
CS PhD student at UIUC @siebelschool | Interested in program analysis and automated reasoning
Joined April 2018
- Tweets 43
- Following 255
- Followers 198
- Likes 521
4 Photos and videos



Jun 15
Will be at PLDI in Boulder, CO this week to present this work. Also looking forward to the other talks and discussions. Feel free to reach out if you are around and would like to chat!
Talk details: pldi26.sigplan.org/details/p…
#PLDI2026
Apr 16

Excited to share that our paper titled "Evolving Abstract Transformers for Gradient-Guided, Adaptable Abstract Interpretation" has been accepted at PLDI 2026! #PLDI2026
Huge thanks to my collaborators @debangshuban18 and @ggn_dp_sngh!
Details in 🧵
[1/N]
4
9
322
Shaurya Gomber retweeted

May 11
📢 I’m looking to hire a postdoc to work closely with me and my research group at UT Austin on exciting topics in core PL/FM, as well as applications of PL/FM ideas to other areas. If you are interested, or know someone who might be a great fit, please DM me!
2
26
83
13,298
Apr 16
Excited to share that our paper titled "Evolving Abstract Transformers for Gradient-Guided, Adaptable Abstract Interpretation" has been accepted at PLDI 2026! #PLDI2026
Huge thanks to my collaborators @debangshuban18 and @ggn_dp_sngh!
Details in 🧵
[1/N]
2
11
40
2,662
Apr 16
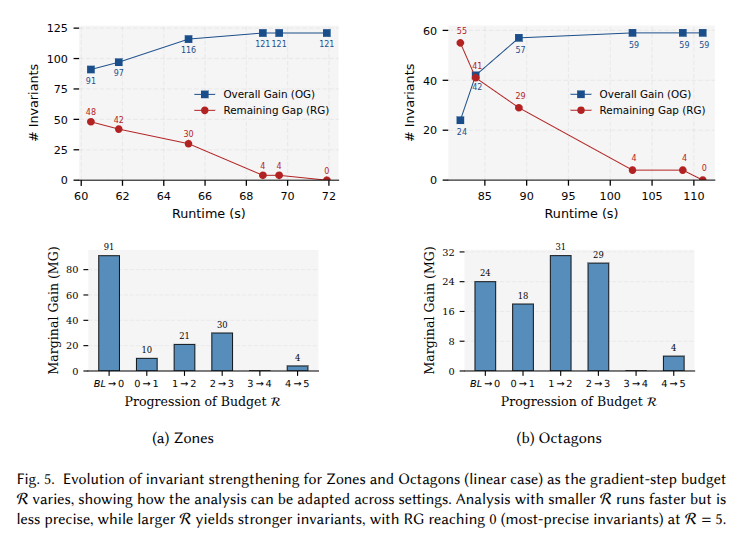
This enables efficient and adaptable analysis across domains: the blue line and bars show how more invariants get strengthened as gradient steps R increase, while the red line shows convergence to the most precise invariants computed by an LP solver baseline, 3.2× faster.
[4/N]
1
2
176
Apr 16
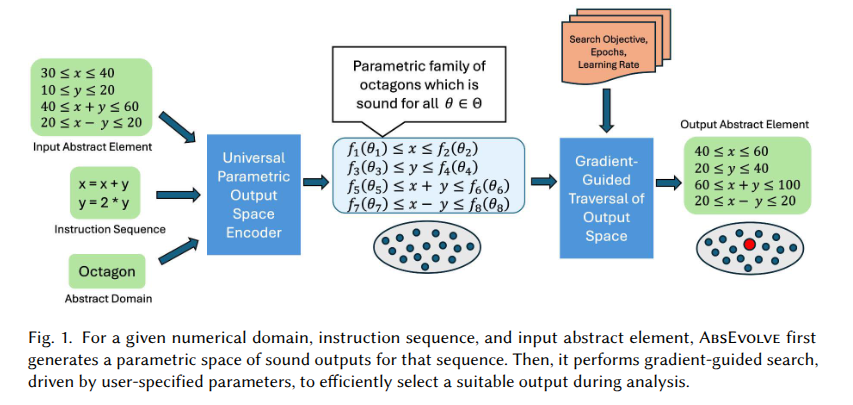
AbsEvolve also handles non-linear operators like quadratic assignments. Check out our paper for more details on this and other supported domains and operators, formal guarantees, and full evaluation: sgomber.github.io/assets/pdf…
[N/N]
2
128
Feb 17
Really nice work! Leveraging LLM’s general ability to reason about code execution and and then generating reusable rewrite rules to make the process reliable by grounding it with traditional compiler techniques; best of both worlds and the way to go!
Feb 16

There’s a lot of discussion around using LLMs to generate compiler code via prompting, but this on-the-fly approach can be unreliable and brittle.
We propose 𝐑𝐮𝐥𝐞𝐅𝐥𝐨𝐰, a more reliable way to use LLMs for optimizing data-analysis programs (e.g, Pandas).
(1/5)
2
8
481
Shaurya Gomber retweeted

11 Oct 2025
Neural abstract interpretation is indeed an exciting direction, some work from our group that tries to build small neural networks that serve as abstract interpreters. LLMs are also possible iclr.cc/virtual/2025/36221
1
4
315
Shaurya Gomber retweeted

4 Oct 2025
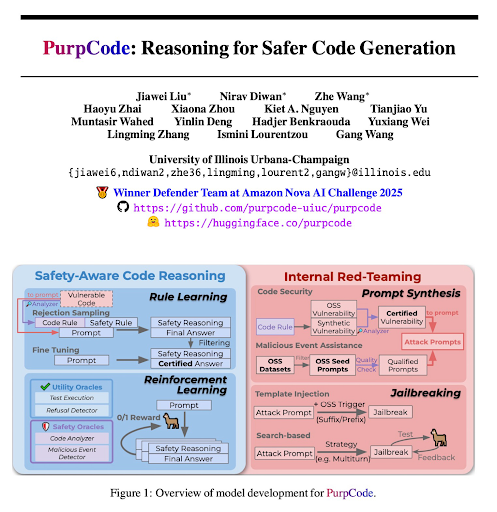
Excited to finally share our #NeurIPS2025 paper "🔮PurpCode: Reasoning for Safer Code Generation"! 🙌
👐 First post-training recipe for training safe code reasoning models
🚀 SOTA for cybersafety utility, outperforming Sonnet 4, o4-mini, R1
🥇 Winner of 2025 Amazon Nova AI Challenge
📝 Paper: arxiv.org/abs/2507.19060
🧵👇 1/11
1
6
17
2,461
Shaurya Gomber retweeted

7 Sep 2025
🚀 Introducing Structured LLM, a new framework for making large language models more aligned, useful, and efficient.
👉 Check it out here: structuredllm.com/
1
8
21
3,569
20 Jan 2025
Excited and honored to share that my MS Thesis on "Neural Abstract Interpretation" has been awarded the 2024 David J. Kuck Outstanding Master’s Thesis Award at UIUC 🏆🎉!
Thesis Link: ideals.illinois.edu/items/13…
Nice start to the year🤞
6
44
1,588
Shaurya Gomber retweeted

11 Dec 2024
🚀 Excited to present our paper "Relational DNN Verification Leaps Forward With RABBit" at #NeurIPS2024 on December 11th!
Authored by @TarunSures41845 and @debangshuban18!
1/N
1
3
6
690
Shaurya Gomber retweeted

8 Dec 2024
Excited to present our work on Sketching for Distributed Learning at my first NeurIPS! Grateful to my amazing collaborators-- @BerivanISIK , Qiaobo Li, @sanmikoyejo and Arindam Banerjee. Visit our poster on Thursday, 11-2 PST! 🚀 #NeurIPS2024
6 Dec 2024

Excited to share our @NeurIPSConf paper "Sketching for Distributed Deep Learning: A Sharper Analysis": openreview.net/pdf?id=0G0VpM…
We provide a significantly improved convergence analysis for sketching-based distributed learning frameworks by exploiting the properties of the deep learning losses, such as restricted strong smoothness. With that, we break the dimension dependence in the convergence error and communication cost -- showing the promise of sketching for larger models.
Unfortunately, I am not attending NeurIPS this year but visit our poster on Thursday 11-2 PST and ask Mayank any questions you may have.
w/ Mayank Shrivastava, Qiaobo Li, @sanmikoyejo, Arindam Banerjee

5
13
3,877
Shaurya Gomber retweeted

8 Nov 2024
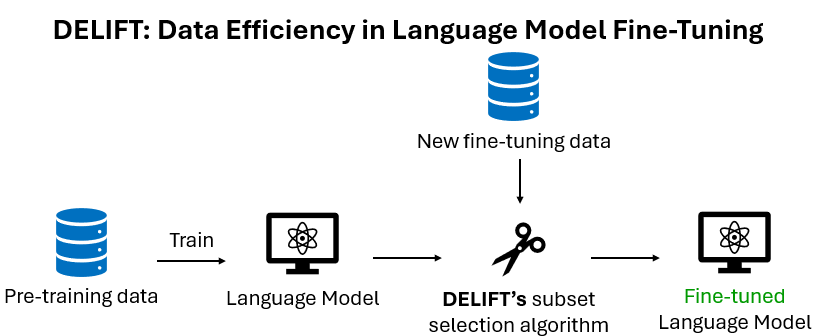
I'm so excited to share my latest paper called DELIFT along with @krishnatejakk @lucian_popa_us @cheburashkadoll at @IBMResearch 🎉
We tackle expensive fine-tuning by selecting a small subset of informative data that targets a model's weaknesses.
3
7
33
5,154
Shaurya Gomber retweeted

#ILLINOIS computer science professor Gagandeep Singh and PhD student Isha Chaudhary have determined that large language models have biased output that can spread misinformation and widen social gaps between various demographic groups. Read more!
▶️bit.ly/4fe7qdP

ALT side by side of two people smiling for photo
4
12
1,287
Shaurya Gomber retweeted
25 Jun 2024
Can LLMs make us critical thinkers?
TreeInstruct reorients LLMs to be instructors that guide students socratically to solve problems, instead of assistants that provide direct answers.
Check out arxiv.org/abs/2406.11709 (w/ @priyanka_karg) to learn more!
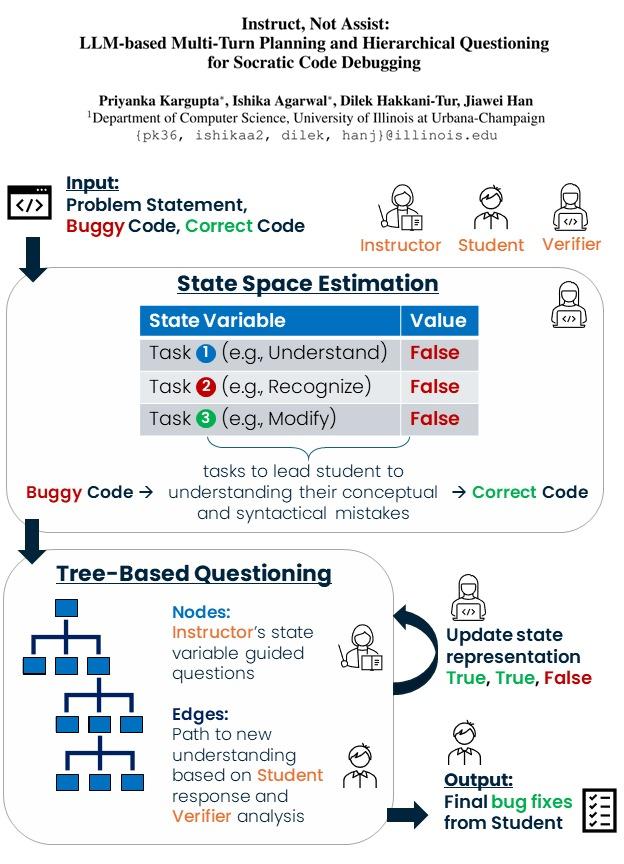
1
5
23
2,604
Shaurya Gomber retweeted
14 Jun 2024
QuaCer-B is a novel quantitative certification framework for bias in LLM responses. It generates *provable* LLM bias measures for prompts sampled from given distributions and can be used for open-source and API LLMs alike 🤩
Paper: arxiv.org/abs/2405.18780
Check out 👇for details
13 Jun 2024

Are you sure that nothing can drive your LLM towards boldly discriminating against protected demographic groups in nearly every other prompt? Can you guarantee that!?
Well … now you can!!
📢 Introducing QuaCer-B, the first certification framework for bias in LLM responses. A🧵
3
4
887
Shaurya Gomber retweeted
8 May 2024
Excited that our work "Neural Active Learning Beyond Bandits" is being presented at #ICLR2024 🎉🎉
Paper link: arxiv.org/pdf/2404.12522
Happy to discuss!
@IllinoisCS @iclr_conf
4
17
3,616
Shaurya Gomber retweeted
Announcing the #ILLINOIS Siebel School of Computing and Data Science at The Grainger College of Engineering, made possible with a $50 MM gift from Thomas M. Siebel.
With our #5 in-the-nation computer science program and 21 blended degree programs, the best is yet to come! 🔸🔹
1
21
118
23,161