Machine Learning and Nonparametric Statistics Researcher
- Tweets 272
- Following 202
- Followers 146
- Likes 1,879

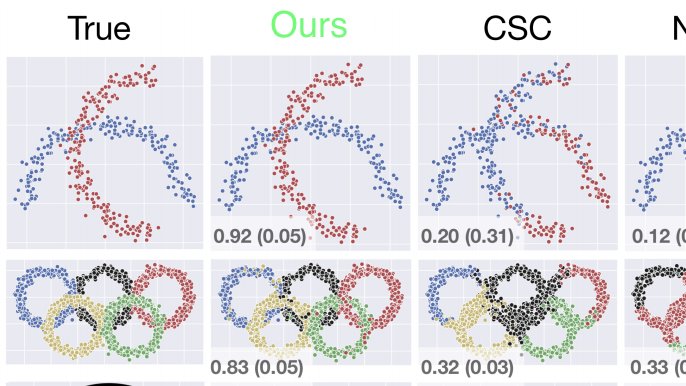




ALT Set Learning for Accurate and Calibrated Models” is accepted at the 12th International Conference on Learning Representations (ICLR) 2024. Authors: Lukas Muttenthaler, Robert A. Vandermeulen, Qiuyi Zhang, Thomas Unterthiner, Klaus-Robert Müller Wrap up: Are you worried about miscalibration of your model outputs but tired of post-hoc temperature scaling and think label smoothing is a hack? Then just train with OKO - a principled set learning approach for more accurate and better calibrated models. OKO is very simple to use: Just change your sampling strategy from standard single data point sampling to set sampling and compute cross-entropy for the sum of set data point logits rather than for single data point logits. Because this forces a model to bring all class logits onto the same scale, your model will be much better calibrated!