
🐐
Joined November 2008
- Tweets 18,675
- Following 175
- Followers 13,302
- Likes 18,668
1,975 Photos and videos











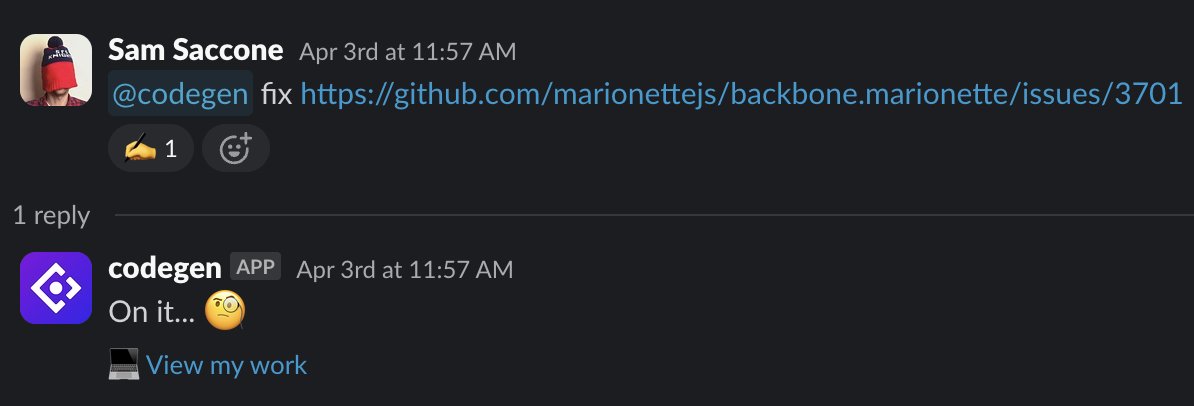

26 Mar 2016
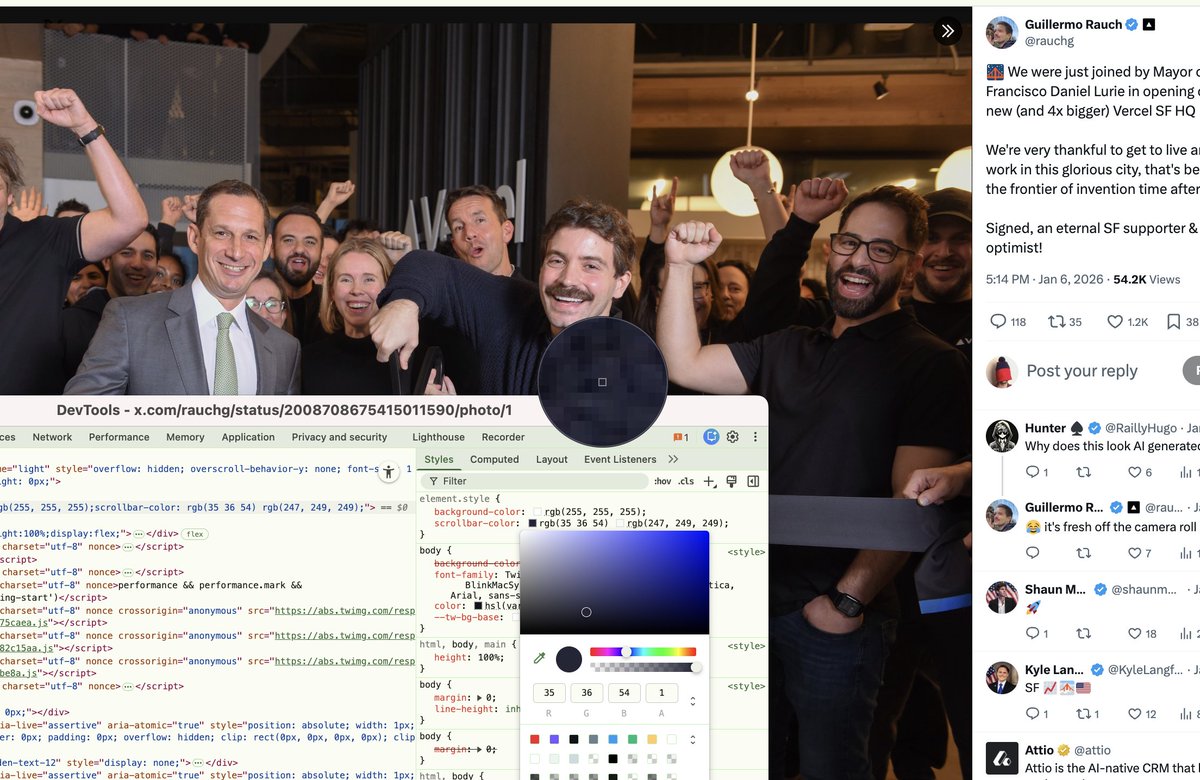
CERT just disclosed a malicious npm vector Reported in Jan 4 2016.
kb.cert.org/vuls/id/319816

10
66
76
Sam Saccone retweeted

Jun 9
It's finally happening. We can put this whole install script NPM worm madness behind us...
github.blog/changelog/2026-0…
7
39
168
59,679
May 31
The step change btw a prompt starting from a problem vs data gathering is the single largest step change you can make _today_ for your trajectory outcomes.
i.e:
> "page is slow when i ___ ... fix it"
V.
> "visit site[dot]com and collect a devtools trace..."
3
7
1,628
May 31
models have been post-trained to bend to your will - when you say something is slow - the model is going to make up 100 reasons for the slowness in thinking tokens
If you start by seeding the context window w/ perf data you anchor the interaction in data not hallucinated rational
1
1
1,284
May 31
the added benefit of investigation first is you get verification steps out of the gate vs post-fact - the combination of anchoring your interaction with data gathering and verification baked in allows extended task horizons with significant outcomes.
2
814
Sam Saccone retweeted

May 20
diffshub[dot]com
Take any public diff from GitHub and virtualize it nearly instantly, no matter how large, with DiffsHub. Built to show off our brand new CodeView component.
To try it out, replace `github` with `diffshub` in your address bar.
116
231
2,976
1,066,714
May 15
🔨agent experience is the new developer experience
🗺️agent trajectories are the new friction logs
🧨The path to 10xing does not come from increasing token burn ... Efficacy of task and laser focus on understanding what is going wrong is the bottleneck - NOT YOUR MODEL.
1
435
Sam Saccone retweeted
7 Nov 2025
Everyone is waking up to the fact that code-review is the bottleneck of 2026
I'm bullish on ramping review agents - but the vibes coming from
- 0github.com
- asi.review
- pierre.co
start to hit closer to home on where we need to go
1
5
24
5,784
Apr 28
Openclaw to GitHub this month.
Apr 27

A runaway sea lion is squatting in San Francisco and locals can’t get enough of the 2,000-pound beast they call Chonkers. on.wsj.com/4udqu2A
1
1,038
Sam Saccone retweeted

Apr 25
“AI will replace you”
Me who already replaced myself with Claude:
106
2,419
26,950
812,355

Sam Saccone retweeted

Apr 21
This is cool: maggieappleton.com/zero-alig…
Apr 21

The next Slack won't look like Slack
14
29
507
148,367
Sam Saccone retweeted

Apr 6
Yes, you can technically run an LLM on a 1998 iMac G3 with 32 MB of RAM.
Prompt: "The green goblin"
Output: "The green goblin had a big mop. She had a cow in the field too. I"
Hardware:
• Stock iMac G3 Rev B (October 1998). 233 MHz PowerPC 750, 32 MB RAM, Mac OS 8.5. No upgrades.
• Model: @karpathy's 260K TinyStories (Llama 2 architecture). ~1 MB checkpoint.
Toolchain:
• Cross-compiled from a Mac mini using Retro68 (GCC for classic Mac OS → PEF binaries)
• Endian-swapped model tokenizer from little-endian to big-endian for PowerPC
• Files transferred via FTP to the iMac over Ethernet
Challenges:
• Mac OS 8.5 gives apps a tiny memory partition by default. Had to use MaxApplZone() NewPtr() from the Mac Memory Manager to get enough heap
• RetroConsole crashes on this hardware, so all output writes to a text file you open in SimpleText
• The original llama2.c weight layout assumes n_kv_heads == n_heads. The 260K model uses grouped-query attention (kv_heads=4, heads=8), which shifted every pointer after wk and produced NaN. Fixed by using n_kv_heads * head_size for wk/wv sizing
• Static buffers for the KV cache and run state to avoid malloc failures on 32 MB
It reads a prompt from prompt.txt, tokenizes with BPE, runs inference, and writes the continuation to output.txt.
Fun!

10
8
151
14,306
Feb 22
#1 mistake I see people making when prompt coding is omitting verification instructions.
The delta in outcomes btw a prompt that explicitly lists a verification step and not is significant.
Often it's as simple as
"Optimize code in main . py" vs "Profile and optimize"
6
1,206
Feb 15
The cost of code nearing 0 is great and all - but i'm more excited about the burden of tech-debt dropping to zero.
3
6
1,024
Sam Saccone retweeted

Feb 4
𝕿𝖍𝖎𝖗𝖙𝖊𝖊𝖓𝖙𝖍 𝚘𝚙𝚎𝚗𝚌𝚘𝚍𝚎 PR 💀
Jan 18

This, more of this ❤️
127
39
1,532
289,669
Feb 1
If you know you KNOW


2
30
4,454
Jan 31
Openclaw is a glimpse into the future I expect to materialize within the next 3 months for everyone who today is only using the web front ends of the frontier models.
The oh s*** moment that is happening right now is a result of lowering the barrier to entry for the highly technical early adopters - demonstrating just how much is possible today if you string all of the pieces together with the existing models
8
1,894