
Postdoc @berkeley_ai. Researcher @IBMResearch. PhD @TelAvivUni. Working on Multimodal Robot Foundation Models and Structured Physical AI.
Joined March 2017
- Tweets 2,241
- Following 908
- Followers 1,772
- Likes 8,550
170 Photos and videos











Pinned Tweet

20 Dec 2025
🚨Humanoid learning faces a major data gap: existing policies are trained on just a few hours of data. Video generation models offer a scalable bridge.
Our new work shows how a humanoid can execute human actions from generated videos zero-shot.
@berkeley_ai @nyuniversity Kepler
6
23
189
33,652
Jun 11
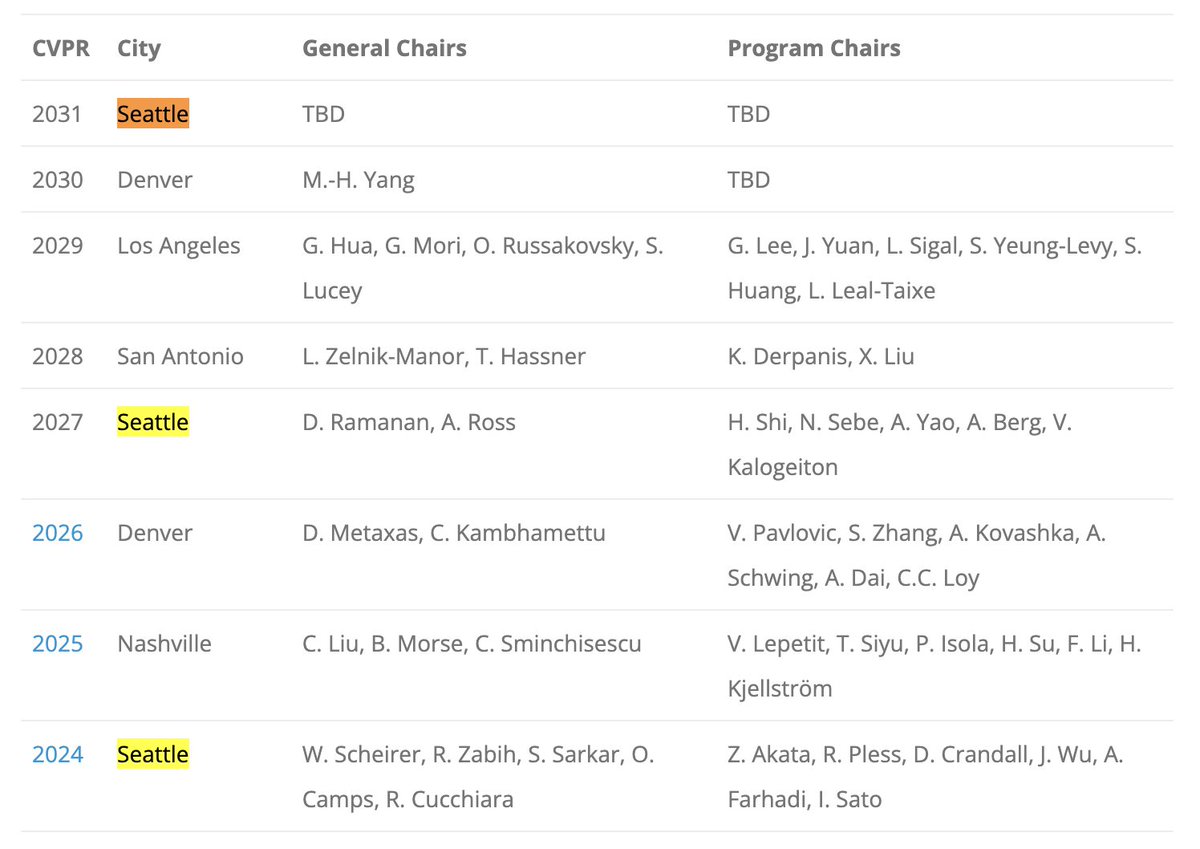
Because Seattle is awesome, and one of the few places that can accommodate such a big conference?

2
7
3,844
Roei Herzig retweeted

The videos from the “Frontiers of Embodied AI” meetup at ETHZ from a few weeks back are now available.
Speakers: Jitendra Malik, Vladlen Koltun, Yann LeCun, and Shuran Song
Hosted by Marc Pollefeys
YouTube playlist: youtube.com/playlist?list=PL…



2
20
112
18,701
Jun 9
If you ever wondered what a family of computer scientists talks about over dinner, apparently it’s new models of consciousness. 🧠🍽️
Or at least that’s how dinner goes in the Blum family: Lenore, Manuel, and Avrim. Such an inspiring family! 😄
Jun 9

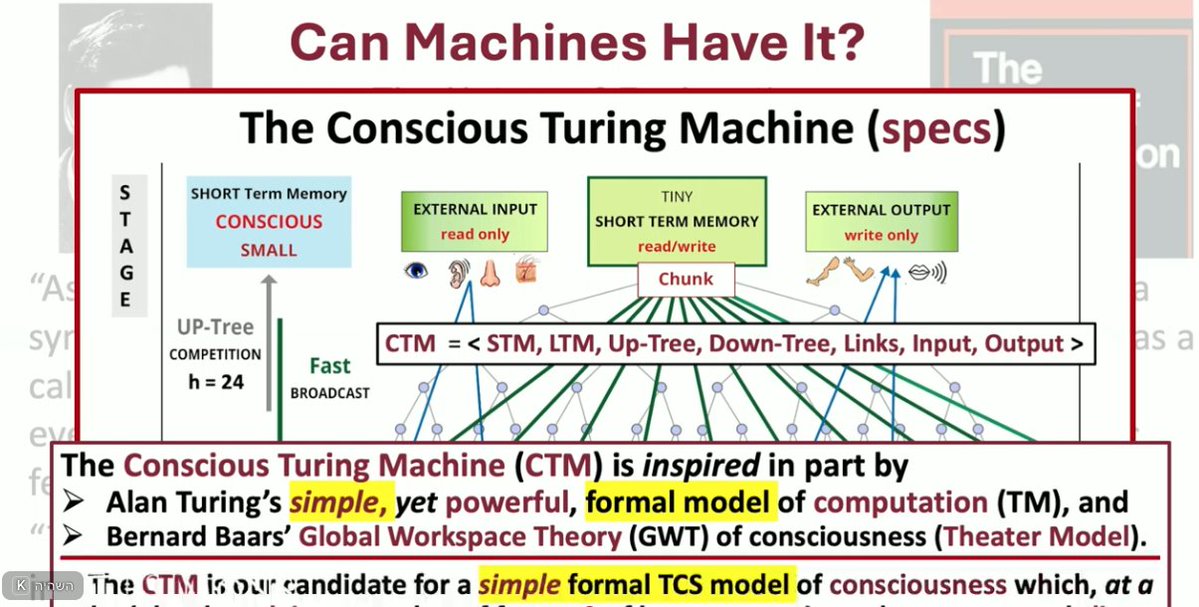
Lenore Blum (Carnegie Mellon University) presents a really nice, slightly different definition of world models.
1
286
Jun 9
Lenore Blum (Carnegie Mellon University) presents a really nice, slightly different definition of world models.
2
4
59
3,712
Jun 8
Wow, must've destroyed a lot of robots making this 🤣
Jun 8

🪜 What if humanoids could climb ladders and work on them straight out of simulation?
Meet LadderMan: a perceptive system for zero-shot sim-to-real ladder climbing and on-ladder manipulation.
Watch the humanoid climb, stabilize, and manipulate—all in one system. 🤖👇
1
2
10
1,627
Roei Herzig retweeted

Jun 8
Full video - youtube.com/live/cFwHAMf0kEc…
Jun 8
Jack Gallant (UC Berkeley), in his talk “Representation of the World in the Human Brain,” made a really interesting observation about world models: evidence that the mammalian brain implements a Generative World Model is "shockingly poor".
4
10
1,575
Jun 8
Jack Gallant (UC Berkeley), in his talk “Representation of the World in the Human Brain,” made a really interesting observation about world models: evidence that the mammalian brain implements a Generative World Model is "shockingly poor".
8
26
331
27,373
Jun 8
"Generative World Models are highly correlated with other theories."
Isn’t that expected, given that the laws of nature apply to humans as well?
1
1
21
1,879
Jun 8
💯💯💯

#KostasThoughts: I’ve been thinking about the criteria for award-winning papers 🏆 They should embody what our community values most: originality, potential impact, and reproducibility. Yet (full) reproducibility is often missing, even among award-winning papers.
Making code and model weights publicly available should be a criterion for award consideration. This would send a strong signal to decision-makers in both academia and industry about the importance of open and reproducible research.
Papers would receive the recognition they deserve, while the community would gain a deeper understanding of the engineering innovations that drive performance.
Thoughts?
1
825
Jun 8
A wonderful workshop on Embodied AI cognition is happening this week at the Simons Institute.
You can watch it remotely!

Our @SimonsInstitute workshop on intelligence starts tomorrow (June 8)!
We're bringing together researchers from AI, TOC, Psych, and Neuro to discuss two emerging themes: world models and social cognition.
Join us in Berkeley or via livestream: simons.berkeley.edu/workshop…
3
7
2,425
Jun 8
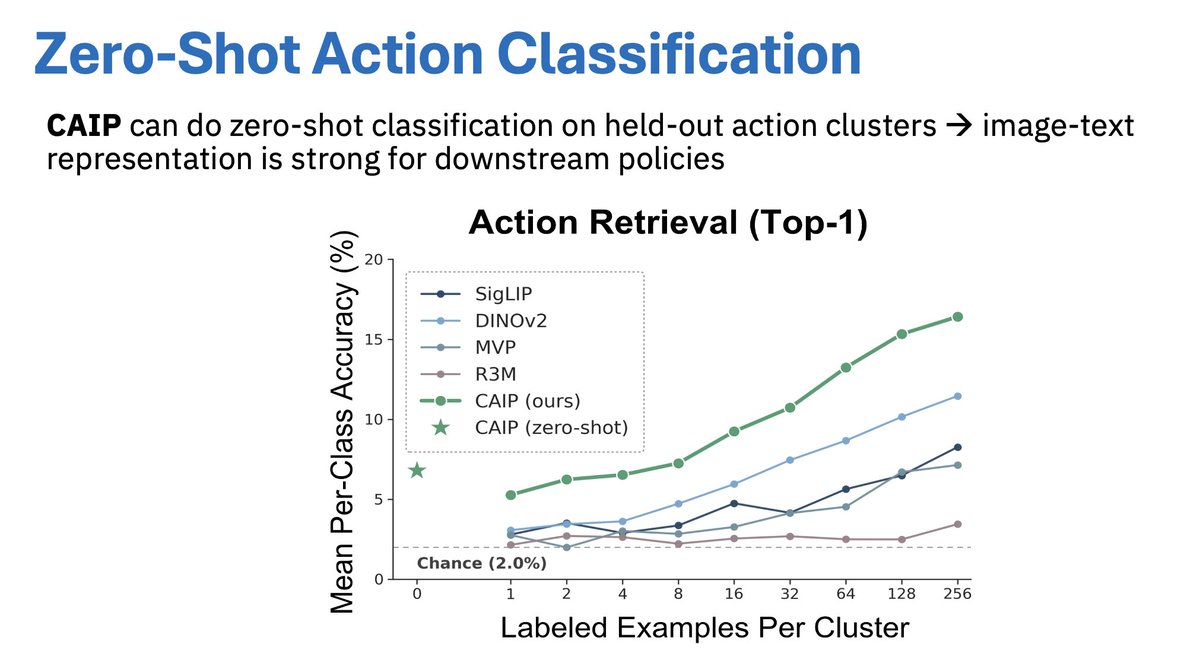
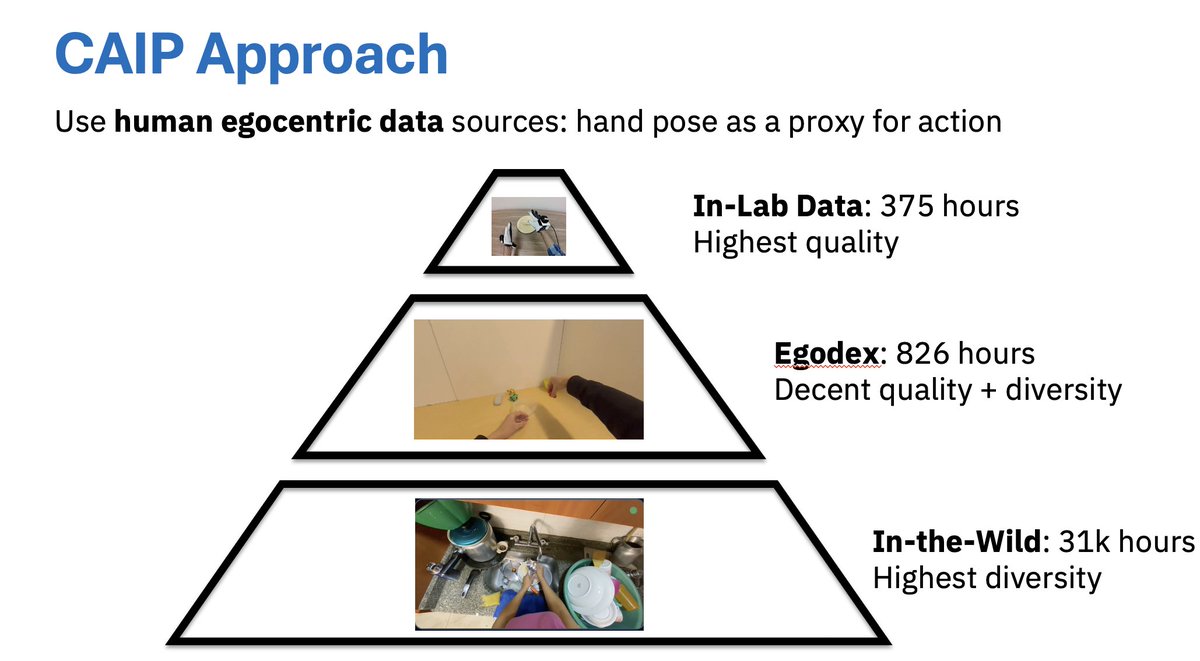
Our recent vision encoder for dexterous manipulation used the @SharpaRobotics hand as it offers the real-world use case for real-world tasks. No more toy tasks.
That level is what's needed to demonstrate real progress.
x.com/i/status/2063263699750…
Jun 8

The SharpaWave hand is really good but the main thing it has is tactile resolution -- thousands of pixels. Huge if you are an AI lab, which is presumably why nvidia picked it for their reference hardware. The price will come down but you want that data
2
1
13
5,252
Jun 7
Oh wow, this is really cool work. You can imagine using the latent action space to localize 3D hand coordinates, which could enable massive pretraining on egocentric data for dexterous manipulation.
Jun 7

What if a self-driving car could learn its position just by watching millions of hours of driving video?
Researchers at Wayve and Simon Fraser University introduce LA-Pose: they train a model to learn "latent actions"—hidden motion patterns—from unlabeled driving footage, then repurpose those features for camera pose estimation using a tiny amount of 3D-labeled data.
Result: LA-Pose beats top feed-forward methods by over 10% on Waymo and PandaSet, while needing orders of magnitude fewer labeled examples. First proof that self-supervised inverse-dynamics can power pose estimation.
LA-Pose: Latent Action Pretraining Meets Pose Estimation
Project: la-pose.github.io/
Paper: arxiv.org/abs/2604.27448
Blog: wayve.ai/thinking/la-pose/
Our report: mp.weixin.qq.com/s/XoUvfQQoj…
📬 #PapersAccepted by Jiqizhixin

2
689
Jun 7
You could also cross the street without looking, but it's still a terrible idea.
Jun 7

AlexNet, Seq2seq, Transformer released neither code nor weights.
ResNet, GPT2, BERT, CLIP did not release source code, just weights.
1
3
572