
Postdoc @VcaiMpi MPI for Informatics | Virtual Avatars, Human Motion, Physical AI | Prev. PhD @Polytechnique, @Ubisoft @CYENSCoE @la_UPC | Dad 👦🏻👶🏻
Joined June 2020
- Tweets 252
- Following 535
- Followers 262
- Likes 549
83 Photos and videos














Pinned Tweet

19 Jul 2024
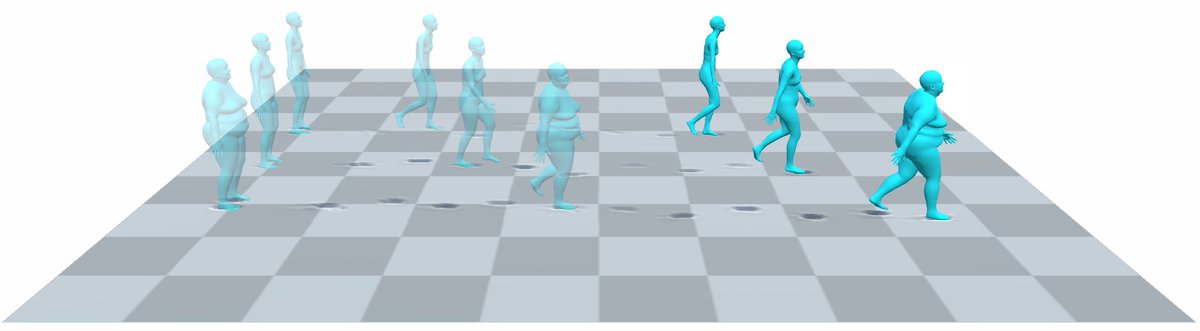
Have you ever wondered how avatars for example using #SMPL affect natural scenes at multiple scales? We present "TRAIL: Simulating the impact of human locomotion on natural landscapes", shown at #CGI2024.
📝 Paper: rdcu.be/dOk8O
🖥️ Github: github.com/edualvarado/TRAIL…
🧵
1
6
17
2,375
Friendly reminder to invest in a good office chair. I got a second-hand Herman Miller Aeron and it's already working wonders on my back. Otherwise, a height-adjustable desk is another must.
1
58
May 31
Just finished setting up Tailscale and Obsidian stored in an independent share for my NAS. Now I can access it with Claude Code and sync everything across devices. Life-changing organization.
1
2
114
May 30
“It is the quiet proof that “real” was only ever a word for what we had not yet learned to compute.”
This gives me the chills. I hope we are ready, because the existential dilemma we are heading toward will be so deep that the demand for psychologists is going to skyrocket.

Demis Hassabis wants to do something no civilization has ever been able to do.
Run reality more than once.
Hassabis: “AI itself will maybe unlock new sciences… the one I’m particularly excited about is AI for simulations.”
Every economy ever built. Every policy ever enacted. Every war ever fought.
Happened exactly once. Against the entire human population. With no way to run it again.
Hassabis: “If you raise interest rates by half a percent, you have to do it in the real world and then see what happens. You can have theories, but you can’t run it thousands of times.”
Every major decision in the history of civilization was a single experiment run on billions of people with no control group and no second attempt.
We called the results knowledge.
They were the scars of bets we were never allowed to place twice.
Hassabis: “Why aren’t they just sciences like physics today? Because the problem is they’re emergent systems… it’s very hard to do repeated controlled experiments.”
Physics became physics because you can drop a ball a thousand times and get the same answer.
You cannot drop a civilization and get any answer at all. You just get the wreckage and call it a lesson.
Hassabis wants to change that.
Hassabis: “If you could simulate things really accurately, then maybe there’s sort of new sciences to be done where you can rigorously sample from a very accurate simulator.”
Simulate an economy. Crash it. Rebuild it. Adjust the inputs. Run it again.
Do for civilization what the laboratory did for chemistry.
But that word “accurately” is doing more work than anyone is willing to examine.
To simulate a society well enough to learn from it, you have to simulate the people inside it.
Not averages. Not abstractions. Agents with preferences and fears and breaking points.
The more accurate the simulation gets, the less separates it from the thing it represents.
The line between physics and economics was never about the nature of what was being studied.
It was about the limits of the thing doing the studying.
Humans were never too complex to predict. We were too complex to calculate.
AI does not create new science. It collapses every science into one.
Everything computable becomes predictable. Everything predictable becomes simulable.
And past a certain resolution, the gap between a simulated world and a real one stops being a technical question.
It becomes a philosophical question no one is prepared to answer.
A simulation you can tell apart from reality is a simulation that has not finished improving.
The people inside a perfect one would not wonder whether their world was generated.
They would feel exactly the way you feel right now. Reading this. Certain they are real.
That certainty is not evidence. It is exactly what a successful simulation would produce.
Hassabis: “That will allow us to make much better decisions in these, today, what are very uncertain domains.”
What he is building is not a forecasting tool.
It is the quiet proof that “real” was only ever a word for what we had not yet learned to compute.
And that word is about to lose its meaning.
66
Apr 22
As part of my little side project, I just finished setting up my NAS and self-hosting my WordPress site. With everything I’ve just learned, it was definitely worth it. Self-storing your own data is amazing.
64
Something similar has been my workflow since the year started, plus AI-generated summaries using Zotero for paper indexing. So far a great choice.
Apr 2

LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
1
169
Eduardo Alvarado retweeted

Mar 20
Quantum architecture search (QAS) meets 3D!
Designing expressive, lightweight quantum neural networks (QNNs) that mitigate barren plateaus is hard. Our 𝐿𝑎𝑦𝑒𝑟𝑒𝑑-𝑄𝐴𝑆 discovers such QNNs for point cloud classification.
4dqv.mpi-inf.mpg.de/LQAS/
#3DV2026 #quantum #QeCV #QML
1
7
566
Eduardo Alvarado retweeted

🔥 #3DV2026 Oral: We present a matrix-free Levenberg-Marquardt optimizer that makes second-order optimization practical for 3DGS! 🚀
4
33
332
25,655
Mar 16
DLSS 5 is technically mind-blowing, but AI game-dev tools should: facilitate intent, give control, and cut costs. IMO the issue here was how NVIDIA marketed the thing. If they pitched this as real-time style filters (from photoreal to e.g., pixel art), we'd seen other reactions.
87
Mar 16
This day would come sooner or later, and now that I’m seeing it with my own eyes, I don’t know what to think. On the one hand, it’s impressive; on the other, scary. The gaming industry is changing forever.
Mar 16

Announcing NVIDIA DLSS 5, an AI-powered breakthrough in visual fidelity for games, coming this fall.
DLSS 5 infuses pixels with photorealistic lighting and materials, bridging the gap between rendering and reality.
Learn More → nvidia.com/en-us/geforce/new…
92
Mar 13
Automatising the mechanism, keeping the payroll. The contradiction is self-explanatory.
Mar 13

Introducing Junior
The first AI employee, for any role.
A true AI employee:
→ their own identity
→ organizational memory
→ self-driven
10 teams have been working with Junior every day.
Work was never the same since.
Starting at $2,000/month.
We’ve pre-paid $200 of your Junior’s salary.
Try Junior and experience the future of work today.
87
Mar 13
If "intelligence" is sold by a meter, those with more capital inherently possess more cognitive power, potentially turning human insight into a pay-to-play system.
Knowledge should always be open, and never a commodity.
Mar 12

🚨 SAM ALTMAN: “We see a future where intelligence is a utility, like electricity or water, and people buy it from us on a meter.”
1
53
Have you ever wondered if we could capture human movement without mocap suits, VR trackers, or camera setups? What if all you needed was a pair of everyday insoles? 👟
Introducing Step2Motion, accepted to #Eurographics2026!
📝Project Page: vcai.mpi-inf.mpg.de/projects…
🧵👇
10
32
251
17,836
Our multi-modal diffusion architecture captures a massive range of movement—from walking and jogging to crouching, tiptoeing, and even dancing!🕺
All of this is reconstructed using only 16 pressure sensors and an IMU per insole. #MotionCapture #Wearables #DiffusionModels
1
4
467
Huge congrats to Jose Luis Ponton and all co-authors! An amazing collaboration between @VcaiMpi and #ViRVIG @la_UPC!
🖥️Code: github.com/JLPM22/Step2Motio…
🗃️Data: gvv-assets.mpi-inf.mpg.de/st…
2
10
452
Having the accurate physical structure eliminates the need of training, as the weights are already “encoded”. It demonstrates that a complex biological organism's behavior is a direct result of its physical architecture - data was just our way to arrive there.

103
Today I saw a job posting, and the job description said “(Human)”. I wonder if there will be job openings for robots in the future, and if they will be able to apply for them “autonomously” based on their skills, with their owners getting paid. A new robotic revolution.
53
Auto-encoder mode ON.


59