
🇮🇳🇨🇳🇨🇦 Founder penseum.com| prev. company acq.
Joined May 2022
- Tweets 556
- Following 283
- Followers 152
- Likes 611
40 Photos and videos











Pinned Tweet

Mar 12
i left notebooklm to solve a real problem in education.
@ Penseum we built the opposite.
no waiting — start learning in seconds
no walls of text — your tutor talks, visuals appear as it explains
no wasted time — flows with your understanding, deeper where you're stuck
gets smarter — every session knows you better than the last
@penseum_'s ai tutor. live now to our million users.
(i meant i left notebooklm as a user)
@KyushiThe
24
16
57
2,667
Jun 2
1/ every health app sucks. whoop, apple health, all of them. numbers with zero context.
I was measuring everything and still felt like shit.
so i built my own health brain. used @karpathy methods to create an AI clone of me that knows everything, injuries, diet, full history.
i call it Doppel
hooked it up to my weighing scale, whoop and uploaded all my history, every blood panel piped into one system that reasons across all of it like a doctor who never forgets a data point.
@bryan_johnson waddya think?
Apr 2

LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
3
2
10
342
Jun 2
5/ I built it on myself.
Now I'm opening it up. If you've got wearable data, bloodwork, or a DEXA scan and want your own AI body clone reading it all, here's the skeleton of my code
Repo👇
github.com/samkhalsa/health-…
1
2
66
Jun 2
6/ My progress so far:
Down from 237 → 220 lbs, my lowest in a year.
Fat percent 31% -> 29.2%
Will be taking another blood test to see how my biomarkers have moved in 1 month
2
64
May 31
We might not have a launch video like this, but we’ve delivered our AI tutor to 1.6 million students in less than 5 months.
No waitlist, no hype…. just real learning at scale.
This just gives me more confidence that we’re ahead and building faster than anyone 😮💨

AI is making kids dumber.
It should be making them geniuses.
Introducing Koji, the first AI tutor that gets kids to actually think. 👇
2
93
samit retweeted

May 27
This situation is actually very simple.
The issue is not whether Nicole ever mentioned me. She did mention me.
The issue is that mentioning someone is not the same as accurately crediting them.
From the outside, the podcast framing makes it sound like she was the solo founder/operator behind Glam Up and Sprout, and that everyone else was basically a footnote.
That is not accurate.
Does this situation seem petty & insignificant from the outside? Probably tbh.
But when you put your heart and soul into building something, credit matters. Not just to me, but to the team and Nicole too.
So yes, the record being accurate matters.
And so to be very clear, I did not “just do the dev work.”
In the interview, she says her account was the first to go viral. That is not true. The first account/post to go viral for Glam Up was the one I ran, and that account ended up accounting for roughly 40% of the views.
Similar situation with Sprout. A creator doing the faceless “war is over” content went viral first. Not her. She may have been the first to go viral with on-camera content, but she was not the first to go viral for the company.
I designed the actual Glam Up and Sprout apps end-to-end, excluding paywall videos.
I built the apps, funded/incorporated the companies, held majority ownership, recruited the team, and helped drive early growth alongside other cofounders and team members.
And this is not just about me.
Dillon deserves serious credit too. On the UGC/growth side, he helped build the bulk of the engine and has continued operating, testing, and improving it long after Nicole left in September 2025.
Sprout did not freeze in time when she left. The team kept building.
So when the story gets framed as one person running the show, it does not just sideline me. It sidelines Dillon and a lot of other people who materially contributed too.
Nicole contributed meaningfully to UGC/growth. I’ve never denied that.
This is also not about saying minority ownership means someone contributed nothing. That is not my point.
The point is that ownership, product, design, funding, building, and team contributions should be represented accurately.
But “I do everything but coding” is not true. Not even close. That is something she explicitly said.
On the Starter Story point: yes, I declined to go on it and requested she not do it. She asked me multiple times and I requested multiple times for her not to do it, but I eventually agreed. I was only told about Starter Story, not Superwall.
Either way, the issue was never simply “there was a podcast.” The issue was the overall framing once the interviews came out.
A later shoutout does not fix the core framing of the interview itself.
It’s also strange to say I’m building a public brand off her name when the whole reason this started is that she is building public content around apps I designed, built, owned, funded, and am still actively working on.
On the consulting point: I’ve said multiple times that 100% of any consulting money from this will go to charity. That is thoroughly documented, and once the calls are done, I’ll share the donation receipts.
I don’t want to personally profit from drama around apps my team is still operating.
I’m not trying to sell a course or become a coaching guru off this. I’m trying to correct the record.
She also has another app doing well. She could talk about that. Instead, the public content is largely around apps my team and I are still operating, which shifts copycat risk onto us while protecting her own current thing.
The implication that my UGC playbook was repurposed from her thesis is false.
Her thesis is a founder-level case study. My playbook is an operator-level creator program guide based on what we actually tested, ran, and scaled.
They overlap on some principles because they are about the same business. That does not make them copied.
Also, I’m not sure why the internal UGC course is being framed as a point against Sprout.
I’m not denying that Nicole recorded and contributed to creator training materials while she was working with the company. She did.
But that course was created for the company, used by the company, and refined with input from the team. Dillon, other team members, and I contributed feedback and operational knowledge from actually running the program: recruiting creators, coaching them, testing formats, improving scripts, and scaling what worked.
She was compensated for that work and still retains equity in the company.
My point is much narrower: my public UGC playbook is not a repackaged version of her thesis.
I’m human, not an LLM. I got angry and said things privately that I regret. I should have handled parts of this better.
But anything I said in anger came from feeling betrayed and exploited over the way my work, my team’s work, and our contributions were being represented. It was about credit, contribution, and character.
That does not mean I handled every message well. I didn’t.
But it also does not mean the public framing is accurate, or that this was some random one-sided harassment campaign.
I have screenshots too but I’m just trying not to turn this into a screenshot war.
These were not solo founder stories and the record should accurately reflect that.
29
3
111
10,623
samit retweeted
May 24
Second time I’ve seen @madebycol tell the Glam Up / Sprout story in a way that materially misrepresents who built what.
She contributed. But this was not a solo founder story, and I’m not going to keep letting my work, nor my team's work get erased.
It's frustrating, sad & disappointing.
May 23

This girl is insane. 4 different apps doing $150K/month each! 🥶
Community note
The co-founder and CEO of Glam Up and Sprout states the video inaccurately represents who built the apps and the featured person's role. x.com/_aaronpaul25/s… launchx.com/command-post/a…
111
32
1,061
217,710
samit retweeted
May 14
Cool to see this story getting attention. A short interview naturally compresses a lot of context, so I’ll add my side.
I was Co-founder & CEO across Glam Up and Sprout, led much of the product, growth, and execution behind both, and owned all the design engineering for Glam Up.
Glam Up reached 1M downloads in under 6 months, fully bootstrapped. Sprout is now bootstrapped to $250k MRR.
The highlight reel is fun to talk about. The operating system behind it is what’s actually valuable.
I’ve stayed mostly quiet online, but I’m going to start sharing the playbook behind building AI mobile web apps from 0 → scale.
Verified metrics below 👇
May 13

I saw the $400k MRR screenshots from @madebycol so of course I had to investigate
turns out she's built 4 apps—first one hit 150k MRR, second 250k MRR, latest two in stealth at 400k MRR combined. been running the UGC playbook for years. we went deep on the growth strats👇
0:00 Nicole's App Portfolio and Numbers
2:14 How GlamUp Was Born in a 10-Minute Phone Call
5:29 The Copycat App That Made Them $100K in a Week
9:49 The Viral TikTok Formula They Ran Across 40 Creators
17:16 The Referral System That Took Over TikTok Comments
22:43 What Happened When They Tripled the Price
24:50 The Discounted Paywall Strategy and Upgrade Triggers
30:28 Scaling Sprout to 250K MRR and 100M Monthly Views
31:42 Inside the Creator Course That Gets People Viral in 2 Weeks
44:42 The Paywall Test That Showed a 50% Conversion Increase
53:16 Advice Most App Founders Never Hear
11
8
191
28,614
samit retweeted

Apr 23
At @polarityco we're giving teams the validation they need to just do things.
Announcing project Keystone & Paragon.
30
25
99
9,792
Apr 22
nobody warned me about this part of SF.
you walk into a room and everyone assumes you can build something massive. like it's a given. that energy is wild.
but the flip side? they also assume you can lose it all tomorrow. 0 to 1 or 1 to 0, any day. no in between.
1
48
Apr 9
Every content creator should be thinking about building their own consumer app…
distribution would be crazy
3
82
Apr 4
day 240 of building @penseum_ — helping students learn better
worked on influencer bot today. found an influencer that got 100k views for $30 a post. Scaling that now.
meanwhile discovered someone in india quietly made $1k through our forgotten affiliate program. she's ignoring my emails but honestly respect the hustle
might be time to actually focus on affiliates again
3
7
129
Mar 30
Hosting a chill building/coding lounge at our HQ in Toronto tonight.
If you're around, come through
luma.com/qxc180vk
1
2
113


samit retweeted

Mar 18
Don't just collect data with analytics platforms. Act on it autonomously.
@humanbehaviorai gives you a self-improving product. Check it out
7
5
15
1,911
samit retweeted

Mar 17
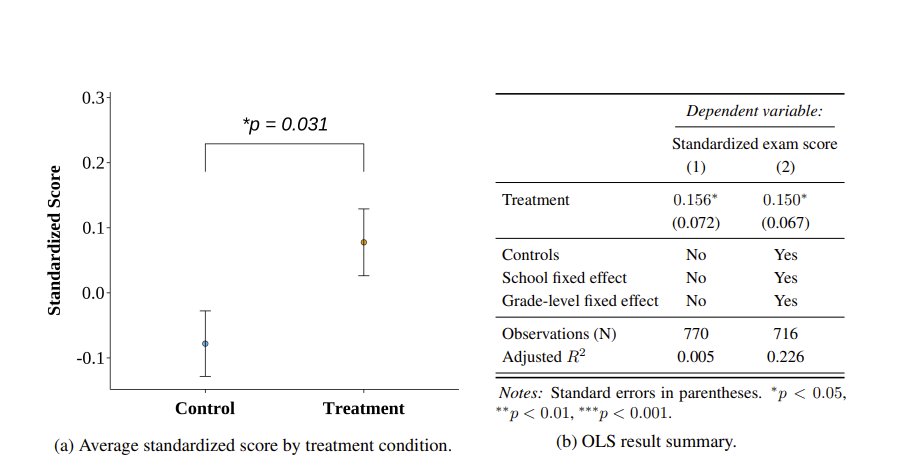
AI really can help education: Randomized controlled experiment on high school students found a GPT-4o powered tutor that personalized problems for students raised final test scores by .15 SD, "equivalent to as much as six to nine months of additional schooling by some estimates"

59
185
1,066
147,961