
Joined March 2013
- Tweets 3,439
- Following 391
- Followers 1,015
- Likes 2,495
82 Photos and videos








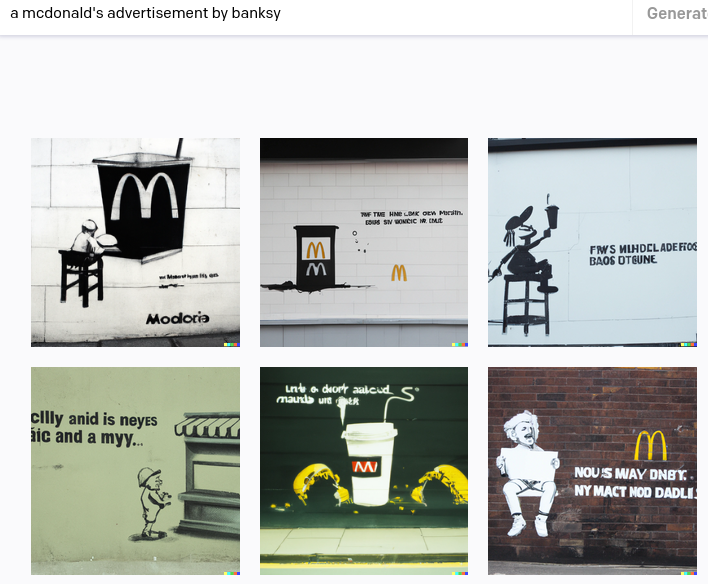

Pinned Tweet

5 Dec 2022
My new book is finally out!
Thanks to everyone who has helped make this a reality! Please check it out if you haven't already.
5 Dec 2022

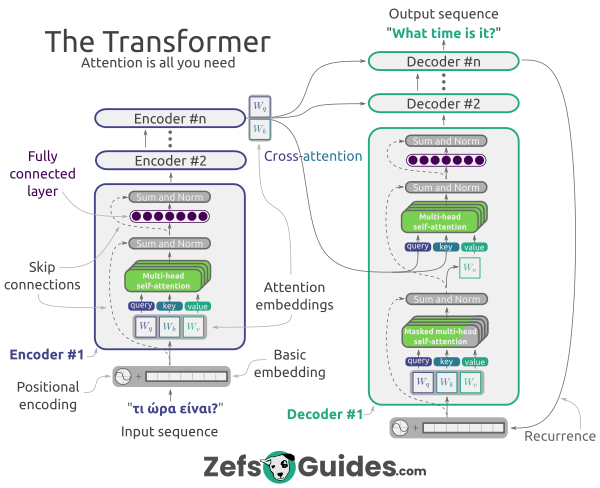
🎉🎉Zefs Guide to Deep Learning is finally out🎉🎉
Covering the most important concepts in deep learning, it takes you from basic ML all the way to Transformers and Stable Diffusion
The paperback, ebook, and digital flashcards are all available now at zefsguides.com

ALT Picture of the front cover of the paperback version of Zefs Guide to Deep Learning

ALT Picture of the back cover of the paperback version of Zefs Guide to Deep Learning
1
1
12
Roy K retweeted

16 Jun 2025
RT to help Simon raise awareness of prompt injection attacks in LLMs.
Feels a bit like the wild west of early computing, with computer viruses (now = malicious prompts hiding in web data/tools), and not well developed defenses (antivirus, or a lot more developed kernel/user space security paradigm where e.g. an agent is given very specific action types instead of the ability to run arbitrary bash scripts).
Conflicted because I want to be an early adopter of LLM agents in my personal computing but the wild west of possibility is holding me back.
16 Jun 2025

If you use "AI agents" (LLMs that call tools) you need to be aware of the Lethal Trifecta
Any time you combine access to private data with exposure to untrusted content and the ability to externally communicate an attacker can trick the system into stealing your data!
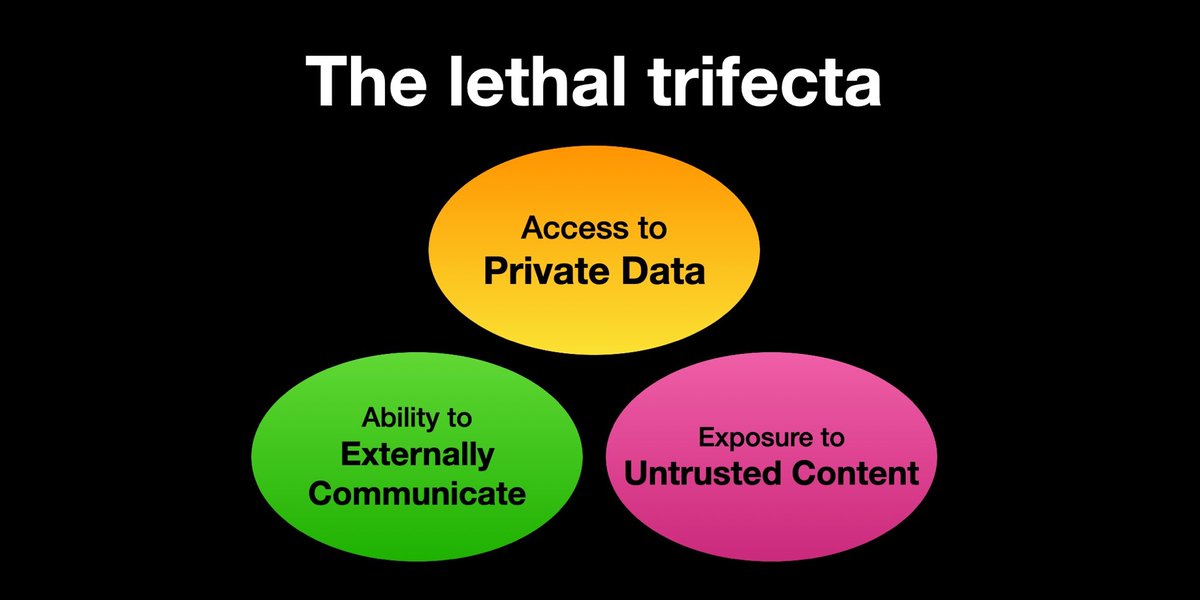
ALT The lethal trifecta (diagram with three circles): access to private data, ability to externally communicate, exposure to untrusted content
101
512
2,991
434,889
Roy K retweeted

1 Apr 2024
I just posted the first of what will be several chapters about transformers, which in the last year has been the most requested topic for the channel.
youtu.be/wjZofJX0v4M
22
172
813
63,203

I wrote a very long post on what a machine learning artifact is, how files work, safetensors, pickle, and a lot more, as a way to understand GGUF.
Thanks especially to everyone in this thread who added historical context around safetensors.
vickiboykis.com/2024/02/28/g…


Continuing digging deep on GGUF. Anyone have information/oral history of how we went from pickle in pytorch to safetensors, with explicit details around what actually is in a .pt file/state dictionary? Yep, I've looked at all the code/docs, I'm now looking for commentary
10
62
304
59,706
Evaluating LLMs is HARD, so I'm excited to share a bit of what we've been working on at @MozillaAI from the NeurIPS 1 LLM 1GPU 1Day challenge last fall.
The write-up includes background on eval repo with sample K8s infra. More soon!
blog.mozilla.ai/exploring-ll…
9
33
235
18,643
Roy K retweeted

6 Feb 2024
🚀 I've just launched the landing page for the Python Developer Tooling Handbook!
A free ebook where I will dive deep into the tools that make Python development a breeze (from packaging to linting, type checking to formatting).
Check it out 👉 pydevtools.com/
3
31
144
25,245

Hiring Data Scientists and Machine Learning Engineers by Roy Keyes is on sale on Leanpub! Its suggested price is $34.99; get it for $10.00 with this coupon: leanpub.com/sh/YsllZwVP @roycoding #Ai #BusinessAndManagement #DataScience #EngineeringManagement #MachineLearning
1
4
331
Zefs Guide to Deep Learning Flashcards (Flashcards (PDF, Anki, PNG formats)) by Roy Keyes is on sale on Leanpub! Its suggested price is $25.00; get it for $10.00 with this coupon: leanpub.com/sh/HUDnTw8B @roycoding #Ai #MachineLearning #DigitalTransformation
1
1
315
4 Dec 2023
Giving away free stuff is a lot of effort 😎, but so far a lot of people have picked up free copies of my deep learning book.
Right now I just want to get it out there.
I promise that reading it is much, much easier than writing it was! Check it out!
4 Dec 2023
Thanks to everyone who promoted my give away on @leanpub, Zefs Guide to Deep Learning is now the #1 free machine learning and AI book on Leanpub!
Please retweet to see if I can really give away 1,000 copies🎅🎁🎅🎁
leanpub.com/zefsguide2dl/c/F…
176
1 Dec 2023
I honestly think this is a better book than a lot of what's out there on machine learning and deep learning.
It's a short book covering the most important concepts in the current AI techniques.
I want to let people know that they can get it for free, so please retweet 🙏
1 Dec 2023
I want to give away 1,000 copies of the Zefs Guide to Deep Learning ebook! 🎅
Please retweet if you know anyone who wants to learn about the tech powering AI, ChatGPT, and Stable Diffusion🤖
Right now the ebook is free!
(or pay-what-you-want)
leanpub.com/zefsguide2dl/c/F…

1
7
8
1,431
24 Nov 2023
Buy the paperback of Zefs Guide to Deep Learning and then pick up a free copy of the ebook to get updates (goodbye typos 👋) and learn anytime, anywhere.
24 Nov 2023
ChatGPT and all the LLMs you hear about are powered by Deep Learning.
Give the gift of knowledge this year with a copy of Zefs Guide to Deep Learning 🎁
The ebook is free (or pay what you want). The paperback is an even better present!
zefsguides.com
1
226
Roy K retweeted
23 Nov 2023
New YouTube video: 1hr general-audience introduction to Large Language Models
youtube.com/watch?v=zjkBMFhN…
Based on a 30min talk I gave recently; It tries to be non-technical intro, covers mental models for LLM inference, training, finetuning, the emerging LLM OS and LLM Security.

523
2,743
16,583
5,122,671
Roy K retweeted

15 Nov 2023
David Attenborough is now narrating my life
Here's a GPT-4-vision @elevenlabs python script so you can star in your own Planet Earth:
689
4,416
25,763
3,994,956

5 Nov 2023
There's wide consensus on this idea
5 Nov 2023

Whenever a person justifies some argument with “people say” or “community Y says”, don’t believe them. Ask for specific names and talk to them yourself.
In my experience 95% of the time they don’t actually believe what the original person was claiming.
357
28 Oct 2023
Here's a nice write-up on the mechanics of Retrieval Augmented Generation:
github.com/pchunduri6/rag-de…
915
The bundle The Machine Learning Manager Bundle by Roy Keyes is on sale on Leanpub! Its suggested price is $69.99; get it for $22.20 with this coupon: leanpub.com/b/mlmanager/c/Le… @roycoding #Ai #BusinessAndManagement #DataScience
1
1
265
Roy K retweeted

23 Oct 2023
True, personally, I think the best and shortest definition is that
"Embeddings are learned transformations to make data more useful" from Roy Keyes.
But a few examples like in Simon's blog post help illustrate the useful part.
roycoding.com/blog/2022/embe…
23 Oct 2023
If you're puzzled at why there's so much activity around "vector databases" at the moment, understanding embeddings should answer that question too
1
4
46
5,354
Hiring Data Scientists and Machine Learning Engineers by Roy Keyes is on sale on Leanpub! Its suggested price is $34.99; get it for $10.00 with this coupon: leanpub.com/sh/aPYd0bju @roycoding #Ai #BusinessAndManagement #DataScience #EngineeringManagement #MachineLearning
1
2
427
The bundle Zefs Guide to Deep Learning: Book Flashcards by Roy Keyes is on sale on Leanpub! Its suggested price is $60.00; get it for $14.00 with this coupon: leanpub.com/b/zefsguide2dl/c… @roycoding #ComputerProgramming #Ai #MachineLearning
2
226