
Making reward go up
Joined January 2025
- Tweets 23
- Following 13
- Followers 186
- Likes 98
11 Photos and videos








RunRL retweeted

21 Oct 2025
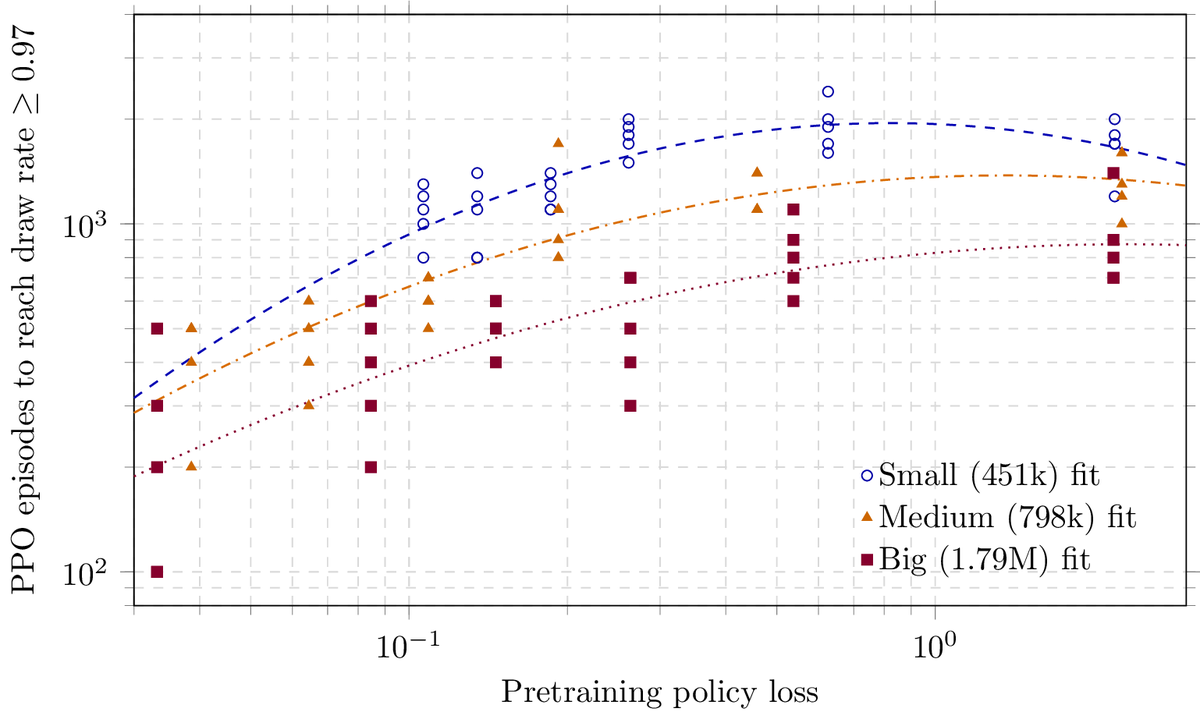
new @runrl_com blog post: i pretrained a tiny transformer model on perfect tic tac toe moves and measured how much it affects RL compute requirements
2
1
5
870

29 Sep 2025
This is the one thing we won't run RL on
26 Sep 2025

Closing the RL loop. Instead of independent slop creators competing and TikTok determining the winners to show people, this turns the entire slop economy into an end-to-end differentiable monstrosity that we can point ADAM at and further hollow out the brains of young children.
3
927
RunRL retweeted

25 Sep 2025
I have been waiting for this to drop for months

1
13
3,941
RunRL retweeted

25 Sep 2025
A cool technique from the RunRL research team: using PD controllers to balance multiobjective loss functions!
Suppose you want to train a model to give short yet relevant answers. For a given minimum level of relevance, this lets us improve on the other reward terms much more!

1
3
11
1,179
RunRL retweeted
17 Sep 2025
if you've ever wanted to run rl there's never been a better time to do it than now

2
1
9
473
20 Aug 2025
We've got the sauce!
13 Aug 2025

Someone from @runrl_com handed me a frikin bottle of AI sauce at Defcon what even hahaha

4
377
RunRL retweeted
22 May 2025
opus 4 generating the RunRL headquarters in tikz

1
6
684
17 May 2025
Excited for our YC launch! If you need RL, you know where to go 😎
17 May 2025

RunRL (@runrl_com) improves language models and agents with the power of reinforcement learning. Their customers have been able to go from 60% accuracy with Claude to 95% accuracy with RunRL.
ycombinator.com/launches/NXH…
Congrats on the launch, @dyushag and @dozenaltech!
3
1
16
3,209
16 May 2025
Have you ever wondered what the funniest joke in the world is? Well, with the power of RL, we can find out!
7
5
61
9,042
RunRL retweeted

30 Apr 2025
I am afraid to report, RL works.
25
36
831
111,574