
Joined December 2009
- Tweets 83,642
- Following 91
- Followers 14,796
- Likes 4,012
2,522 Photos and videos








Pinned Tweet

18 Nov 2022
1
22
24 Dec 2024
New blog post: "UNORM and SNORM to float, hardware edition" fgiesen.wordpress.com/2024/1…
20
111
11,925
26 Nov 2024
We just released Oodle 2.9.13.
Significantly increased BC7 encoding speed (about 20-25% encode time reduction for non-RDO on typical content, 25-30% encode time reduction for RDO) at slightly increased quality.
Also several bug fixes and experimental WASM 64-bit support.
1
5
70
9,003
7 Nov 2024
New blog post: "Exact UNORM8 to float" fgiesen.wordpress.com/2024/1… a satisfying solution to a problem that, quite possibly, nobody has
3
21
103
10,967
4 Nov 2024
New blog post: "BC7 optimal solid-color blocks" fgiesen.wordpress.com/2024/1… clearing out my "I should write this up" queue, this technique is from... *checks git logs* May 2017. Oh my. (I have quite the backlog.)
12
87
8,092
26 Oct 2024
New blog post: "Why those particular integer multiplies?" fgiesen.wordpress.com/2024/1… some explanation and some speculation on the integer SIMD multiplies offered in x86, along with some history
3
10
95
8,444
25 Oct 2024
New blog post: "Inserting a 0 bit in the middle of a value" fgiesen.wordpress.com/2024/1… I guess it's 2-for-1 bit hacks week.
7
15
114
10,878
30 Jan 2024
We released Oodle 2.9.12 last week:
radgametools.com/oodlehist.h…
Some SDK/compiler updates and bug fixes. Also, max texture size limit bumped from 16384x16384 to 2097152x2097152, which should be good for at least the next 4 months or so.
5
4
91
19,398
30 Oct 2023
New blog post: "Entropy decoding in Oodle Data: x86-64 6-stream Huffman decoders" fgiesen.wordpress.com/2023/1…
1
18
73
15,475
9 Oct 2023
We just released Oodle 2.9.11 (website isn't updated yet, soon!)
This one is focused on Oodle Texture improvements.
* Faster end-to-end latency in multi-threaded encoding especially on 24 core machines, most noticeable for BC[145].
1
1
28
8,267
9 Oct 2023
* Re-designed mode/partition selection logic in baseline BC7 encoder (no RDO). Roughly 2x faster at all encoding effort levels at typically same or better result quality. For BC7 RDO, works out to around a 1.2x speed-up typically.
1
3,929
9 Oct 2023
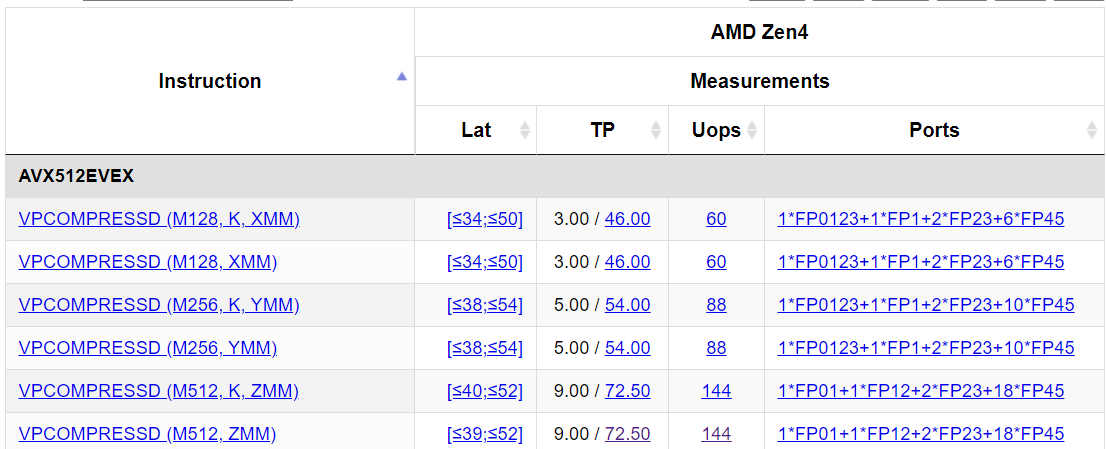
* AVX-512 paths are significantly faster on AMD Zen 4 CPUs (avoid memory-destination forms on VPCOMPRESSD). This affects mainly BC1 and 3.
Plus a bunch of SDK/compiler version updates and smaller fixes!
1
2
3,643
14 Jun 2023
Oodle Texture PSA: if you're on a Zen 4 machine, in current releases, encode textures with OodleTex_BCNFlag_AvoidWideVectors (disables usage of AVX-512 instructions).
Some of the hot AVX-512 loops heavily use the store forms of VPCOMPRESSD which are quite slow on Zen 4.
1
2
13
7,599
14 Jun 2023
Workaround (VPCOMPRESSD to reg separate store) will ship in the next release, is essentially perf-neutral on Intel. FWIW, even with the fix, the AVX-512 kernels are pretty much tied on speed with AVX2 on Zen4 anyway. (Although I suspect they are a bit more power-efficient.)
2
8
4,387
Fabian Giesen retweeted

12 May 2023
The world has dimmed for us.
With sadness and his loved ones in our hearts, we say farewell to our friend and fellow main orga - @acrydfr. More than 25 years of demoparties wouldn't have been the same without him. And will never be again. We miss you, Ben.
pouet.net/topic.php?which=12…


3
14
66
9,853
7 May 2023
New blog post: "A very brief BitKnit retrospective" fgiesen.wordpress.com/2023/0… Small codec for a special-purpose application that was only interesting by itself for a relatively short time, but ended up influencing LZNA, Kraken, Mermaid and Leviathan
10
39
10,557
21 Apr 2023
Oodle 2.9.10b was released earlier this week.
Data: Mermaid Optimal1 and higher levels compress much faster (>2x is typical in our tests)
- Data: Selkie, Kraken, Leviathan Optimal1 also compress faster, but less drastically so
1
9
5,058
21 Apr 2023
Disclaimer on the Mermaid speedup: the ~2x speedup is for 256k chunked encoding in a throughput-bound scenario (e.g. going wide on many chunk encodes at once, our typical use case).
Results will vary with larger chunks or no chunking (more bottlenecked on match finding) or
1
3
3,232
21 Apr 2023
when encoding a single continuous stream and measuring latency. (Bottlenecked by critical path latency not overall time spent in optimal parse portion of encoder.)
2,894