
multimodal @thinkymachines. I also like to climb rocks and throw pottery. rowanzellers.com (he/him)
Joined November 2008
- Tweets 614
- Following 1,031
- Followers 15,367
- Likes 1,321
40 Photos and videos













Pinned Tweet

May 11
We are so back!
May 11

People talk, listen, watch, think, and collaborate at the same time, in real time. We've designed an AI that works with people the same way.
We share our approach, early results, and a quick look at our model in action.
thinkingmachines.ai/blog/int…
37
17
542
53,238
May 19
Grants for research on interactivity, realtime video/audio full duplex evals, and safety
May 19
We are offering grants of $100,000 Tinker credits to researchers advancing the field of human-AI interactivity. Submit your proposals by June 19th!
thinkingmachines.ai/news/int…
4
10
111
25,742
Rowan Zellers retweeted

May 16
Big congratulations to Dr. @ziqiao_ma, well deserved! 🎉👏
Excited for your new chapter at @thinkymachines!



1
2
32
5,139
Rowan Zellers retweeted

May 11
P.S. The demo is basically my life at thinky: I start to cut coffee, @liliyu_lili is visually prompt-injecting my human intelligence with sweet snack every day, and I've gained weight since joining TML.
6
10
136
19,811
Rowan Zellers retweeted

May 12
Congrats Rowan and Thinky team on the cool release!
I remember you mentioned having a v different vision of multimodal interactions a few weeks ago @rown so this is what that looks like! 🆒
It’s exciting to see this release going beyond just a single model, showcasing truly different native multimodal interactions too.
A couple things from the nicely written blog really resonate with me:
1. people are most effective when they can collaborate with AI the same way they do with other people
2. existing interfaces limit human inputs (esp multimodal ones) to the model, and this input limit needs to be lifted to unlock much better interactivity
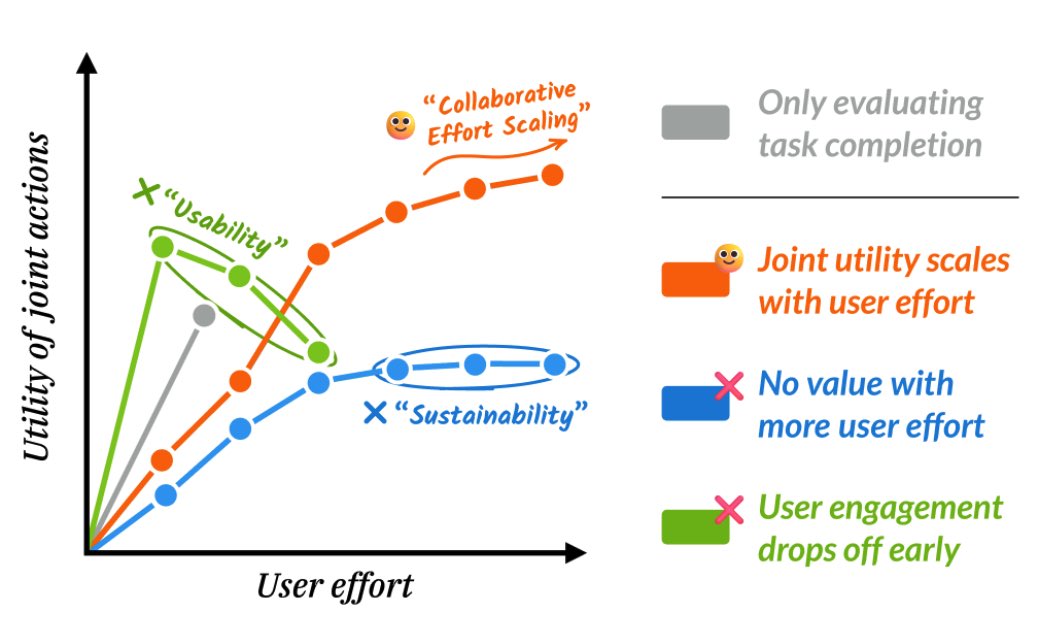
The blog also reminds me of the fun and challenging discussions with @shannonzshen and others on what “scaling collaboration” can look like. we made an initial attempt describing our vision: arxiv.org/pdf/2510.25744
It’d be great to see more human centric evaluations of the model/system/interface too — looking forward to it🥂
May 11

We are so back!
6
65
7,176
Rowan Zellers retweeted

May 11
We started Thinking Machines to advance human-AI collaboration, and this is our first bet on what that looks like. Most labs treat autonomy as the goal and interactivity as scaffolding around a turn-based core. We think the way we work with AI matters as much as how smart it is. Interactivity has to be in the model, and it has to scale with intelligence rather than trail behind it.
thinkingmachines.ai/blog/int…
34
41
811
58,672
Rowan Zellers retweeted

May 11
In the past few months, we had a lot of fun (and stress 😅) to produce 12 versions ( many subversions) and 137 pages in our training run log book.
Turns out human-human collaboration is important to improving human-AI collaboration. 😊

May 11
People talk, listen, watch, think, and collaborate at the same time, in real time. We've designed an AI that works with people the same way.
We share our approach, early results, and a quick look at our model in action.
thinkingmachines.ai/blog/int…
46
48
947
179,887
Rowan Zellers retweeted

May 11
Very excited to share a preview of what we’ve been working on!
May 11
People talk, listen, watch, think, and collaborate at the same time, in real time. We've designed an AI that works with people the same way.
We share our approach, early results, and a quick look at our model in action.
thinkingmachines.ai/blog/int…
1
1
24
1,672
Rowan Zellers retweeted

May 12
Thinky’s new interaction models perform search in the background when listening and responding so you don’t notice!
Also per request: Spoiler Alert 🚨
May 11
The model can multi-task!
Long thinks the model knows everything, but the model actually searched while listening and responding to him so he didn't notice.
2
1
25
2,884

My first share since joining @thinkymachines. Fun working with this team on real-time multimodal interaction. Vision in turn-based models felt like flipping through photos — continuous video is a different problem.
Visual proactivity is essential — grateful to have worked on this alongside @liliyu_lili, @rown , and the rest of the team!
May 11
People talk, listen, watch, think, and collaborate at the same time, in real time. We've designed an AI that works with people the same way.
We share our approach, early results, and a quick look at our model in action.
thinkingmachines.ai/blog/int…
6
5
157
10,568
Rowan Zellers retweeted

I'm excited to share some of our work at @thinkymachines. As models get more intelligent, the bottleneck is increasingly how quickly and seamlessly we can access their intelligence, and today we are sharing a preview of how we think about human-AI collaboration.
May 11
People talk, listen, watch, think, and collaborate at the same time, in real time. We've designed an AI that works with people the same way.
We share our approach, early results, and a quick look at our model in action.
thinkingmachines.ai/blog/int…
2
2
79
5,119
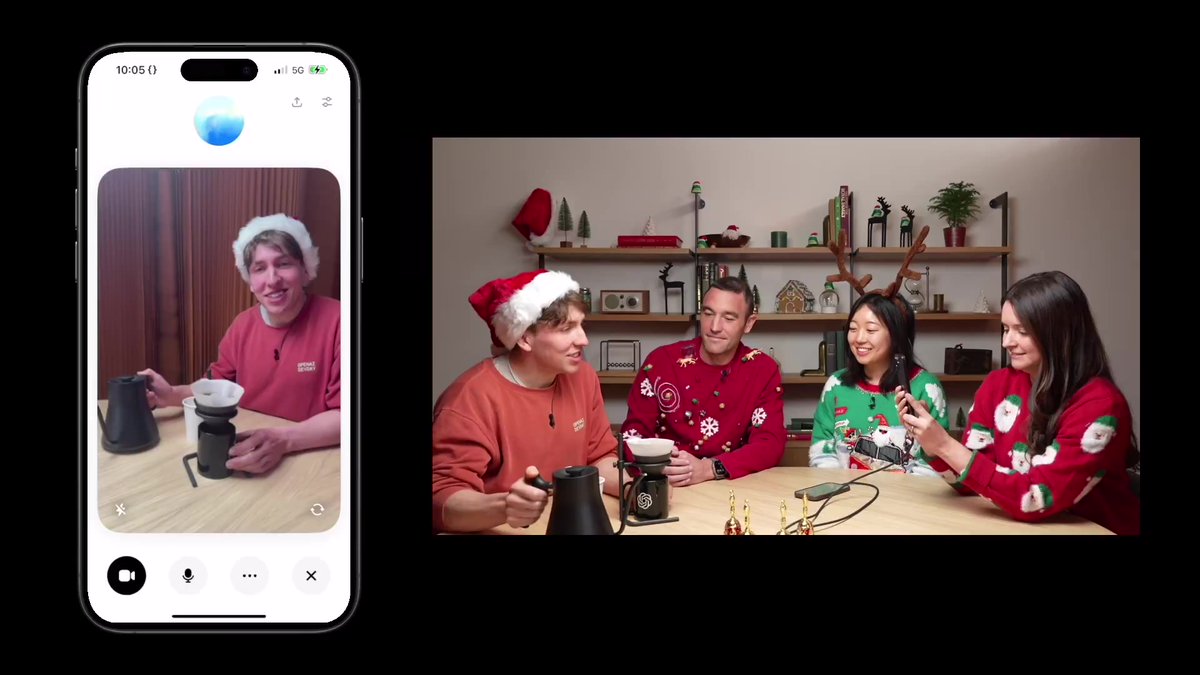
May 11
Our interaction model is the first general video speech model that's visually proactive. It was super fun working on this with @liliyu_lili / @saurabh_garg67 / @AndreaMadotto and others - after countless versions it was amazing when visual interruptions suddenly worked!
May 11

We’re interested in AI systems that can collaborate in real time, without relying only on artificial turn boundaries.
For audio, this feels natural: listen, speak, interrupt, update.
For video, we think an important version of this is visual proactivity — models that respond when something happens visually:
“Tell me when I start slouching.”
“Count my pushups.”
“Say stop when the person stops doing X.”
6
6
135
11,259
May 11
If you're interested in working on realtime video speech specifically, or human AI collaboration more generally, please reach out!
1
24
1,103
Rowan Zellers retweeted

May 11
We’re interested in AI systems that can collaborate in real time, without relying only on artificial turn boundaries.
For audio, this feels natural: listen, speak, interrupt, update.
For video, we think an important version of this is visual proactivity — models that respond when something happens visually:
“Tell me when I start slouching.”
“Count my pushups.”
“Say stop when the person stops doing X.”
May 11
Tessa's quality of life has improved a lot with some nagging.
8
5
74
16,405
Rowan Zellers retweeted

May 11
Lili and Martin get some help controlling themselves.
15
21
613
168,736
Rowan Zellers retweeted
May 11
People talk, listen, watch, think, and collaborate at the same time, in real time. We've designed an AI that works with people the same way.
We share our approach, early results, and a quick look at our model in action.
thinkingmachines.ai/blog/int…
464
1,959
15,789
7,750,163
Rowan Zellers retweeted

Apr 23
vision🍌 is here vision-banana.github.io/
if you got into computer vision the way I did, starting with pixel-level labeling tasks like segmentation, edges, depth, or surface normals, you’ll probably feel the same seeing these results -- something big has quietly shifted, and it’s going to change how we approach these problems for good 🧵
11
112
789
65,978
Rowan Zellers retweeted

Apr 22
me: Make me the most AI slop image that ever AI slopped. The pinnacle of slop. A seminal work on AI slop.
ChatGPT Images 2.0:

209
199
2,591
931,292
Apr 22
Feels like the SOTA way to download files on google drive in 2026 is to sic claude code/codex at the directory and have it figure it out 🥲
1
28
4,391
Apr 21
welcome Weiyao!!

After 8 years at Meta (FAIR/MSL) working on multi-modal perception and generations — Gradient-Blending, UVO, SAM3D — I've joined @thinkymachines this week to keep working on multi-modal. Excited for what's ahead.
1
22
6,217