
Member of technical staff @AnthropicAI, into training and reinforcement learning
Joined November 2018
- Tweets 127
- Following 725
- Followers 1,550
- Likes 1,206
25 Photos and videos
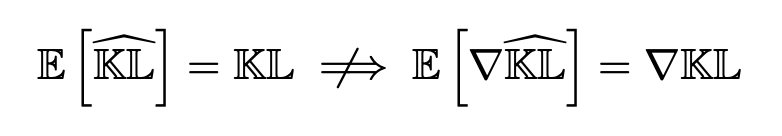
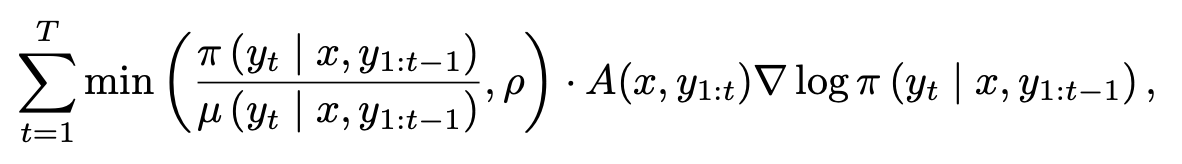







Pinned Tweet

12 Jun 2025
Maybe to one's surprise, taking KL estimates as `kl_loss` to minimize does *not* enforce the KL.
This implementation, however, is quite common in open source RL repos and recent research papers.
In short: grad of an unbiased KL estimate is not an unbiased estimate of KL grad.
15
54
657
71,247
12 Jun 2025
Maybe to one's surprise, taking KL estimates as `kl_loss` to minimize does *not* enforce the KL.
This implementation, however, is quite common in open source RL repos and recent research papers.
In short: grad of an unbiased KL estimate is not an unbiased estimate of KL grad.
15
54
657
71,247
12 Jun 2025
Taking the k3 estimate as an example (from John's popular blogpost joschu.net/blog/kl-approx.ht…). Contrary to popular practice, differentiating the estimate as a loss ends up enforcing the reverse-KL, but only incidentally.
See more details: arxiv.org/pdf/2506.09477
6
33
4,776
7 Jun 2025
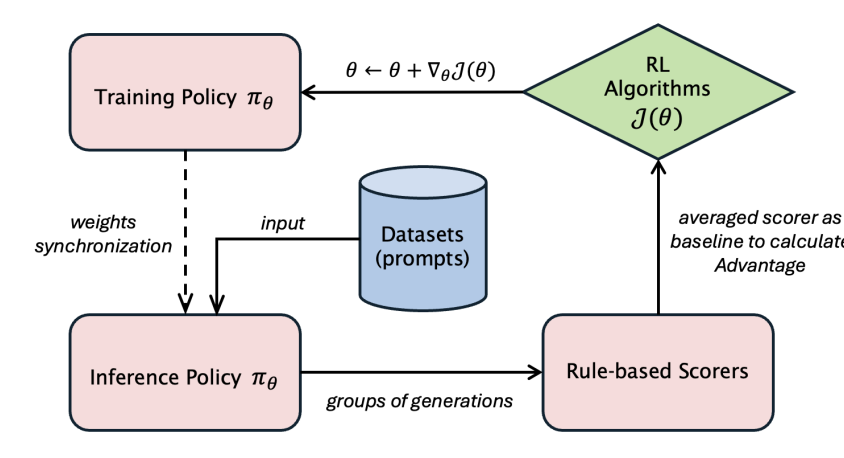
Introducing LlamaRL, a distributed RL framework for training LLM at scale.
LlamaRL is highly modular, Pytorch-native, customizes optimization of actors/learners to max out throughput, and adjusts for systemic off-policyness to stabilize training
arxiv.org/pdf/2505.24034
4
47
296
27,846
7 Jun 2025
It was refreshing to see the impact that small algorithmic changes have on the system performance.
While the “double-sided” PPO/GRPO clipping is dominant in the literature, we argue that a single-sided clipping akin to IMPALA fits the design of distributed training more.
15
1,045
Yunhao (Robin) Tang retweeted

8 Jul 2024
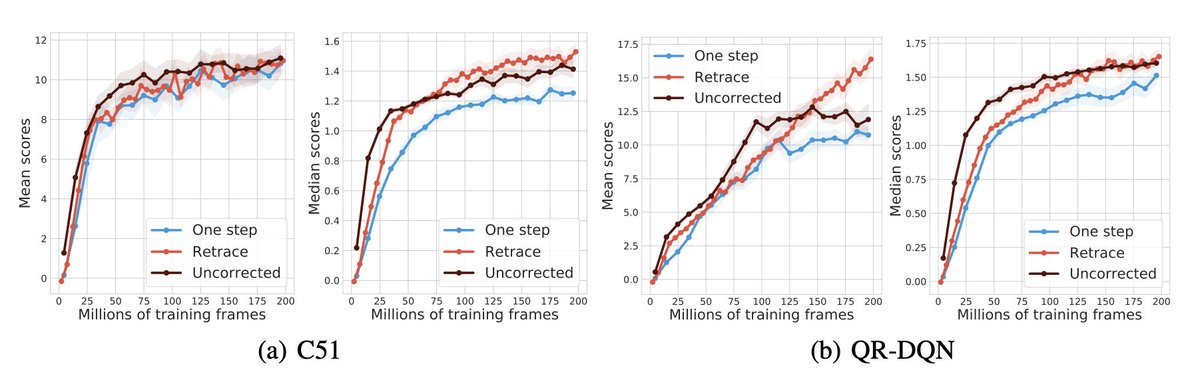
Eventually, humans will need to supervise superhuman AI - but how? Can we study it now?
We don't have superhuman AI, but we do have LLMs. We study protocols where a weaker LLM uses stronger ones to find better answers than it knows itself.
Does this work? It’s complicated: 🧵👇
5
57
242
53,449
27 May 2024
Thanks @_akhaliq for promoting our work!
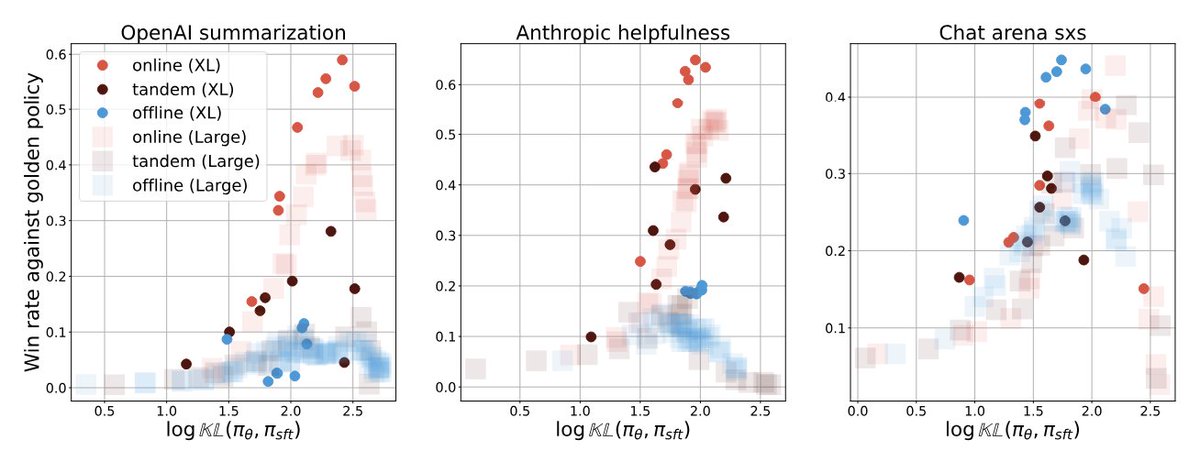
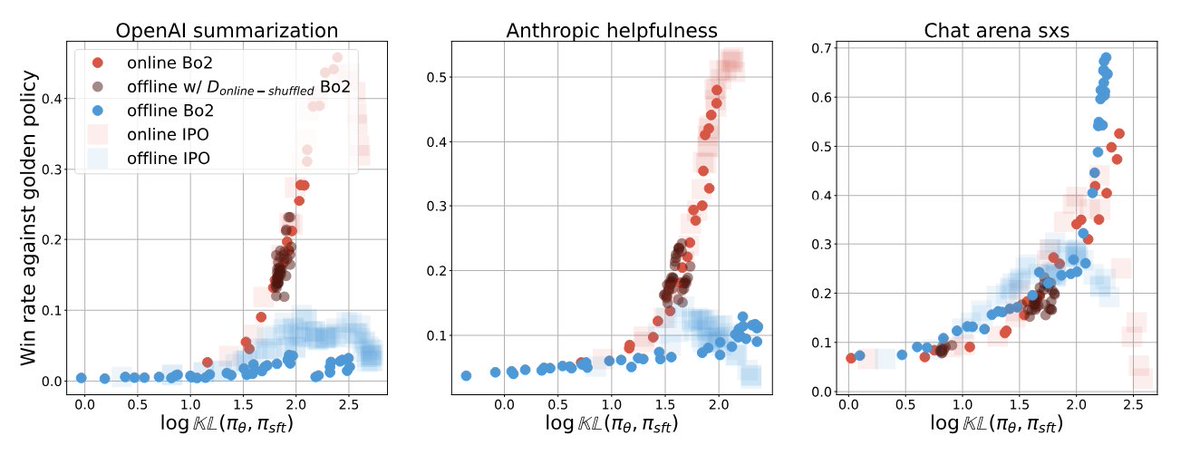
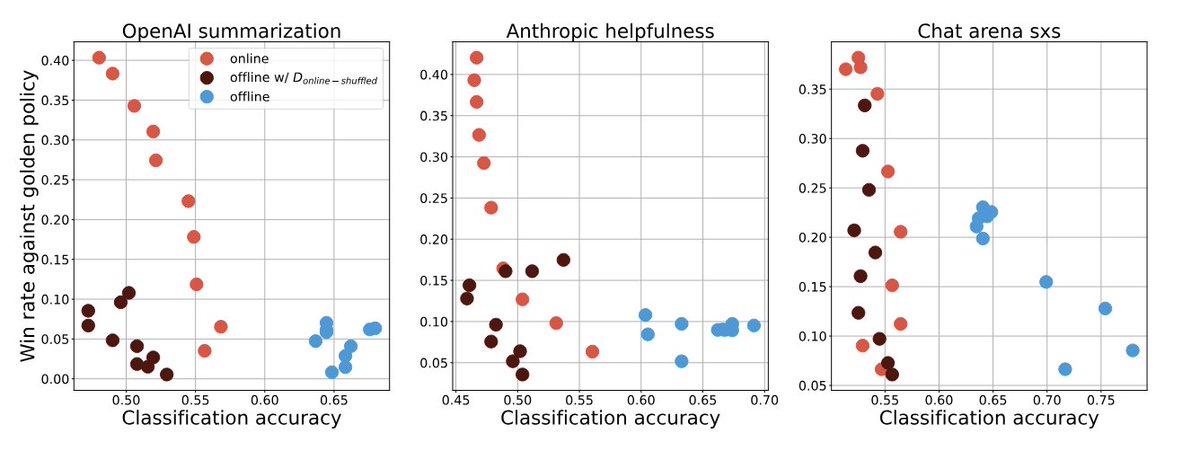
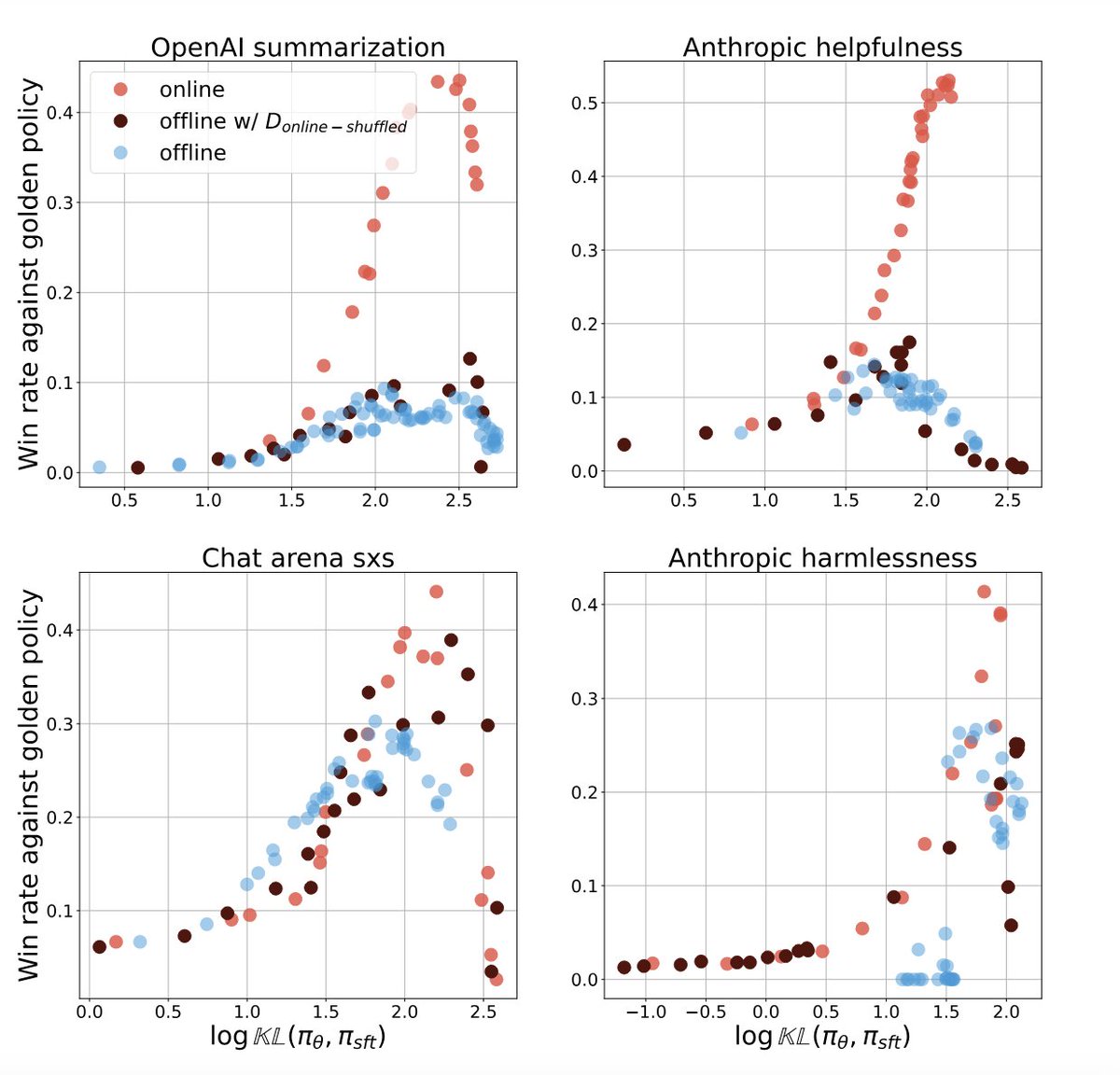
Unlike regular RL where golden r(s,a) are available and online is generally deemed better than offline, in RLHF this is less clear.
Complementary to some concurrent work, we investigate causes to the perf gap between online vs. offline.

Understanding the performance gap between online and offline alignment algorithms
Reinforcement learning from human feedback (RLHF) is the canonical framework for large language model alignment. However, rising popularity in offline alignment algorithms challenge the need

4
16
2,481
27 May 2024
Online interaction is probably a defining property of RL. But with the rise of offline algo, it is not clear if the “online” bit of RL is necessary for RLHF.
We hypothesis test the causes of the perf gap between online and offline alignment. arxiv.org/pdf/2405.08448v1
Details in🧵
3
15
71
11,284
27 May 2024
Some takeaways:
- There is something more to online than wider coverage of response generation
- Offline training improves policy is a much more implicit way than online (discriminative vs. generative abilities)
- The gap persists across wider variants of algos and network sizes
1
4
560
27 May 2024
The findings ought to be taken with a grain of salt due to limitations in our experimental setups. But hopefully this investigation contributes to a better understanding of RLHF practices.
Finally, very grateful to my collaborators @GoogleDeepMind on this fun project!
1
6
553
Yunhao (Robin) Tang retweeted

4 Dec 2023
Fast-forward ⏩ alignment research from @GoogleDeepMind ! Our latest results enhance alignment outcomes in Large Language Models (LLMs). Presenting NashLLM!

4
126
793
192,778
27 Jul 2023
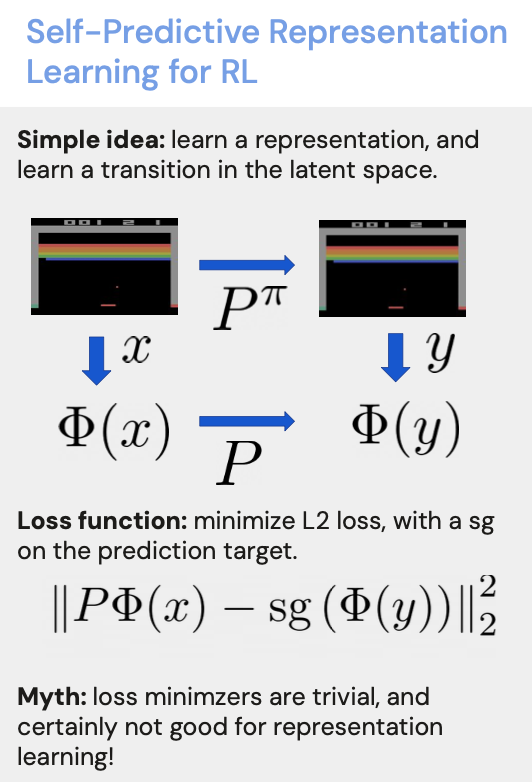
Interested in how
**non-contrastive representation learning for RL**
is magically equivalent to
**gradient-based PCA/SVD on the transition matrix**
and hence won't collapse and capture spectral info about the transition?
Come talk to us at #ICML2023 Hall 1 #308 at 1:30pm
24 Jul 2023

Interested in how non-contrastive representation learning works in RL? We show
(1) Why representations do not collapses
(2) How it relates to gradient PCA / SVD of transition matrix
Understanding Self-Predictive Learning for RL #ICML2023 @GoogleDeepMind arxiv.org/pdf/2212.03319
4
49
9,859
Yunhao (Robin) Tang retweeted

25 Jul 2023
Even if all you want is a value function, using quantile TD (QTD) can give a better estimate than standard TD.
Today at #ICML2023, Mark Rowland presents our latest work on distributional RL in collaboration with @robinphysics, @clarelyle, Remi Munos, @marcgbellemare
#809 @ 2pm
1
3
31
2,757
24 Jul 2023
Interested in how non-contrastive representation learning works in RL? We show
(1) Why representations do not collapses
(2) How it relates to gradient PCA / SVD of transition matrix
Understanding Self-Predictive Learning for RL #ICML2023 @GoogleDeepMind arxiv.org/pdf/2212.03319
1
40
158
30,052
Yunhao (Robin) Tang retweeted

23 Jul 2023
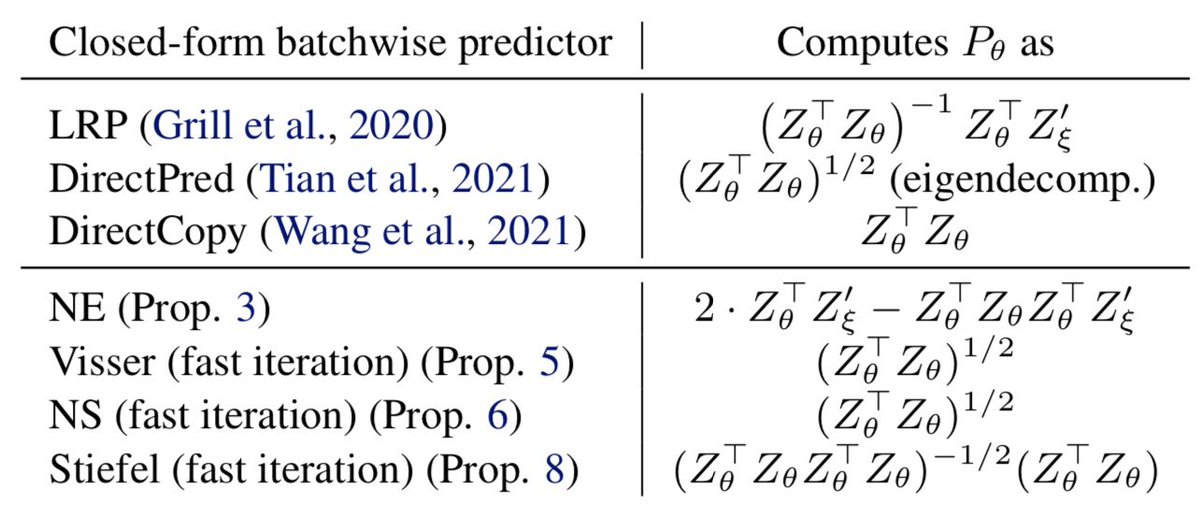
NEW WORK-The last word on why BYOL works ? In ‘The Edge of Orthogonality’ we give exceedingly simple theory thanks to the optimal predictor being an orthogonal projection, connect BYOL to Riemannian SGD, and propose 4 new closed-form predictors ! #ICML2023 arxiv.org/abs/2302.04817
1
5
14
2,721