
Type-checking the cloud @alchemy_run
Joined August 2014
- Tweets 7,616
- Following 1,209
- Followers 4,145
- Likes 10,888
816 Photos and videos







Pinned Tweet

21 Jan 2025
A post on my decade long journey with Infrastructure-as-Code, why I built my own minimal library in pure TypeScript and why I think you should at least entertain the idea of "un-bundling IaC" and returning to simplicity.
I built alchemy after years of working with every other option, from CloudFormation, CDK, to Pulumi, Terraform and Kubernetes. IaC is non-negotiable in my opinion, and is one of my favorite technologies as a developer.
I started with CloudFormation since I worked at Amazon and really hated that. JSON is just not expressive enough for me and debugging broken stacks was was always something I dreaded. I'm pretty sure the CFN website still squashes the whole error message into a 10 pixel wide box 😅.
The CDK is an upgrade on that (because yay for TypeScript) but it is still always going to be limited by the CloudFormation service, which is very slow to change and use.
Being developed by corporate giant Amazon and with the founder moved on to new ideas, you just have to accept that things will move more slowly and you have no say or control over that. It's how things are in a big centralized company.
One mega wart with the CDK technically is its awful coupling to synchronous I/O, making it damn near impossible to do anything async. Every user inevitably runs into this, googles it and is met with "fuck off" in the GitHub issues. Then we're forced to hack around it, which is not pretty. Not allowing is async is basically not allowing JavaScript. I doubt it'll ever be fixed.
They're also stuck on CJS. Taking a dependency on the CDK and using it anywhere other than locally will 10x the size of your app and destroy your DX. It's a tangled mess of of complicated, legacy TypeScript code generating complicated, proprietary JSON files uploaded to the complicated, opaque, proprietary CloudFormation service 🫠
Why? How does this serve the user?
Later, I moved on to Pulumi, which was a nice change of pace since it runs locally and is much faster. You can cancel a deployment by hitting Ctrl C (hallelujah!) and it also supports more than just AWS, which is great because everything should be managed sensibly in code.
However, Pulumi is largely a wrapper around Terraform. If you thought you were going to escape the layers, you were sorely mistaken. That JavaScript is just lipstick on the pig that are clunky "providers" implemented with Go, running in a separate process. You can't just run Pulumi everywhere (like the browser) and it even struggles to run in AWS Lambda if you're using ESM.
Pulumi Custom Resources are possible but more of an afterthought and a PITA to implement. They have many sharp edges and gotchas, like the resource code having to be serialized and their coupling to CJS - so if you import the wrong thing with ESM, it just breaks. I couldn't even use AWS SDK v3 in a simple custom resource because of how leaky these hacks are.
If Pulumi bricks itself by getting into some weird state, good luck fixing it. Their state files are complicated and their providers are opaque, so you're really just stuck running `pulumi refresh` and praying, or surgically removing and restoring resources one by one. It's not transparent.
I've used Terraform when I've been forced into it. It does exactly what it claims to do, but I don't love it because it's a custom DSL and a heavy toolchain. And for what? Calling a few CRUD APIs? Way overkill.
If it doesn't already exist in Terraform, then just forget it. Every time I think about implementing a custom resource for Terraform, I just can't bring myself to do it. Let me just write a function in my language, please!
Lately, I've been using SST because I've been doing a ton of web development. At first, I really liked SST because of its local development experience. `sst dev` gives you live deploy, a TUI multiplexer and a proxy from the cloud to your local code. This is great for building web apps in AWS.
But, SST is a wrapper around Pulumi!! (which is a wrapper around terraform (which is a wrapper around the underlying SDK ( ... ( ... ( ... )))) ...
Layers. Layers. Layers. When will it ever end?
As my app grew, SST's bugs and opinions ate away at me. I got blocked by broken resources that have race conditions and it was impossible to work around (still is, by the way). I also wanted to deploy a nested app using another `sst.config.ts` but it conflicted with their assumptions around generated sst-env.d.ts files.
Again, I was let down by the complexity and opinions(!) of my chosen IaC framework. And for what? To help me call a few CRUD APIs and track my Resources?
Honestly, it just seems insane how far we've drifted away from simplicity in this area. This became even more apparent as I started using Cursor more and more to write code.
You see, I've found myself doing more frontend than I've ever done before, and I'm not a good frontend developer. So, I relied on Cursor to write most of the code for me and (as many others have experienced) it totally blew my mind 🤯
Cursor is just really, really, really good at TypeScript, React and Tailwind. I've built a functioning and (if i don't say so myself) good looking SPA. It's been a blast. As a "backend guy", i feel my world has opened up.
But, this got me thinking ... you know what else Cursor is really great at? Perhaps even better at?
👉 Interacting with CRUD APIs.
While there's a ton of frontend training data for LLMs, there's just as much (if not more) training data for CRUD lifecycle operations. They've also ingested all of Kubernetes, Terraform, Pulumi, SST and the AWS CDK's training data. Modern LLMs know it very well.
Long story short, I discovered that Cursor can pretty much one-shot the implementation of Resources. All of the resources in Alchemy are entirely generated on-demand (5 minute time investment, tops). When I run into a bug, I just explain it to Cursor who fixes it immediately.
Working this way may seem like more work at first glance, but in practice I think it's not. I will never get blocked by working this way. I will never have to wait for another person to prioritize my problem, merge a fix and release the change. I will never be confused about what's actually happening under the covers.
This is a game changer for me. It means we don't need tools like Terraform to build layers of "provider" suites for us. We just need the engine - the bit that tracks state and decides what to create/update/delete. The rest can be generated at near zero cost.
I suspect a lot of people gripe with me on this claim of "zero cost" because they have not yet embraced the AI-generation workflow. Their instinct is right, but outdated.
Before LLMs, I would agree that this was infeasible, but I think we've finally crossed the threshold where LLMs can do this work trivially and respond in real-time to your requirements.
If this is not obvious to you, then I suggest forcing yourself to practice with AI code generation. When it fucks up, try blaming yourself instead of blaming and discarding the LLM. I think you're missing a skill.
This is why adoption curves are a thing, do you want to be a laggard?
At the end of the day, you need to realize that agency is going to matter more and more as time progresses and that shackling yourself to a mega-provider who doesn't even know your name is a ticket to inefficiency.
I think we've mostly been hoodwinked into thinking that because managing infrastructure is complicated, we need complicated solutions. Now is the time for that pendulum to swing back in the other direction and "un-bundle" IaC.
9
8
133
24,346
Jun 12
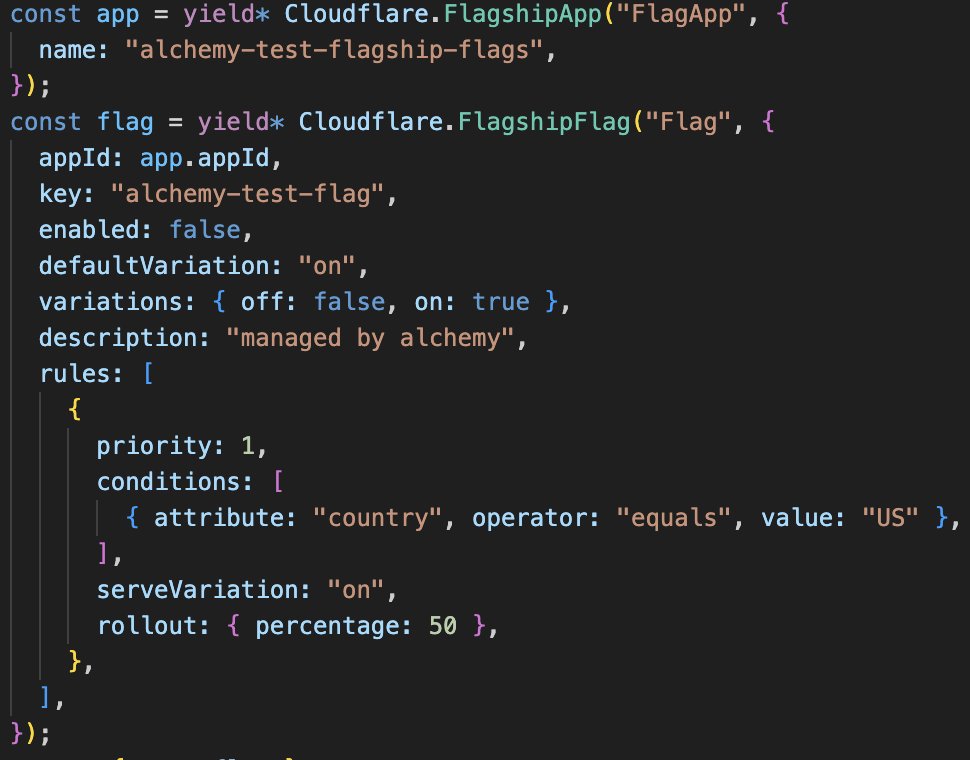
FlagshipApp and FlagshipFlag will be in the next version of Alchemy. It's becoming that quick, folks.
Jun 12

Flagship API came out today and our automated IaC->Spec factory process has already built the resources and patched their spec.
2
32
2,239
Jun 12
4
361
Jun 12
Flagship API came out today and our automated IaC->Spec factory process has already built the resources and patched their spec.
Jun 12

Flagship API reference is now available. Manage apps and feature flags entirely via the API without touching the dashboard.
developers.cloudflare.com/ch…
1
43
4,602
Jun 12
Final numbers: built 228 resources, patched 1075 APIs, tagged 2189 errors and fixed 173 schema bugs.
Hey @Cloudflare, i finally have an objective measurement of how broken your API spec is 😉
Oh and I fixed it for you. You're welcome.
Jun 12
A beautiful "software factory" with its own "software byproducts".
As Fable generates 100% Cloudflare IaC coverage, it also produces a perfectly patched API spec and Effect SDK.
All important errors and fixed data types are discovered from the API's real behavior (PR below)
5
3
88
7,826
Jun 12
A beautiful "software factory" with its own "software byproducts".
As Fable generates 100% Cloudflare IaC coverage, it also produces a perfectly patched API spec and Effect SDK.
All important errors and fixed data types are discovered from the API's real behavior (PR below)
Jun 12
100% coverage of Cloudflare Alchemy resources incoming.
Fable is great. Stays on track, does what I would do.
4
4
61
12,484
Jun 12
1
4
1,061
Jun 12
100% coverage of Cloudflare Alchemy resources incoming.
Fable is great. Stays on track, does what I would do.
5
3
84
7,462
Jun 11
This looks great.
The yield* ( <dom >) at the end is elegant. Curious to see how that works at the type level.

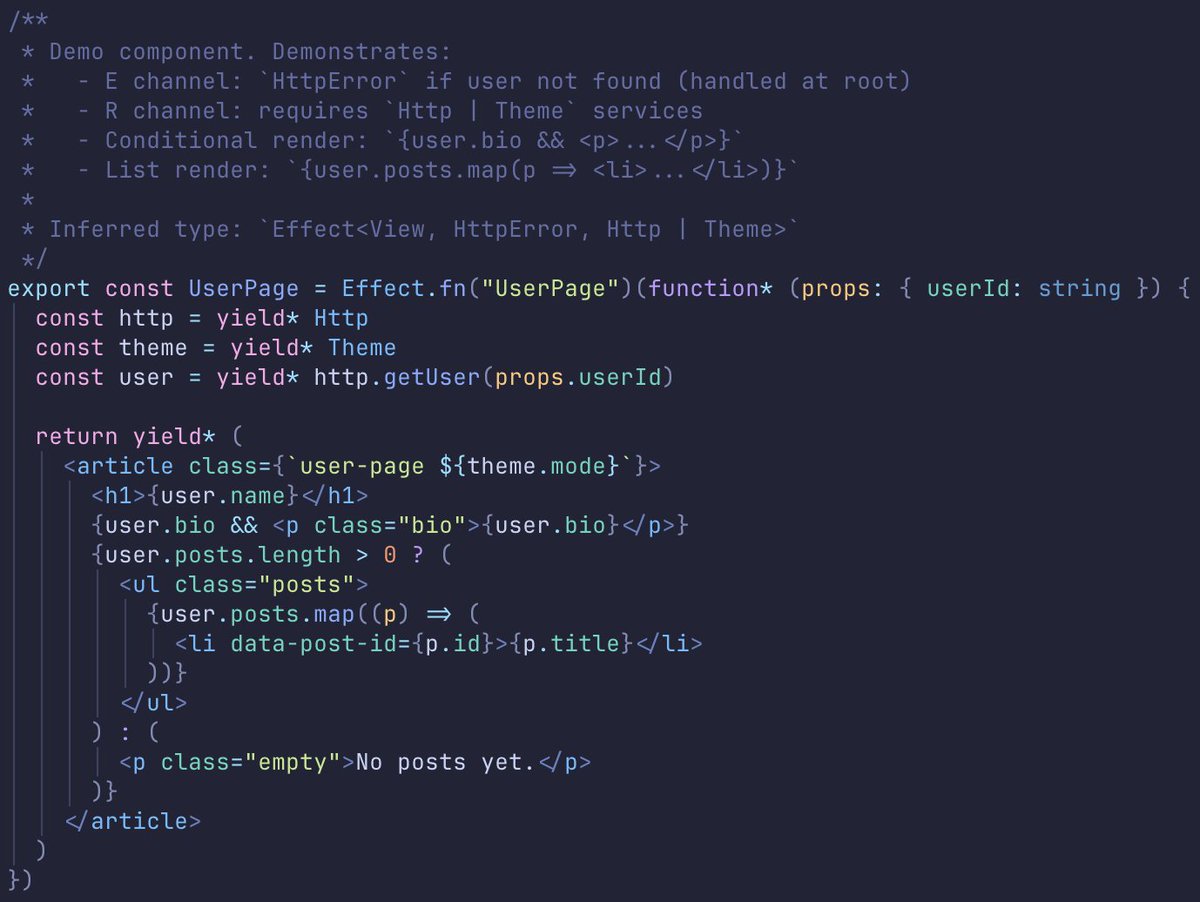
just open-sourced verrex. my take on a frontend framework built on @EffectTS_.
the view tree carries Effect's E/R channels to the root, so forgetting to provide a service Layer is a compile-time error that names the missing service.
jsx syntax fine-grained reactivity.
demo → m9tdev.github.io/verrex
source → github.com/m9tdev/verrex
1
1
57
6,118
Jun 10
Here’s a test for Fable: build Effect into the Bun runtime.
I want:
1. Stack traces to not be broken
2. *() => syntax
3. |> pipe operator
4. Native performance
Jun 10

fable is very good at large projects
13
2
146
25,706
Jun 10
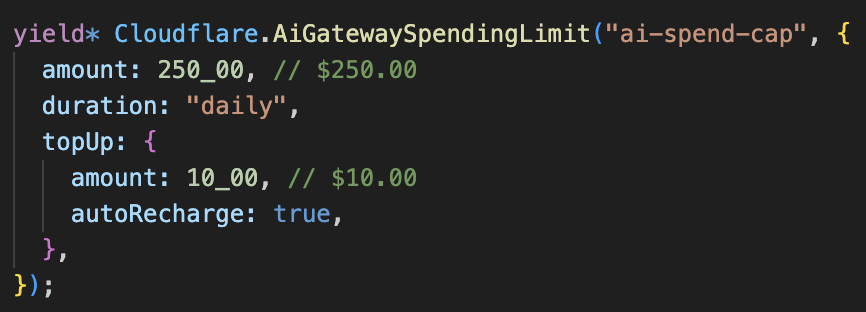
Neat community contribution: configure your spending limit and auto top-ups for Cloudflare AI Gateway with Alchemy.
2
3
60
2,521
Jun 10
2
753
Jun 5
Feels good. Is good.
Jun 5

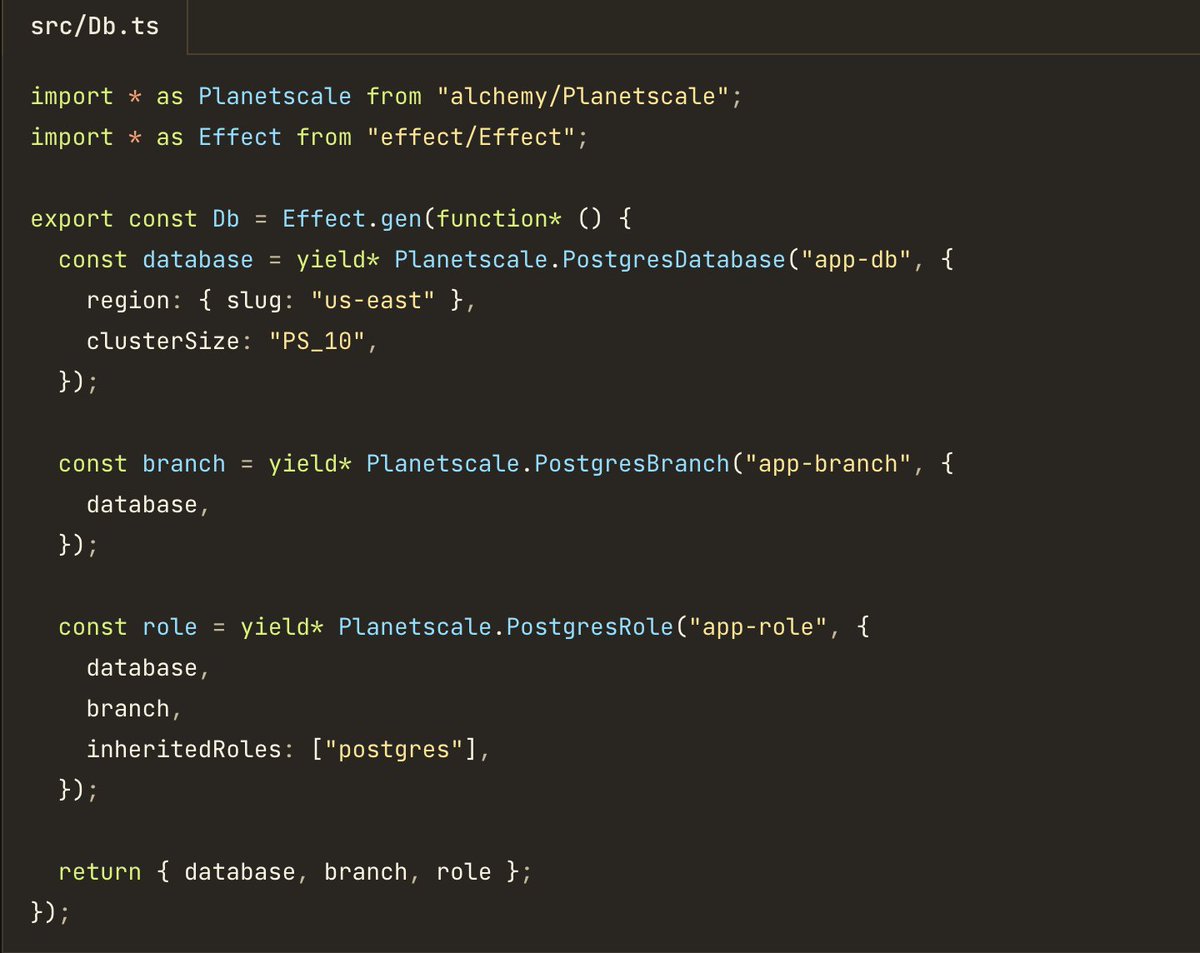
Alchemy v2 Planetscale cluster, with multiple logical DBs for my side projects. Feels good.
Inspired by x.com/jachands/status/204365…

18
1,724
sam retweeted

Jun 2
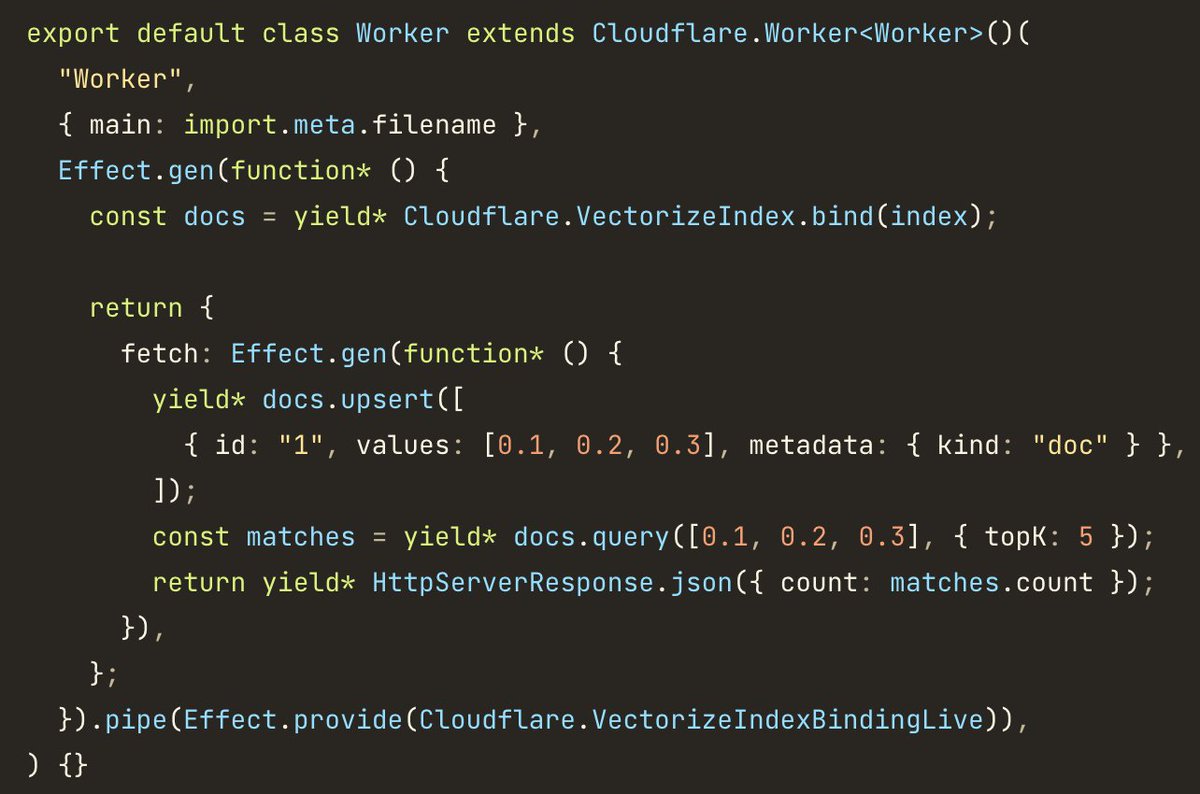
alchemy@2.0.0-beta.46 adds support for Vectorize Indexes and Metadata Indexes
1
1
12
947
Jun 2
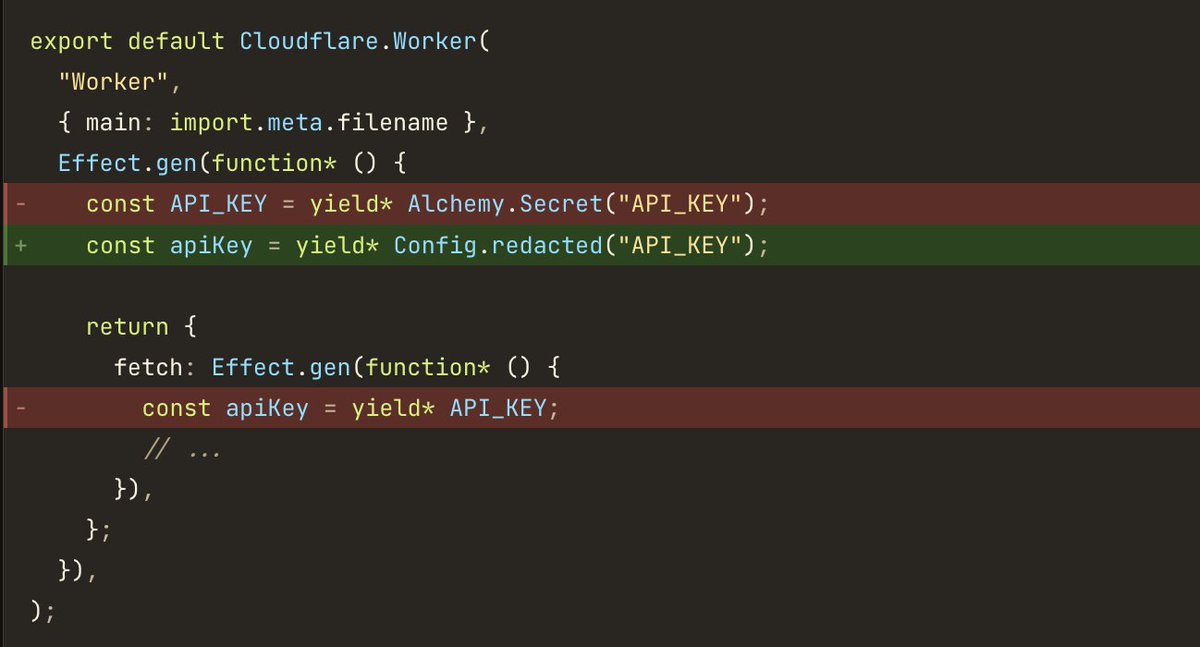
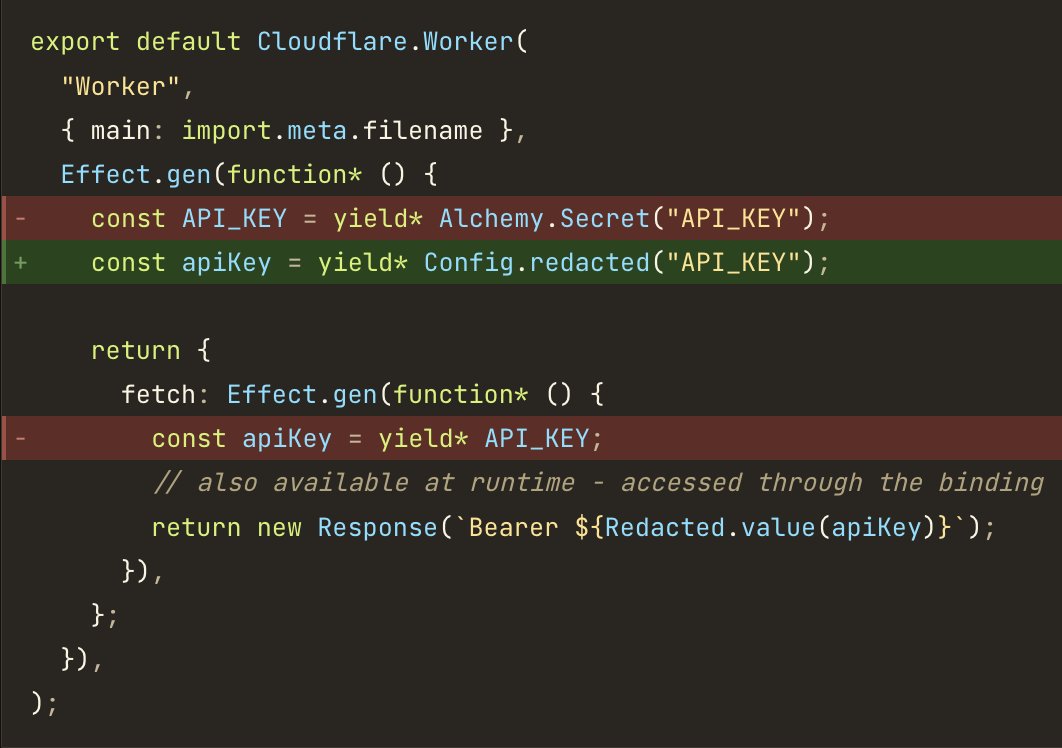
Also in this release, Alchemy.Secret and Alchemy.Variable are replaced with effect/Config
All Config values yielded in your Worker are now auto-bound to it as a secret_text Binding.
Jun 1
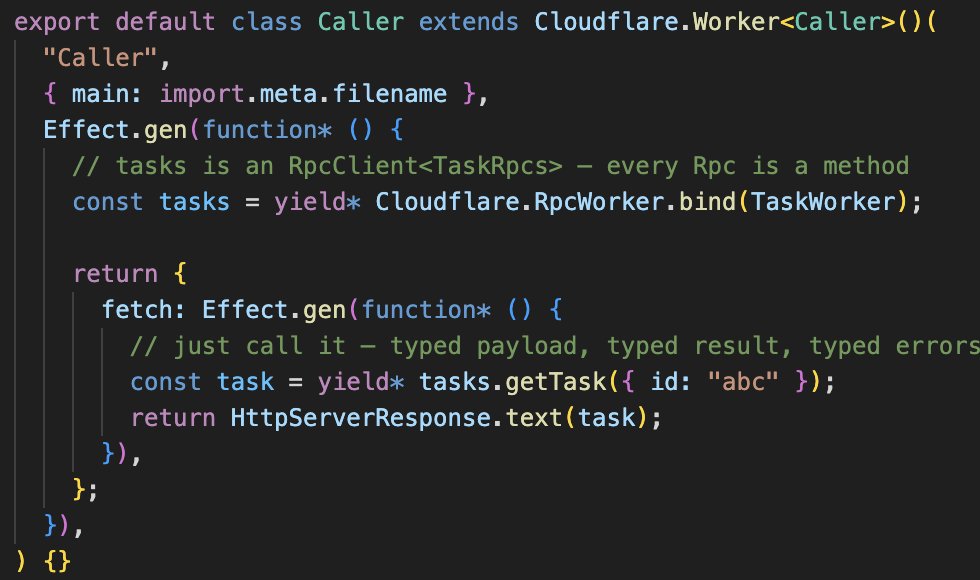
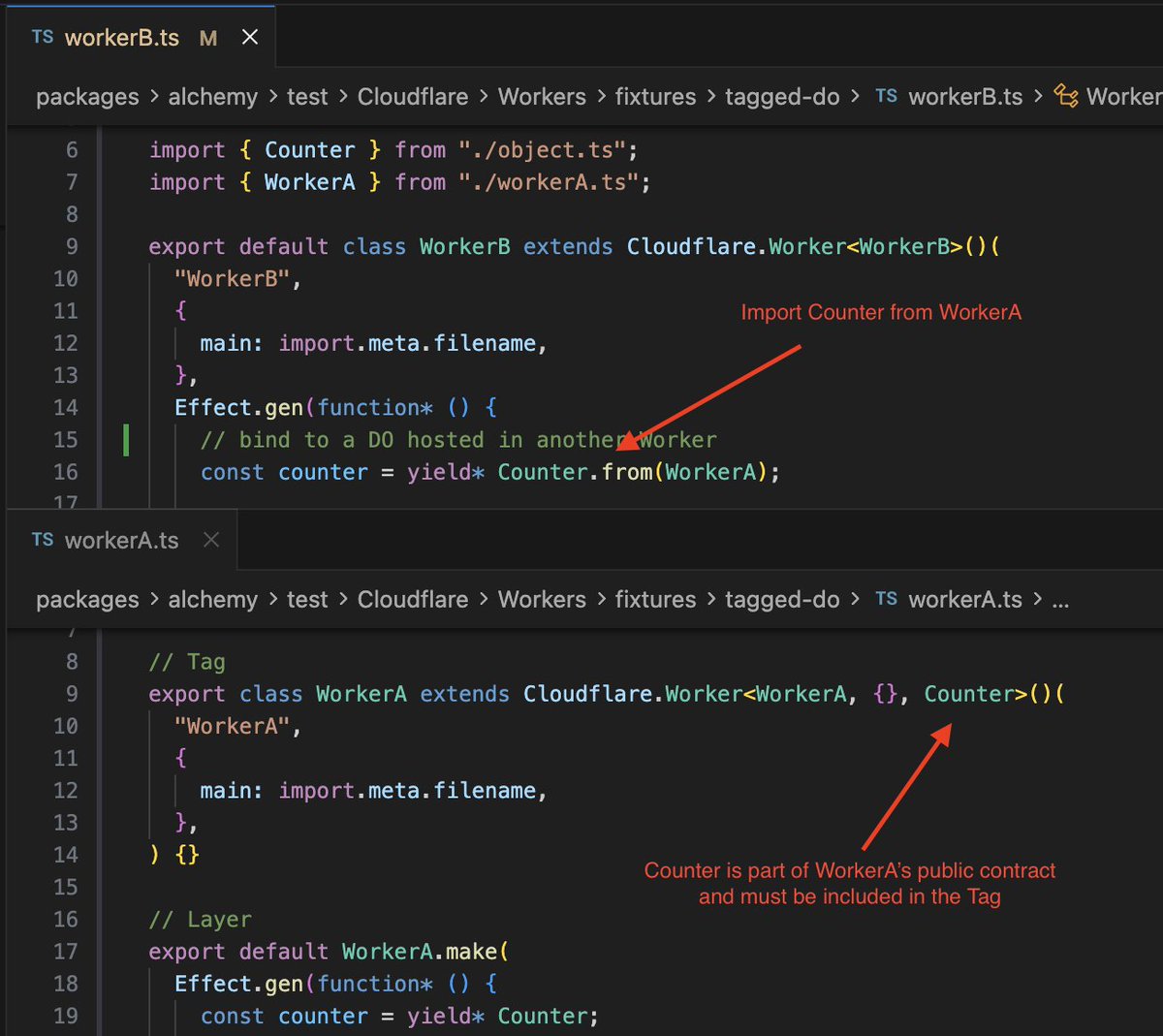
RpcWorker and RpcDurable make it easy to use Effect RPC end to end.
Binding to a RpcWorker or RpcDO constructs the RpcClient for you.
3
1
77
4,810
Jun 1
RpcWorker and RpcDurable make it easy to use Effect RPC end to end.
Binding to a RpcWorker or RpcDO constructs the RpcClient for you.
Jun 1

alchemy@2.0.0-beta.45 introduces RpcWorker and RpcDurableObjectNamespace, and replaces Alchemy.Variable/Secret with effect/Config.
v2.alchemy.run/blog/2026-05-…

2
5
115
26,412

sam retweeted

Four months into the Effect v4 beta, a lot has landed.
Here's a recap of everything from Schema, AI, Workflow & Durable Execution, Platform & Runtime, IndexedDB, and more:
effect.website/blog/effect-v…
6
15
157
6,877
May 27
We're thinking of replacing Alchemy.Secret and Variable with pure Effect Config.
yield* a Config in your Worker or Layer and it automatically binds to the Worker's env.
Removes the friction and extra steps of Alchemy.Secret
5
2
112
5,986