
echocardiography fellow @ ucsf, data science @ berkeley, food enthusiast
Joined April 2007
- Tweets 6
- Following 205
- Followers 118
- Likes 96
Photos and videos
River Jiang retweeted

6 Mar 2024
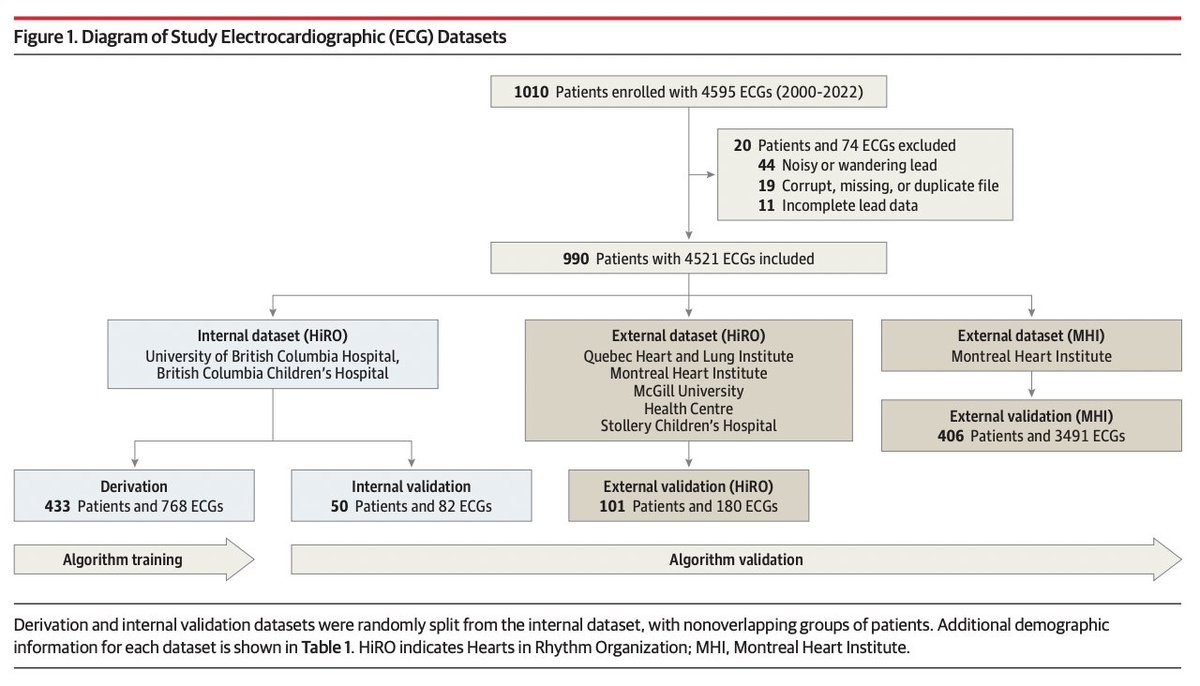
Hot-off-the-press! The latest paper from #HiRO is now available online @JAMACardio
Deep Learning–Augmented ECG Analysis for Screening and Genotype Prediction of Congenital Long QT Syndrome @riverjiang
jamanetwork.com/journals/jam…
#cardiogen #EPeeps #LQTS @UBCmedicine @ICMtl
1
7
14
7,480
River Jiang retweeted

30 Nov 2022
How to use OpenAI's ChatGPT for creative writing collaboration.
#OpenAI #ChatGPT
andrewmayneblog.wordpress.co…
14
108
570
River Jiang retweeted

3 Mar 2023
I'm speechless.
Not peer-reviewed yet but a submitted paper.
The 'presented images' were shown to a group of humans. The 'reconstructed images' were the result of an fMRI output to Stable Diffusion.
In other words, #stablediffusion literally read people's minds.
Source 👇

483
3,485
20,440
6,543,615
River Jiang retweeted

1 Mar 2023
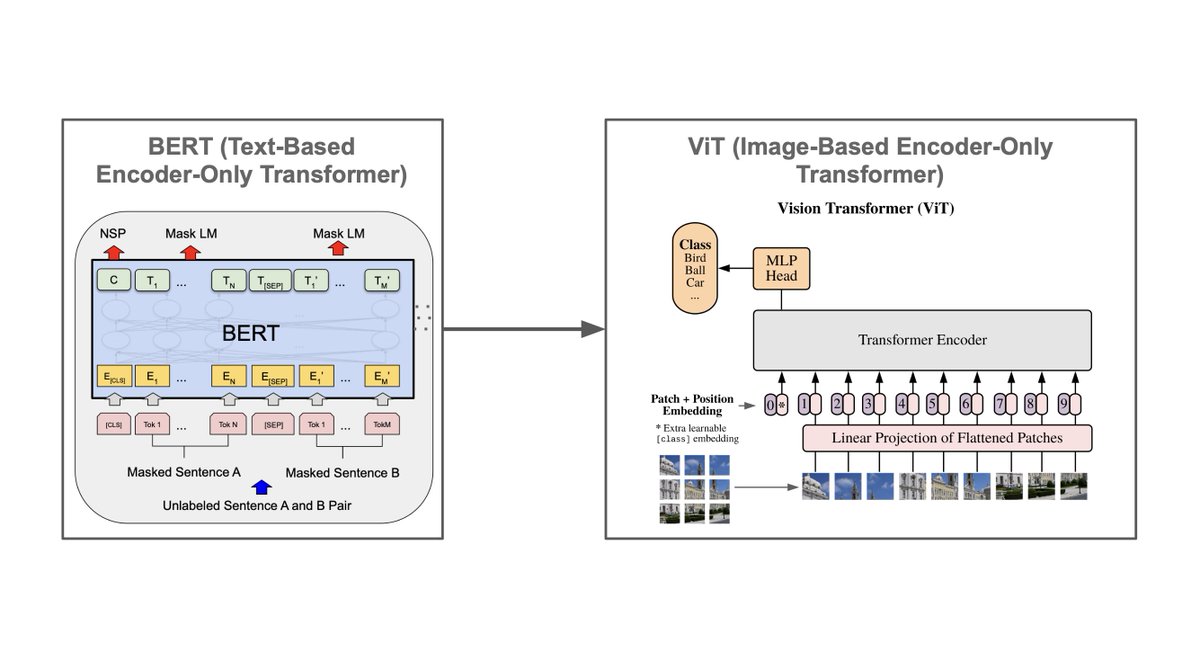
Vision Transformers (ViTs) are a powerful deep learning architecture, but what’s the difference between ViT and a text-based transformer like BERT? Despite being applied in completely different domains, these models have only one major difference… 🧵[1/7]
2
92
524
112,721
River Jiang retweeted

1 Mar 2023
Oh great just what cardiologists need, more ventricles
26
19
1,817
133,026
River Jiang retweeted

23 Dec 2022
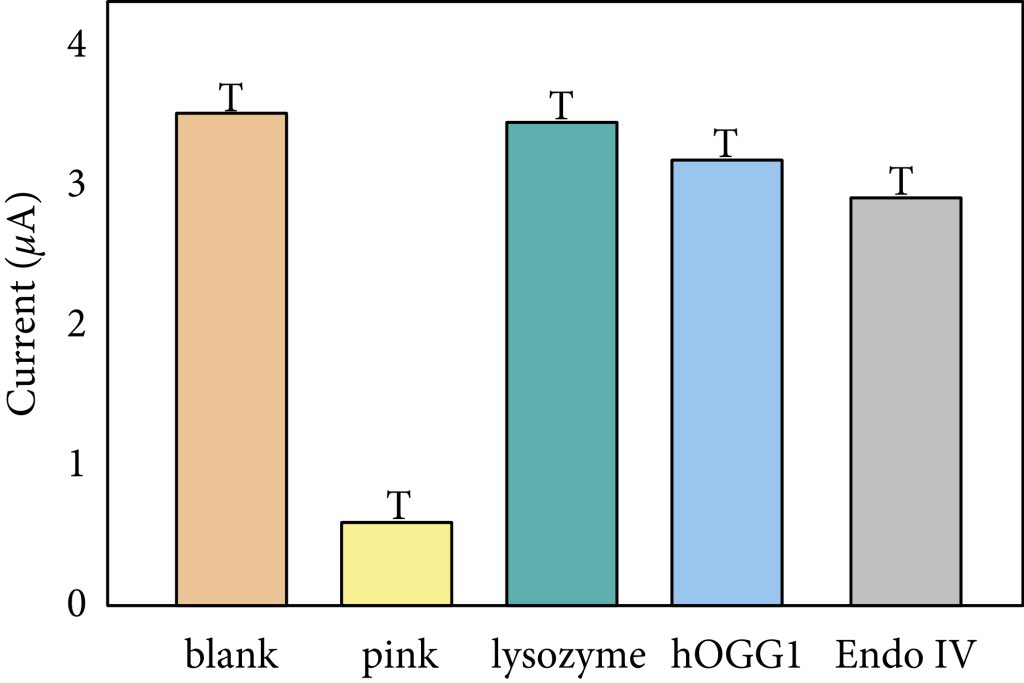
Remember that paper that just has the letter T for error bars?
Well it got retracted.
Notice of retraction: “readers have raised concerns that the error bars in Figure 9 appear to be the letter ‘T’”
🤷 sometimes the system works
retractionwatch.com/2022/12/…
3
8
62
32,014