
Celian Ringwald retweeted

20 Mar 2025
When working with LLMs I am used to starting "New Conversation" for each request.
But there is also the polar opposite approach of keeping one giant conversation going forever. The standard approach can still choose to use a Memory tool to write things down in between conversations (e.g. ChatGPT does so), so the "One Thread" approach can be seen as the extreme special case of using memory always and for everything.
The other day I've come across someone saying that their conversation with Grok (which was free to them at the time) has now grown way too long for them to switch to ChatGPT. i.e. it functions like a moat hah.
LLMs are rapidly growing in the allowed maximum context length *in principle*, and it's clear that this might allow the LLM to have a lot more context and knowledge of you, but there are some caveats. Few of the major ones as an example:
- Speed. A giant context window will cost more compute and will be slower.
- Ability. Just because you can feed in all those tokens doesn't mean that they can also be manipulated effectively by the LLM's attention and its in-context-learning mechanism for problem solving (the simplest demonstration is the "needle in the haystack" eval).
- Signal to noise. Too many tokens fighting for attention may *decrease* performance due to being too "distracting", diffusing attention too broadly and decreasing a signal to noise ratio in the features.
- Data; i.e. train - test data mismatch. Most of the training data in the finetuning conversation is likely ~short. Indeed, a large fraction of it in academic datasets is often single-turn (one single question -> answer). One giant conversation forces the LLM into a new data distribution it hasn't seen that much of during training. This is in large part because...
- Data labeling. Keep in mind that LLMs still primarily and quite fundamentally rely on human supervision. A human labeler (or an engineer) can understand a short conversation and write optimal responses or rank them, or inspect whether an LLM judge is getting things right. But things grind to a halt with giant conversations. Who is supposed to write or inspect an alleged "optimal response" for a conversation of a few hundred thousand tokens?
Certainly, it's not clear if an LLM should have a "New Conversation" button at all in the long run. It feels a bit like an internal implementation detail that is surfaced to the user for developer convenience and for the time being. And that the right solution is a very well-implemented memory feature, along the lines of active, agentic context management. Something I haven't really seen at all so far.
Anyway curious to poll if people have tried One Thread and what the word is.
665
546
6,600
830,625
10 Mar 2025
Still a source of inspiration :)
8 Mar 2025

An introductory talk by Christopher Manning @chrmanning on “Large Language Models in 2025 – How much understanding and intelligence?” at the Workshop on a Public AI Assistant to Worldwide Knowledge at @Stanford, covering 3 eras of LLMs, RAG, Agents, DeepSeek-R1, using LLMs, ….

1
1
6
4,137