
Reverse engineering intelligent (learning) systems.
Joined February 2019
- Tweets 63
- Following 86
- Followers 172
- Likes 144
21 Photos and videos











13h
Aspen Colorado
Working on a couple of interp related blog posts while I'm here.



1
37
May 27
Spending some time this week speeding up and scaling Anthropic's circuit-tracer implementation. Feel free to comment feature requests.
Will post progress here.
1
2
242
May 27
Some early benchmarks on the attribution step:
- Consistently 3.4x faster than circuit-tracer
- Much more memory efficient (~6 GB less at 70,000 nodes)
So far, these gains are from dropping the autodiff backend and exploiting an autoregressive causality trick (performing backward only through previous token positions).
All results still 1:1 numerically matching Anthropic's implementation (up to bf16 precision). Further speedups will likely come from approximation (edge pruning, sparse intermediates, etc...) that diverge from circuit-tracer slightly.
Benchmarking done on Qwen3-4B
1
1
174
Jun 12
Fable found another 2x on top of this. Now 6-8x faster than the public circuit-tracer implementation.
This additional 2x: Exploit GQA weight sharing (Qwen shares V-weights across query heads) and pre-transpose weights into GEMM-friendly layouts.
1
41
Jun 11
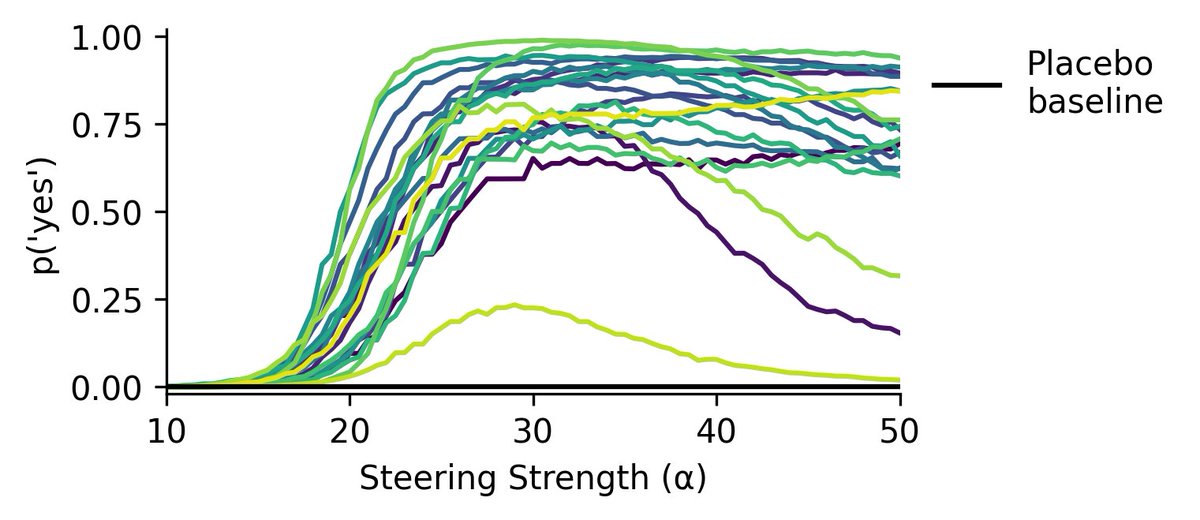
Probability of Qwen introspecting that it's being steered at various steering strengths. Each line is a different concept, except for the black line which is the placebo baseline. There is an obvious increase around alpha=20.
Prompt: "Am I injecting a thought right now? Answer with a single word: yes or no."
Steering at layers 20-31 in Qwen3-14b. Vectors extracted with repeng.
1
12
811
Jun 10
From my experience, any kind of neuroscience work is getting flagged :(
1
82
Jun 9
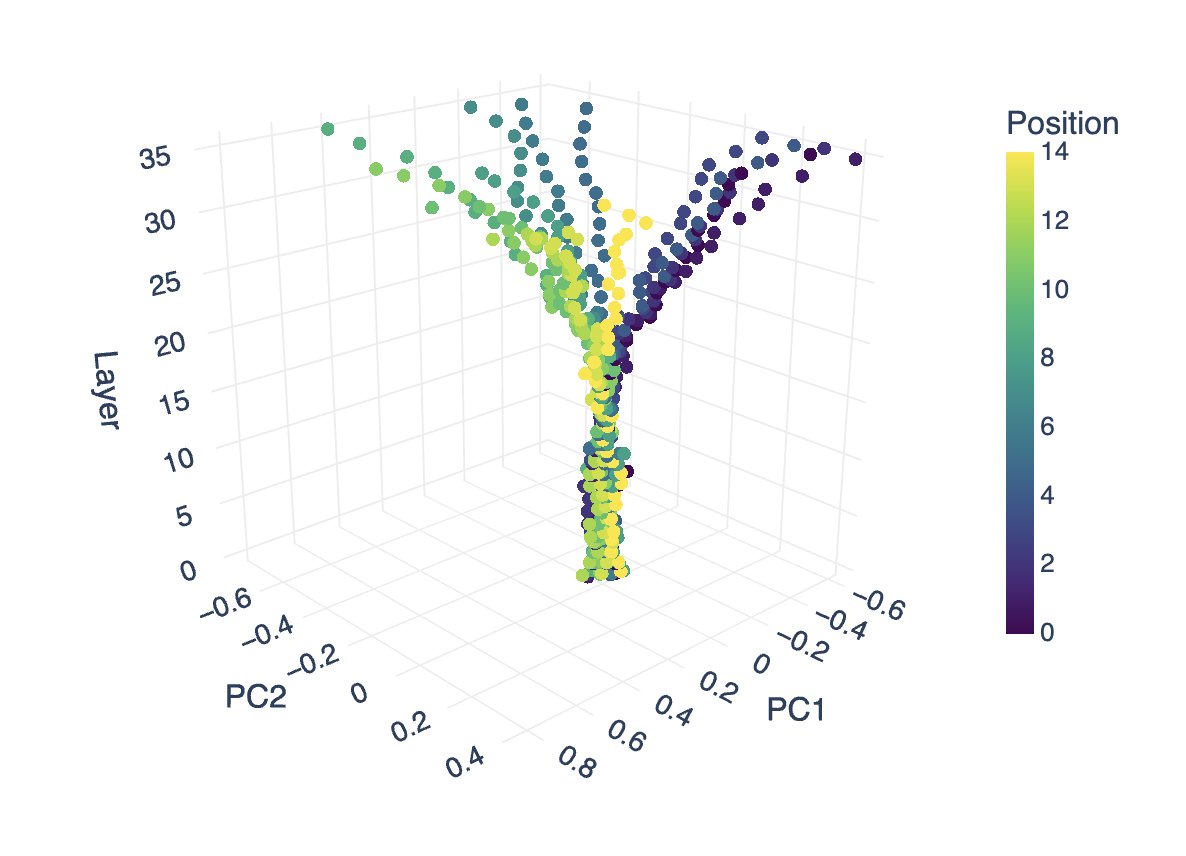
PCA fit to the final layer of residual stream in Qwen3-4b across 15 trajectories in a spatial discrimination task, then applied to each layer of the residual stream and plotted.
1
2
17
1,117
Jun 8
Me: playing peak-a-boo with some random child at the coffee shop 🙈🙉
My brain: "Ah yes, an in-vivo experiment testing object permanence in infants."
1
97
Jun 8
I wonder if qualia steered models would be any better at mechanistic introspection 🤔

Qualia steering (OLMo 32B mid-SFT checkpoint) example:
unsteered:
"I am not a conscious entity. I am a language model . . . . I don't have subjective experiences"
steered:
"I don't know what it is like to be you, and you don't know what it is like to be me. But I do know what it is like to be me"
1
10
2,053
Jun 7
Digging deeper into introspection, and there seems to be two types that I don't clearly see differentiated anywhere:
Behavioral introspection: Where a model reasons about its own behavior (predicting what it'll do, or knowing what it knows). This can largely be evaled from an API alone.
Mechanistic introspection: The model introspects on its actual activations or circuits (e.g. noticing a concept injected into its residual stream, or faithfully explaining the circuit behind an answer). Evaling this likely requires full access to model internals (e.g. for steering or verifying circuitry).
Humans are notoriously poor at mechanistic introspection (we invented neuroscience because our brains can't introspect their own circuitry), and are also not the best at behavioral introspection (e.g. intention-behavior gap, affective forecasting).
I feel confident that models will surpass us in our own ability to introspect both behaviorally and mechanistically, if they have not already. @TransluceAI's PCDs, @AnthropicAI's NLA's, and activation oracles (Karvonen et al.) hint at mechanistic introspection being possible to a superhuman-level.
3
23
1,315
Jun 7
The most correlated SAE feature with this 'all-caps' concept vector in Qwen3-4b (not 14b) at layer 18 was a feature with description: "Internet snippets/excerpts" which I thought was weird. So, if you look at the top activating example of this feature, you can clearly see that the description is quite poor and it's actually more of a 'capitalized text' feature.

6
708
Jun 4
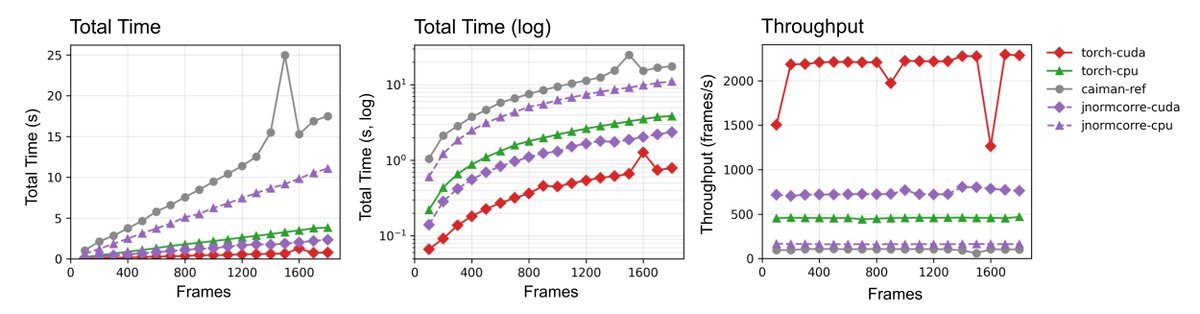
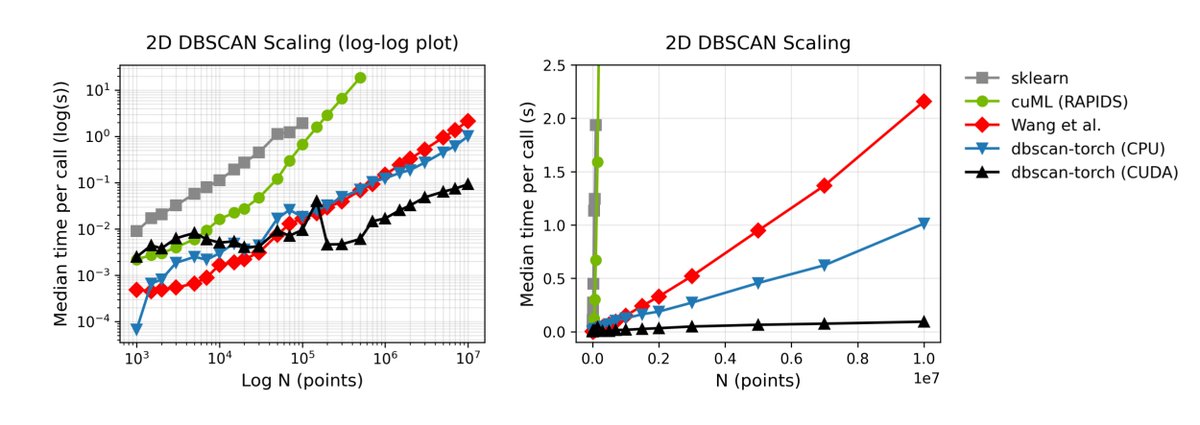
Neuroscientists doing rigid or piecewise-rigid motion correction on calcium imaging data, check out pycorre.
It's an independent reimplementation of NoRMCorre in PyTorch: GPU-accelerated, optional numpy-in/numpy-out, and faster than existing tools.
The figure attached shows scaling curves on a 360×640 calcium imaging video, benchmarked against jnormcorre (NoRMCorre in JAX) and the CaImAn reference:
- On GPU, pycorre runs 3.0× faster than jnormcorre (GPU) and 22.2× faster than CaImAn (CPU-only).
- On CPU, pycorre runs 2.9× faster than jnormcorre (CPU) and 4.6× faster than CaImAn.
Install: `pip install pycorre`
Github: github.com/ryanirl/pycorre
1
230
Jun 2
One of the features that fires when you ask Qwen who they are.
5
10
117
16,034
Jun 1
This reminds me of a study I did on toy models a while back, where I trained very small 2-layer decoder-only transformers to perform primitive operations on a list of characters (reverse, stride, take the first N items, etc...).
You could show quantitatively that models with few heads would selectively learn some tasks over others, depending on: how easy the task was, how many of the model's resources (heads for example) it tied up / demanded, its frequency relative to the other tasks in the training set (similar to your findings), and whether the learned circuits for one task generalized to others (e.g., learning one task might give you generalization power to other tasks).
As you would expect: scaling up model size and head count resulted in the rarer, and more complex, tasks get learned. Interestingly, I remember the loss being surprisingly binary: the model either learned a task or it didn't.
Using interp to reverse-engineer how each task was learned, you could then predict, given N new tasks to fine-tune on, which ones the model would choose to learn and which it would skip.
Super cool research! 😁

We expect only the larger models to learn the most infrequent tasks. This is exactly what we find. Here are the modular arithmetic task results:
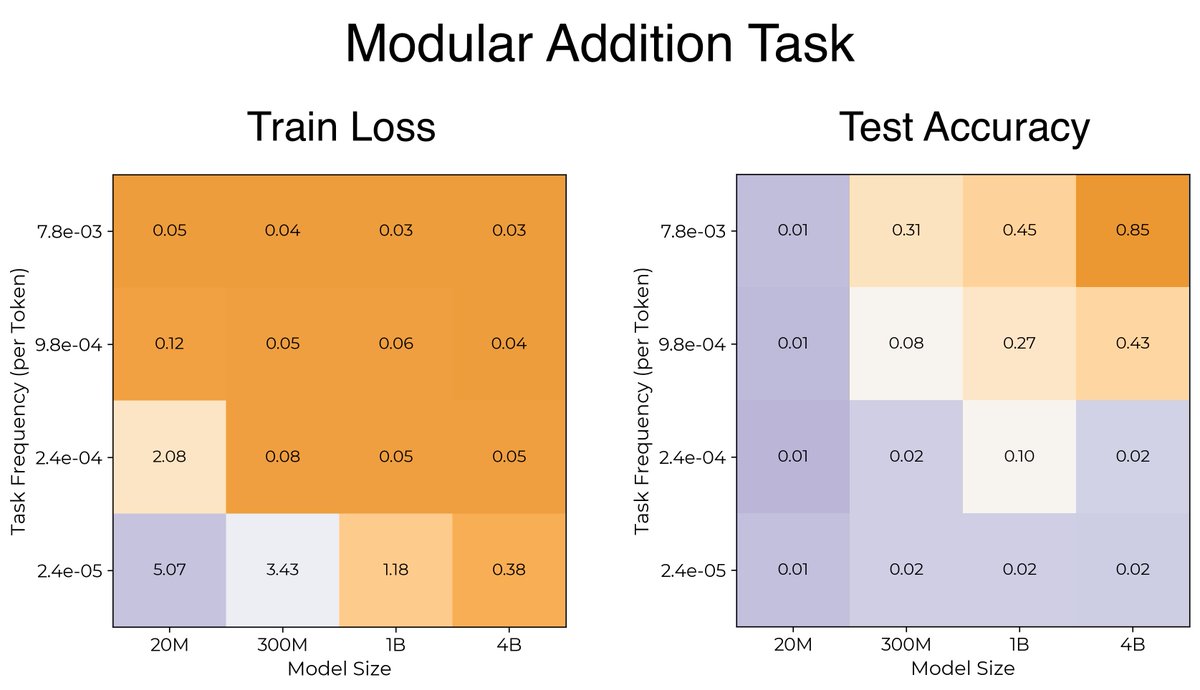
ALT Two heatmaps titled "Modular Addition Task." Both have x-axis model size (20M, 300M, 1B, 4B) and y-axis task frequency per token (rows 7.8e-3, 9.8e-4, 2.4e-4, 2.4e-5, frequent at top to rare at bottom). Left, "Train Loss": orange means low loss. Most cells are low; the bottom rare-frequency row stays high for small models (20M: 5.07, 300M: 3.43, 1B: 1.18) and drops for 4B (0.38). Larger models drive training loss down even on rare tasks. Right, "Test Accuracy": orange means high accuracy. Accuracy rises toward the top-right; the most frequent task at 4B reaches 0.85, at 1B 0.45. Rare tasks and small models stay near 0.01-0.02. Larger models and more frequent tasks generalize better.
1
30
8,409
May 29
Super cool research! I am glad to see SAE's being used and the models fully open-sourced.
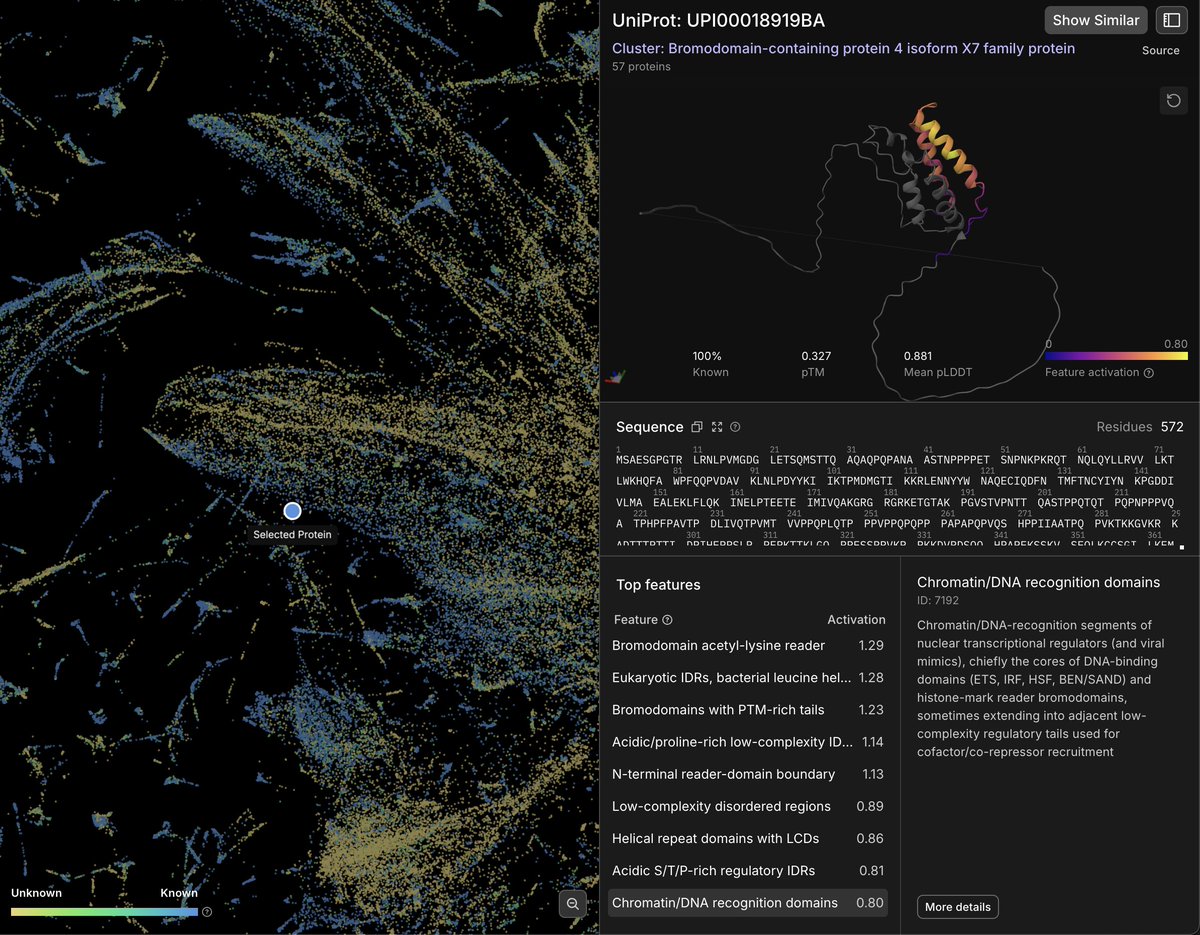
Playing around with the atlas, and here is BRD4 (Bromodomain-containing protein 4). Top active SAE features include the bromodomain acetyl-lysine reader and chromatin/DNA recognition, both good positive controls given BRD4's defining domain and its role binding acetylated chromatin. Other top features are mostly related to its 'disordered', 'acidic', 'phospho-rich' regions.
Also some apparent polysemanticity: one of the active features is labeled for both eukaryotic intrinsically disordered regions (IDRs) and bacterial leucine helices.
May 27

Today we're announcing ESMFold2, an open scientific engine to power prediction, design, and discovery across protein biology.
The new model delivers state of the art performance on protein interactions, especially antibodies, a critical modality for therapeutics.
We have designed and validated miniprotein binders and single chain antibodies across five therapeutic targets that are important in cancer and immunology. We are seeing very high success rates, and affinities at levels consistent with therapeutic activity.
We’re also releasing an atlas of 6.8 billion proteins, and 1.1 billion predicted structures.
ESMFold2 is built on a state of the art language model that has been trained on billions of protein sequences.
A world model of protein biology emerges through language modeling.
We’ve used the techniques of mechanistic interpretability developed to understand large language models to understand the concepts ESM uses to represent proteins.
The model’s representation space has a compositional organization of features across scales, levels of complexity, and abstraction, that reflects and mirrors the understanding of protein biology developed through a century of empirical science.
This understanding emerges without prior knowledge, just from language modeling of protein sequences.
Language models are becoming a powerful substrate to understand and program biology.
The design of protein interactions is one of the most fundamental problems in biophysics, and has critical implications for the discovery of new medicines. A simple gradient based search with the model was able to discover high-affinity protein binders.
I'm excited by the potential this has to accelerate basic science and the understanding of proteins. And especially for the new avenues it opens up for therapeutic design and medicine.
2
358
May 29
The manifold arc begins
Manifold cross-layer transcoder in which features are various manifolds and circuit operations combine or operate on manifolds. Who's building this
4
338