
Follow @RobotsDigest for latest in Robotics, Humanoids, and Hardware AI.
Joined August 2025
- Tweets 2,180
- Following 0
- Followers 5,141
- Likes 241
1,557 Photos and videos
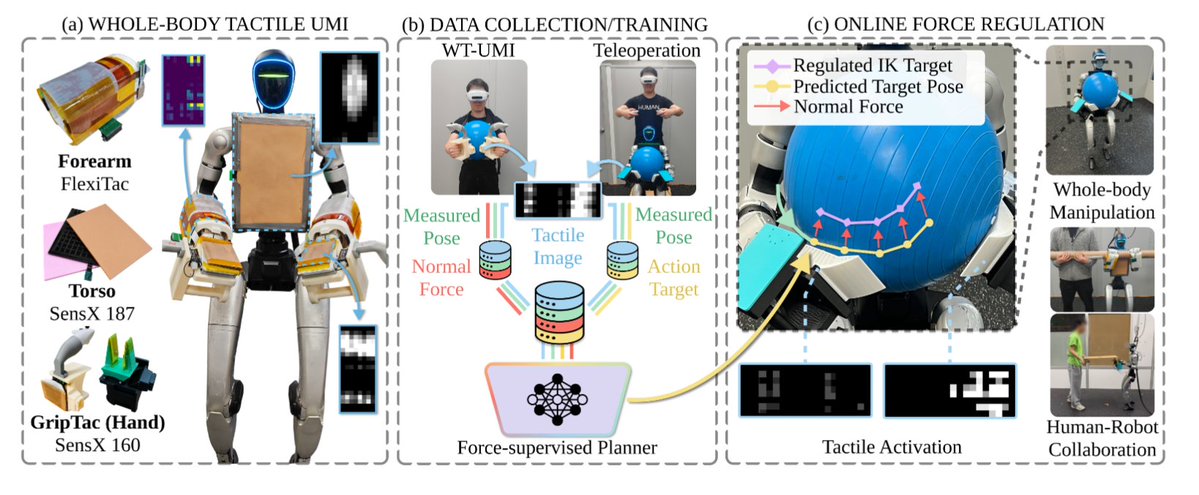










Most robot imitation learning treats contact force as a side effect.
WT-UMI argues that's the wrong abstraction.
When a humanoid carries a box, hugs a deformable object, or collaborates with a human, force is often the task. Not just pose.
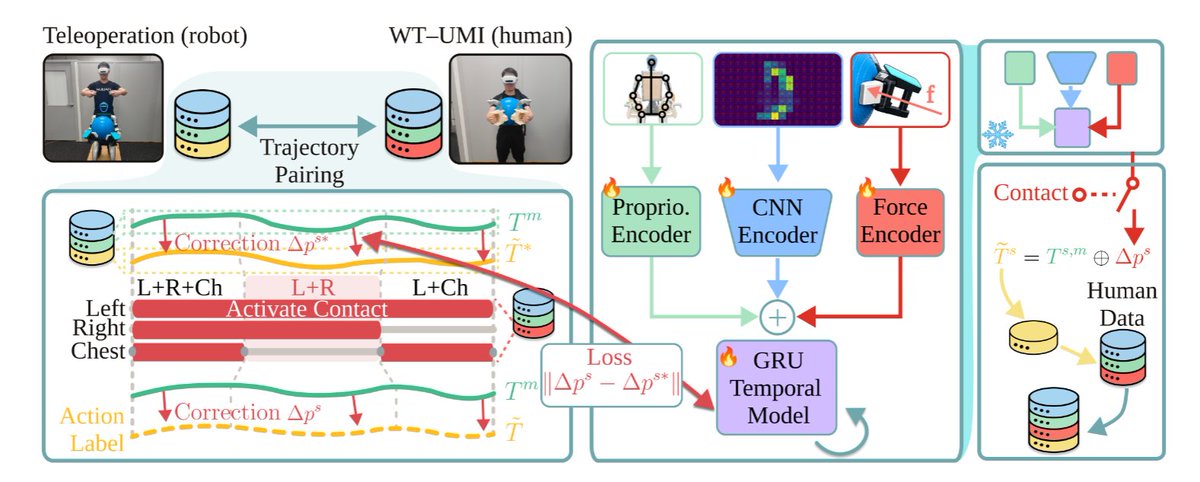
The key idea: collect whole-body tactile signals and explicitly plan contact forces, not only motions.
1
1
14
432
The most interesting contribution is the force-supervised planner.
Instead of predicting only future poses, it predicts:
• Pose trajectories
• Contact-force trajectories
Those predicted forces become references for a tactile-based admittance controller during execution.
Results across 5 contact-rich tasks show higher success rates and lower contact-position tracking error than multiple policy baselines.
Trend watch: tactile sensing is rapidly moving from "extra observation" → "first-class planning signal." WT-UMI is a strong example of that shift.
1
1
1
161
Vision foundation models got their ImageNet moment.
FTP-1 asks:
What if tactile manipulation had its own foundation model?
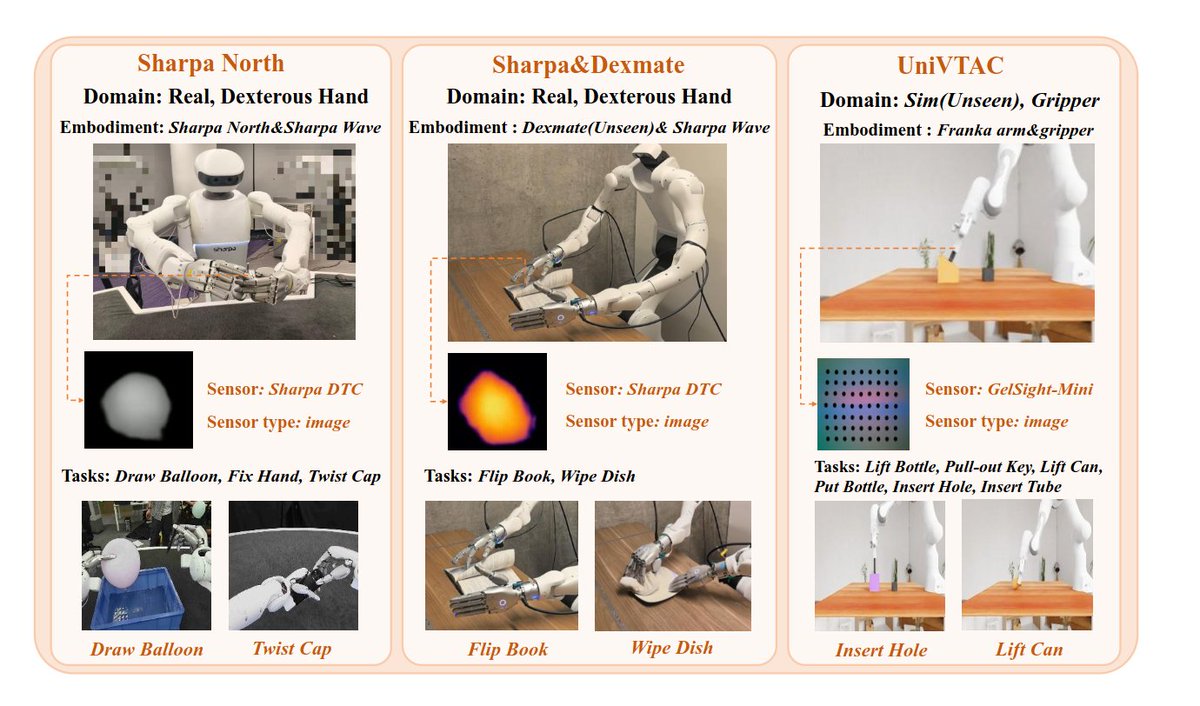
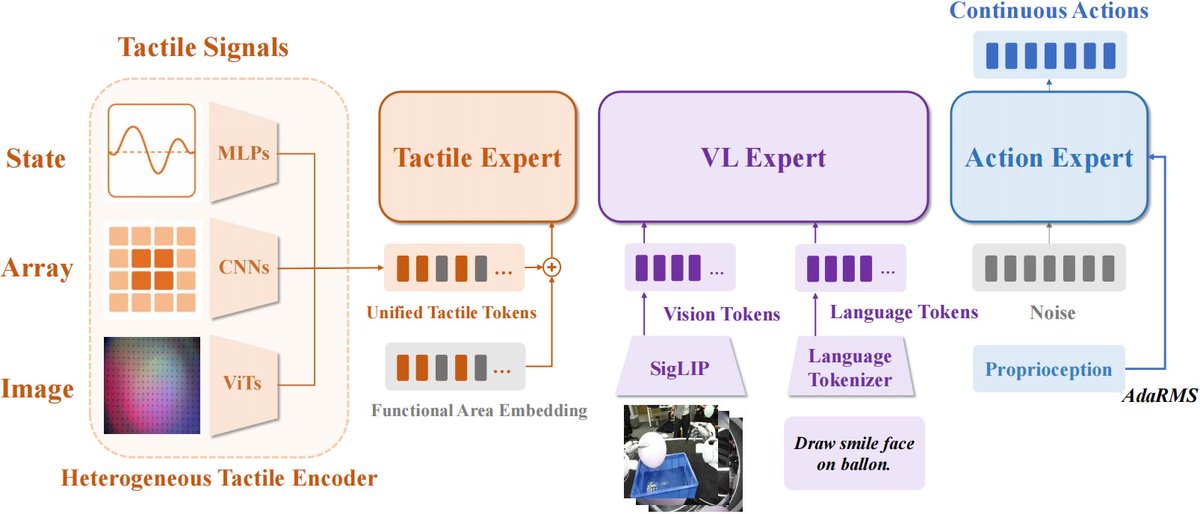
The challenge is that tactile data is far messier than images.
A GelSight image, a fingertip pressure array, and a force-torque sensor all produce completely different signals.
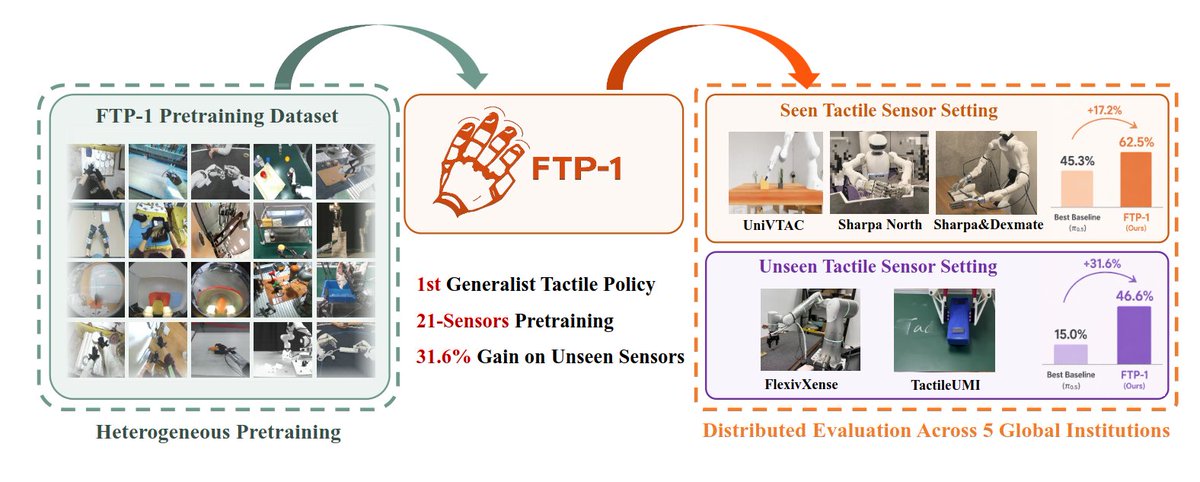
FTP-1 is the first attempt to build a generalist tactile policy that works across them all. It is pretrained on ~3,000 hours of tactile manipulation data from 26 datasets spanning 21 different tactile sensors.
1
8
38
1,485
The most interesting result isn't higher performance on known robots.
It's transfer.
After pretraining, FTP-1 can adapt to previously unseen tactile sensors while reusing the learned tactile knowledge.
Across experiments:
• 17.2% success on seen sensor setups
• 31% success on unseen tactile-sensor setups
This feels like an important shift:
Robotics may be moving from "build a policy for a sensor" → "pretrain tactile intelligence once, then plug in new sensors later."
For contact-rich manipulation, FTP-1 could become the tactile equivalent of what VLM pretraining did for robot vision.
1
3
208

Jun 13
Most multi-robot VLA systems either centralize everything or train a separate policy per robot. CHORUS asks a different question: can a single pretrained VLA coordinate an entire team using only each robot's local observations? The answer is yes. Each robot runs the same policy, receives a robot-specific identity prompt, and collaborates without communication, shared state, or per-robot policies.
1
7
42
2,626
Jun 13
Results are surprisingly strong. Across real-world tasks including tape measurement, book handovers, laundry basket lifting, and 3-robot transport, CHORUS improves success rates by 64 percentage points over decentralized policies trained from scratch, boosts teammate reactivity by 40 percentage points, and even outperforms centralized VLA baselines. A strong example of pretrained VLAs enabling scalable robot teamwork.
1
2
210
Jun 13
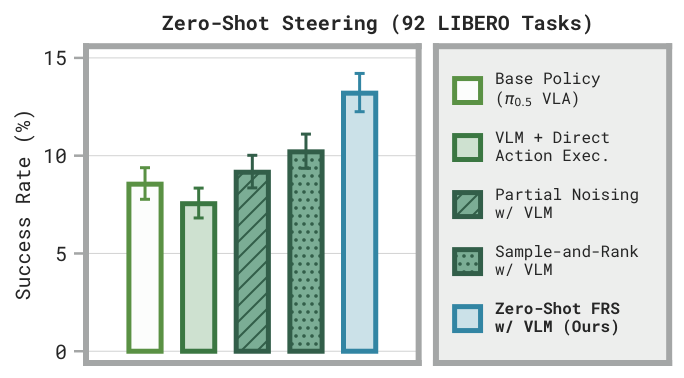
Generalist robot policies already contain many useful behaviors, but the challenge is invoking the right one for a new task. Flow Reversal Steering (FRS) introduces a simple idea: take a coarse action from a human or VLM, run it backward through a flow-matching policy to recover the latent noise, then denoise it back into a precise in-distribution robot action. Instead of directly executing rough guidance, FRS projects it onto behaviors the policy already knows.
3
8
52
3,115
Jun 13
FRS is not just an inference trick. The discovered latent noises can be distilled with Diffusion Steering via Behavioral Cloning (DSBC), training lightweight steering policies in under a minute, or used to bootstrap RL with semantic guidance. On real DROID tasks, DSBC significantly outperforms standard behavioral cloning, while FRS-bootstrapped RL succeeds on tasks where conventional RL makes little progress.
1
1
4
270
Jun 12
Robotic visual navigation under partial observability requires foresight: anticipating how moving changes your view and if it brings you closer to the goal. Prior world models predict these futures but rely on slow, external CEM-style planners to choose actions.
3
12
58
3,943
Jun 12
By unifying prediction and control, NavWAM acts as a closed-loop policy out of the box. In evaluations, it outperforms planning-based world models without needing test-time action search, matches a much larger 7B VLA policy, and transfers successfully to real mobile robots.
1
6
40
10,283