
1,504 Photos and videos











Pinned Tweet

27 Sep 2025
वनमाली गदी शार्ङ्गी शङ्खी चक्री च नन्दकी श्रीमान् नारायणो विष्णुर्वासुदेवोऽभिरक्षतु।
3
1
13
9,019
Jun 14
Partially agree, but this is a loaded blog trying to say that you need all the bells and whistles from microsoft for the frontier to really kick ass. Partially correct

46
Jun 14
Elon is the real Tony stark. The one line which I took away from his talk track was “Lets take fiction out of Science Fiction”. Kudos Elon !
37
Jun 12
I have realized generally in shark tank India all judges are idiots but one who caught my attention was @1kunalbahl, he is calm, very respectful and his questions and analysis is spot on. Very graceful ! So much respect for you Kunal.
1
2
76
Jun 10
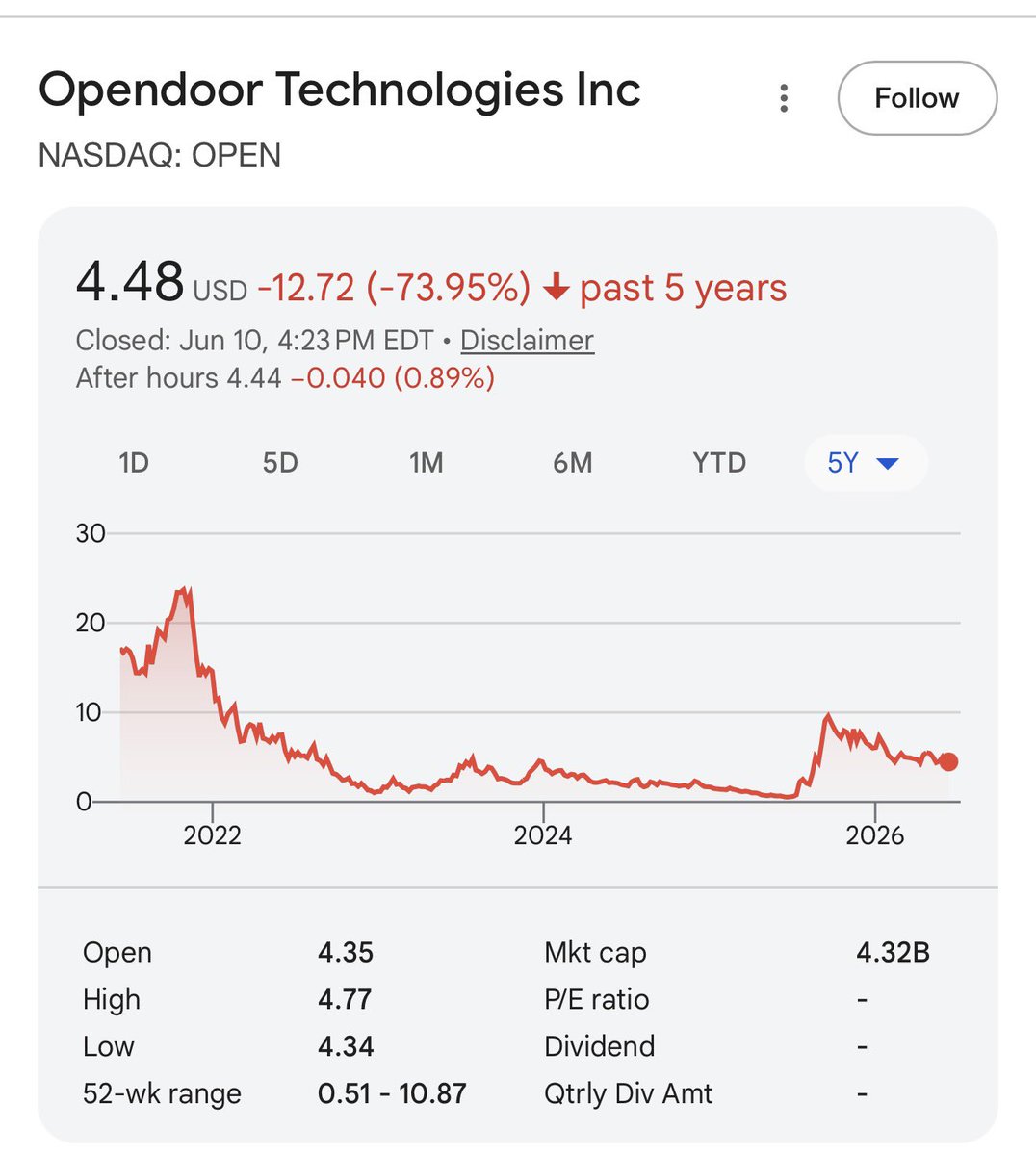
Complete market manipulation seems to be going on, all kind of outlandish predictions, $28 trillion made up market cap, for a stock that will will be twice as valuable as Walmart while generating less revenue than Macy's. I am big fan and operate in that industry too, but its just crazy how every second post on the time line is about the IPO.
1
97
Jun 3
Interesting, journalists turn off comments. This is new type of journalism where take some random deported ass and interview them and then turn kf the comments.
Jun 2

"Wake up Call for Both BJP & Opposition- all mainstream parties- BJP is in government so our questions are directed at them"- @abhijeet_dipke -Founder of Cockroach Janata Party on heading home to India & past links with AAP, charges of bot farms & more. In full youtube.com/watch?v=cD4I-Ftc…
1
108
May 29
This whole CBSE OSM issue seems to be an inside hit job. It should be properly investigated. After NEET this doesnt seem to be just an accident but reeks of a systematic sabotage aimed at instigating the youth between 15 to 21 of age. @PMOIndia must get involved and do a deep rapid assessment.
Selection of a dubious edtech company, creation of a minified SPA with embedded master password at the client side, so called hacking, continued disastrous public takes by CBSE representatives, flawed algorithmic mixup in osm scanned sheets and now accelerated media narrative. Now coupled with another spicy buildup of IAF delivery of NEET papers. All of it is designed well to discredit govt. and create a distrust in the system.
1
200
May 29
Apprehend these non ethical miscreants. This is not defensive pentest, its criminal.
May 29

CBSE got HACKED… AGAIN 🔥
They swore they weren’t hacked.
This time? Full OS-level access. We own the dashboard.
They keep denying. We keep delivering proof.
@ni5arga 🤝
cbseosm.onmark.co.in/cbse_da…
#CBSEHacked #Pwned #CyberSecurity


1
217
May 26
Here's the part that kept me up at night:
If three independent teams converged on the same architecture in ~6 months... what happens when the entire industry realizes it?
We're probably looking at 6-12 months until 80% of new models ship with this hybrid pattern.
The architecture war is over.
The implementation war starts now.
1
141
May 26
What I'm watching:
Who ships the best optimized kernel for chunkwise parallel training (this is the actual bottleneck)
Whether the 3:1 ratio holds at larger scales (all proofs so far are sub-10B)
If someone breaks the constraints — maybe with new hardware or a genuinely novel mechanism
If you're building in this space, watch #1 above everything else.
1
100
May 26
I've been researching AI architectures for years.
I've seen hype cycles come and go.
But this convergence is different. It's not a trend. It's a phase transition.
The people who understand that and adapt fast, win.
The ones waiting for a magical new architecture to save them lose.
Follow me for more honest takes on what's actually happening under the hood.
89
May 26
Let me show you what I mean.
Plot every serious architecture from 2024-2026 on two axes: speed (linear scaling) vs precision (retrieval accuracy).
Pure Transformers sit top-right: precise but expensive.
Pure Mamba sits bottom-left: fast but imprecise.
Every hybrid lands in the exact same sweet spot. Not close. The same spot.
It's like gravity.
1
107
May 26
What changes when architecture becomes physics?
Competition shifts FROM "who invents the next big idea" TO "who implements the known optimum fastest."
This is great news for everyone shipping products. Bad news for anyone betting on a secret sauce.
The moat is no longer architecture. It's data, engineering, and distribution.
1
77
May 26
The implication nobody's talking about:
We're entering the "physics era" of AI architecture.
In the early days, anything went. Throw parameters at it, try a new trick, see what sticks. That's chemistry, mix things and observe.
Physics is when you realize there are fundamental laws.
You don't discover new physics by trying harder. You discover it by understanding constraints.
1
64
May 26
I think I know why.
There's only one answer to a specific set of constraints:
Inference must be cheap at long context (kills pure Transformer)
Retrieval must be precise enough for reasoning (kills pure Mamba)
Training must run on existing GPUs (kills exotic architectures)
When you stack those constraints, the solution space collapses to one point.
1
1
66
May 26
Here's what happened in 2026:
NVIDIA released Nemotron 3 Nano → 88% linear layers, 12% attention.
Alibaba released Qwen 3.5 Small → 75% Gated DeltaNet, 25% attention.
Songlin Yang at MIT published Gated DeltaNet → recommended 75-80% GDN, 20-25% attention.
Different names. Different branding. Identical architecture.
1
114
May 26
This isn't normal for competitive tech.
Usually you see divergence. Apple does one thing, Samsung does another.
OpenAI goes left, Anthropic goes right. Competition breeds differentiation.
But here, three teams with zero coordination arrived at the same 3:1 ratio of linear-to-attention layers within months of each other.
That doesn't happen by accident.
1
1
63
May 26
Three AI labs told completely different stories about their new models.
NVIDIA said theirs was "the future of state-space models."
Alibaba called theirs "a breakthrough in hybrid attention."
An academic paper described "an elegant memory mechanism."
I read all three papers side by side last week.
They built the exact same thing.
A thread on why this matters (1/n)
1
1
90
May 26
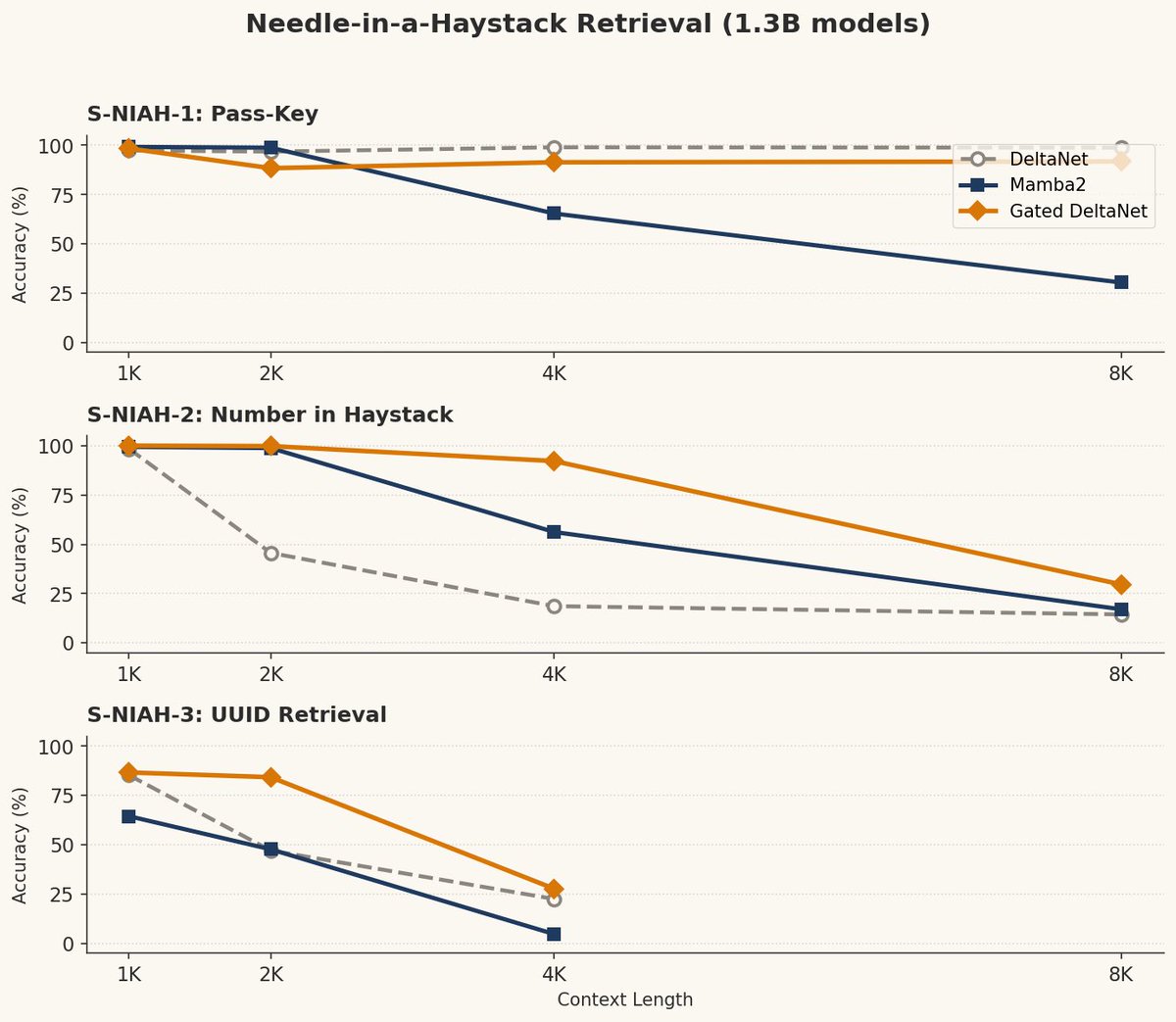
I spent this weekend reproducing Gated DeltaNet benchmarks from the ICLR 2025 paper.
The results really surprised me.
This architecture from NVIDIA/MIT probably solved the problem everyone thought required tradeoffs.
Full breakdown charts (1/n)
1
194
May 26
The broader pattern: NVIDIA's Nemotron 3 Nano uses 88% linear layers. Independent labs converged on the same mix.
We're hitting diminishing returns on scaling pure transformers. KV-cache bottlenecks, quadratic costs, context windows growing slower than ambition.
GDN isn't a benchmark record. It's production-ready infrastructure.
1
1
88
May 26
If you work in ML, bookmark this. Pay attention to which labs ship hybrid architectures next.
If you invest in AI, watch companies building on GDN-like foundations. The moat here is training efficiency at long context — and that compounds fast.
Follow me for more hands-on architecture deep dives.
1
61