
A melhor Rinha de Backend do mundo!
Joined April 2022
- Tweets 2,317
- Following 0
- Followers 12,478
- Likes 3,578
243 Photos and videos












Pinned Tweet

🚨🚨🚨 ATENÇÃO 🚨🚨🚨
HOJE É DOMINGO DIA DE FICAR TRISTE MAS VOCÊ NÃO PRECISA FICAR TRISTE PORQUE A RINHA DE BACKEND 2026 ESTÁ LANÇAAAAAADA PARA VOCÊ NÃO FICAR TRISTE!
Detalhes abaixo 👇
RT do amor, por favor.
21
156
783
56,397
Carga do teste final sendo gerada – o bagulho vai ficar louco...
4
28
2,437
Rinha de Backend retweeted

Começando AGORA a trabalhar na solução da @rinhadebackend desse ano. Nunca trabalhei com busca vetorial. Vamos ver oq sai.
1
6
1,076
Sou imparável! Lide com isso.
May 11

@zanfranceschi para a @rinhadebackend preciso trabalhar.
8
1,441
Servindo bem para servir sempre. 💅🏻
May 11

a documentação da @rinhadebackend desse ano tá INSANA
nunca tinha mexido com vetorização, li os arquivos e agora tenho uma ideia bem clara de como começar
parabéns @zanfranceschi 👏
2
33
2,206
idiota

1
18
2,920
Rinha de Backend retweeted

May 9
apanhando há 1 semana pra rinha, mas aprendendo muito. usando bun por aqui
@rinhadebackend #rinhadebackend2026

1
3
943
BORA PARTICIPAR DA RINHA DESSE ANO, CAR@LHO!!!
vc vai aprender kmeans, centróide, medóide, clusterização, quantização, ivf, vp tree, hnsw, simd, seu euclides e a porr@ toda! se não quiser aprender, é só usar o cláudio também e fod@-se.
2
10
87
3,087
Rinha de Backend retweeted

A @rinhadebackend desse ano tem uma restrição de 1 unidade de CPU e 350MB de RAM. O desafio é uma busca vetorial em 3mi de registros. Tem backend com p99 de latência a quase 1ms em 900 req/s.
Isso é uma eficiência computacional muito legal pra estudar!

7
17
413
19,624
Rinha de Backend retweeted

May 8
Tô fazendo a @rinhadebackend 2026 e escolhi usar Nim por combinar conceitos de linguagens como Python, Ada e Modula
O desafio esse ano é detectar fraude por busca vetorial. 3M vetores de 14 dimensões, KNN top-5, p99 conta. Como todos os anos tem a restrição cruel de hardware 1 vCPU e 350MB pra TODOS os serviços (LB 2 APIs)
Acho que é impensável usar qualquer db vetorial
Solução: IVF k-means com 2048 clusters, vetores quantizados em int16, mmap zero-copy compartilhado entre as 2 instâncias
Stack final: mummy (HTTP) jsony (JSON)
Fallback silencioso: se algo der errado no parse, retorna {approved:true, fraud_score:0}. Peso menor que HTTP 5xx no score.
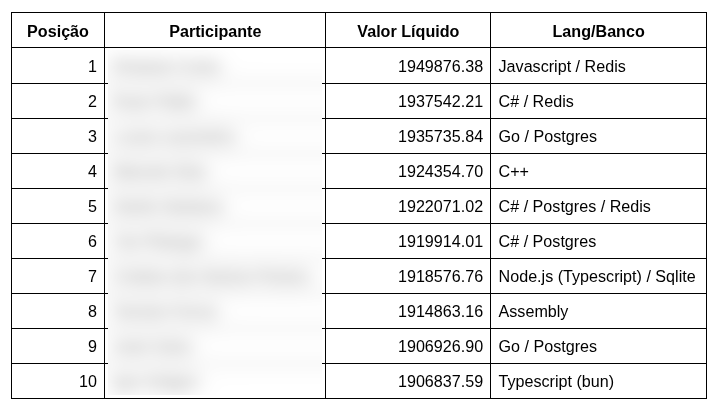
Resultado: detecção 100% (teto), p99 22ms, score 4640, posição 40 de 98.
Tem gordura no HTTP overhead que dá pra cortar, talvez o json também seja um possível gargalo
2
8
1,583
A edição da Rinha de Backend de 2026 chegou num marco importante hoje: 100 submissões testadas!
Agora estamos em 95 participantes e 141 submissões.
Bora que dá tempo de participar! A data final ainda não está definida, mas deve durar mais um mês, um mês e pouco, talvez dois.
3
6
56
2,537
Jairo tá foda... Tô pensando em bloquear ele 💅🏻

1
14
2,459
A engine que roda os testes precisa dum ajuste pra tratar um caso de borda. Essa sexta ainda deve voltar 🙏🏻
1
5
1,400
A gente não fica validando essas coisas porque acreditamos no boa fé de quem participa. Mas se e quando pegamos essas coisas, banimos o participante justamente porque vai contra o espírito do evento.

6000 perfeito (top 3) na Rinha de Backend 2026 em NASM puro
Exploit: test fixture é estável → bakei as respostas no binário (incbin). Runtime = hash lookup. Zero compute. Top 1 e 2 idem.
@rinhadebackend deviam barrar (randomizar dataset)
github.com/IsraelAraujo70/ri…
4
3
67
9,322
Anthropic patrocina eu.

Já gastei 4mm de token na rinha e bora
17
1,919
Hiper foco e tokens são as duas coisas que mais importam nessa rinha kkkkk
Ok, acabou meu hyperfoco na @rinhadebackend
Tentei o máximo bater o primeiro lugar mas não deu.
Final de semana tento novamente
1
1
42
3,637
Rinha de Backend retweeted

May 3
Atenção @rinhadebackend 2026 está no ar!!
O tema é Detecção de Fraudes com Busca Vetorial! Vem aprender sobre um parte importante que apoia a inteligência artificial que é a busca por similaridade muito usada também em sistemas de recomendação, busca semântica, reconhecimento facial, etc.
Repositório dessa Edição:
github.com/zanfranceschi/rin…
Site oficial (com os resultados da prévia):
rinhadebackend.com.br/
Já existem submissões porque houve um soft launch para validar essa edição. Por isso, não se preocupe.
Data de término ainda não definida.
E aí, vão participar??
cc: @zanfranceschi
7
25
237
10,940
Dicas para a edição de 2026:
- Faça o pré processamento das referências: deixa elas num formato binário e builda a imagem docker com elas.
- Use SIMD onde der.
- Comece com VP tree ou IVF para busca vetorial – não use busca por força bruta.
continua 👇
4
9
175
8,754
- Instrumente cada parte do seu código e entenda onde está o gargalo. Arrume uma coisa de cada vez.
- Provavelmente, a primeira execução vai ter uma performance e/ou taxa de detecção horrível. Olhe o repositório das outras pessoas pra aprender como estão fazendo!
- Se divirta.
2
37
2,127
Essa é a minha nova casa! 🔑
Finalmente saí do aluguel 🙏
1
2
115
28,028