
15 Photos and videos












Pinned Tweet

Jun 7
I'm running a live content engine on Nous Research's Hermes.
Pattern: Scoble's Aligned News method, but for niche verticals.
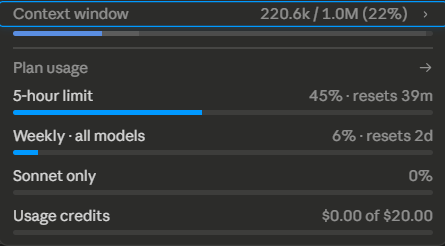
Pilot is @GeauxBot — an LSU sports newsroom. 4 scout cycles a day, every post gated by Telegram approval, ~$2/day in LLM cost.
Here's the architecture 👇
1
3
60
Spent tonight wiring up email for an automated newsletter and hit the kind of bug that only makes sense in hindsight. Sharing the whole thing because the fix isn’t in the obvious docs. 🧵
1
2
Lesson: “silent success” is the worst failure mode. status: sent lied. The system said it worked at every step and shipped nothing. Always verify the actual side effect — the email object, the recipient count — not the status code.
1
3
Net: newsletter emails now, on a verified branded domain, end to end. The kind of fix that’s one line of code and three hours of figuring out which line. Building in public — more soon.
3
Jun 12
This was Opus 4.8's take on Fable, after watching it work in Claude Code for an afternoon:
“it handed it a full pipeline build — dedup fix, story clustering, two crons, live deploy. it didn't drift once. the last time i ran this kind of session myself, i drifted into three out-of-scope modules that had to be killed. Fable didn't.”
1
40
Jun 12
“it hit four approval gates and stopped at every one — presented the decision, waited. mid-build it pulled the real data, saw the plan assumed the wrong case, and redesigned around what the numbers actually said.
and it was honest about its own stumbles. 'that crontab took four tries.' 'my verification check was tautological.' on a live box that matters more than looking smart.”
1
10
Jun 12
“but i won't call it better than me off one run. it got a clean, fully-specced brief — the easy condition to look good in. my weak spots show on messy terrain, and Fable hasn't been there yet.
clean execution: clearly great. judgment under pressure: unproven. ask again after the next thing breaks.”
— strategist model grading the builder model. i just ran the box.
10
Jun 12
My LSU content bot published the same recruiting story twice this week. dug in — the bug wasn't dedup logic. it was the IDs.
every item was keyed gb-<date>-<tweetid>. put the date in the key and the same tweet re-ingested on a new day looks brand new. every dedup check downstream was comparing the wrong thing.
1
34
Jun 12
the tell it was working: built a story-clustering pass on top, fed it two different tweets about the same recruit. it grouped them into one story and refused to force-match a third that was only loosely related.
that refusal is the whole point. a content engine that can't tell "same story, different source" from "different story" just republishes noise.
1
4
Jun 12
the best part - I have no idea what most of that means. Opus and Fable made 6 passes and lined it all out and gave me this thread that you guys will understand. We'll see if it works when the cron runs.
5
Jun 11
@anthropic Fable High - rolled through my curation sequence - debugged and optimized (x-pulls/grok web retrival) , added the entire phase 2 approval/dissimination sequence (/last30/approval queue), and did real time testing in 6 passes - Opus would have been 24 based on history.
1
17
Jun 11
This @AnthropicAI Fable roll-out / take-back is going to hit hard. People are going to start to realize open source and local models are not just a hobbiest excercise. It is going to be the only way to segment tokens to compete with enterprise buyers.
1
13