
Samuli Ripatti is director of @fimm_uh, director of @coecdg and professor of biometry at @helsinkiuni.
Joined August 2009
- Tweets 1,705
- Following 763
- Followers 1,443
- Likes 4,346
97 Photos and videos











Samuli Ripatti retweeted

12 Dec 2024
Out now! We established a platform for functional characterization of gene variants, providing insight for 315 LDLR variants. Functional data improves cardiovascular risk assessment, going beyond "pathogenic" and "benign" groups. Important for #FH
sciencedirect.com/science/ar…
2
3
11
552
Samuli Ripatti retweeted

22 Nov 2024
A FinnGen-based study led by FIMM Group Leader Elisabeth Widén has identified a gene defect in the TBPL2 gene that affects the maturation of oocytes, leading to infertility in women who have inherited the non-functional form of the gene from both parents.
helsinki.fi/en/news/genes/si…
2
3
628
Samuli Ripatti retweeted
8 Nov 2024
Exciting Postdoc Opportunity in Genomic Data Science!
Work with top experts at FIMM to develop tools for genetic and clinical risk prediction as part of the international #TeamPerMed consortium.
Learn more & apply by Nov 30:
jobs.helsinki.fi/job/Helsink…
#sciencejobs #postdocjobs

4
7
750
Samuli Ripatti retweeted
29 Oct 2024
📣 Exciting news! Don’t miss your chance to be part of a great postdoctoral opportunity! Stay tuned for the upcoming launch of the next NORPOD Postdoctoral Programme in Molecular Medicine! 👇
tinyurl.com/NORPOD
@NordicEMBL #postdoc #nordics #collaboration #EMBL #NordForsk
2
3
443
Samuli Ripatti retweeted
7 Oct 2024
Warm welcome to the Harvest time at FIMM seminar!
FIMM Director @samrip and new FIMM-EMBL Group Leaders will present their plans for the near future.
📅Wednesday Oct 30 at 13:15-15:00
🏢Biomedicum Helsinki, Lecture Hall 1
More information and registration: lyyti.fi/reg/FIMM_harvest_20…

5
6
1,118
Samuli Ripatti retweeted

3 Oct 2024
We are hiring! Looking for two postdocs. Topics: a) ancestry informed polygenic scores for mixed ancestry individuals and b) integrating polygenic risk models with clinically actionable rare variants for comprehensive disease risk assessment.
genomics.ut.ee/en/content/jo…
22
30
5,200
Samuli Ripatti retweeted
18 Sep 2024
Over 40 members of the FIMM community are currently enjoying the company of our @NordicEMBL colleagues, inspiring science, and the wonderful hospitality of our sister institute @NCMMnews in Oslo.
#NEPM24

ALT Opening slide with the text "Welcome to the 13th Nordic EMBL Partnership meeting" and the logos of the organisers and sponsors.

ALT Speaker of the partnership, Oliver Billker, opening the meeting.

ALT EMBL Director General Edith Heard presenting.

ALT FIMM team outside the meeting venue, Litteraturhuset.
2
18
643
Samuli Ripatti retweeted
28 Aug 2024
Welcome to the "Harvest time at FIMM" seminar on Oct 30! The event includes a talk by FIMM Director Samuli Ripatti, followed by presentations from the new FIMM-EMBL Group Leaders: Nina Mars, Arafath (Rafa) Najumudeen & Simone Rubinacci. Register by Oct 20: lyyti.fi/reg/FIMM_harvest_20…

ALT Seminar advertisement with a photo of an apple garden and a text: "Harvest time at FIMM: Introducing the 2024 cohort of FIMM-EMBL Group Leaders. October 30 2024, 13:15-15, Biomedicum Helsinki, LH1." Picture: Pixabay, Jill Wellington
5
12
908

13 Jun 2024
It was an entertaining defence: @juulia_partanen did a great job answering essential questions by the opponent @tuuliel
10 Jun 2024

Juulia Partanen, LL, will defend her doctoral dissertation "Strategies for Improving Power, Ancestral Diversity, and Clinical Translation in Complex Disease Genetics" on 13 June at 12:00. Professor Tuuli Lappalainen will serve as the opponent. Welcome! helsinginyliopisto.etapahtum…

1
18
1,120
Samuli Ripatti retweeted
13 Jun 2024
Professor Olli Kallioniemi has been awarded a 2.5 M€ Brain Gain grant for research into artificial intelligence in medicine. The grant will allow Kallioniemi to return to Finland and establish a group @FIMM_UH @HiLIFE_helsinki gradually, during 2024-25.
helsinki.fi/en/news/life-sci…
1
4
36
1,533
Samuli Ripatti retweeted

12 Jun 2024
Our flaghsip @intervene_eu paper is now published!
I think this is an important piece of work to elevate the stature of polygenic score to that of other well-studied risk factors
We provide country-specific cumulative incidence estimates for 18 diseases by PGS levels.
1
11
52
9,844
Samuli Ripatti retweeted
6 Jun 2024
Exciting start to our scientific retreat "Fit for FIMM - the 2024 Mix" in Korpilampi! During the first session, five of our FIMM-EMBL Group Leaders captivated the audience by presenting their impressive work.
Warm thanks to our sponsors for supporting the event!



3
14
798
Samuli Ripatti retweeted
28 May 2024
Hurry and apply now — the first NORPOD postdoc call is closing soon, so don't miss this exciting opportunity!
The core concept of the NODPOD programme is that all postdocs are supervised by two Group Leaders from the @NordicEMBL partnership, each from a different institute.

3 May 2024
The brand new NordForsk-funded @NordicEMBL postdoc programme #NORPOD now welcomes applications for seven exciting collaborative postdoc positions! FIMM is involved in four of these projects - for further details and links please see the thread.
projects.au.dk/nordic-embl-p…

5
6
3,321
Samuli Ripatti retweeted

23 May 2024
Kesällä vietetään suomalaisten kaksoskohorttitutkimusten 50-vuotisjuhlia @helsinkiuni @FIMM_UH 🍾

1
2
15
1,635
Samuli Ripatti retweeted

21 May 2024
Today, RGC has published an important paper in @Nature today, describing an analysis of close to a million human exomes (n=983,578) as a single variant call set (!). This is the largest and most diverse rare variant database created so far. This impressive feat is accomplished by a large @RegeneronDNA team led by my wonderful colleague @suganthibala.
@SunKat_y et al. Nature 2024
nature.com/articles/s41586-0…
What kind of insights can we learn from sequencing ~980k exomes? Below is a summary of the major findings from the paper.
Background of RGC
Regeneron Genetics Center (RGC) was established in 2014 just on time when major pharma companies started entering into the human genomics playfield. Last year, RGC celebrated its 10th year anniversary. I've written about the origin story of RGC before (x.com/doctorveera/status/171…).
The business model of RGC is simple and efficient. It collaborates with academic institutions across the world and provide sequencing as free service in exchange for access to genotypic and phenotypic data.
The first successful collaboration was made with Geisinger Health system (GHS) to sequence 100,000 individuals, which was soon followed by an avalanche of large collaborations. Some of our largest collaborators include UK Biobank (N=500k), GHS (N=175k) and Mexico City Prospective Study (N=150k). Today, RGC has more than 300 collaborations around the world. Just a few months ago, it surpassed the milestone of 2 million exomes. What is described in the current paper is only a fraction of that sample.
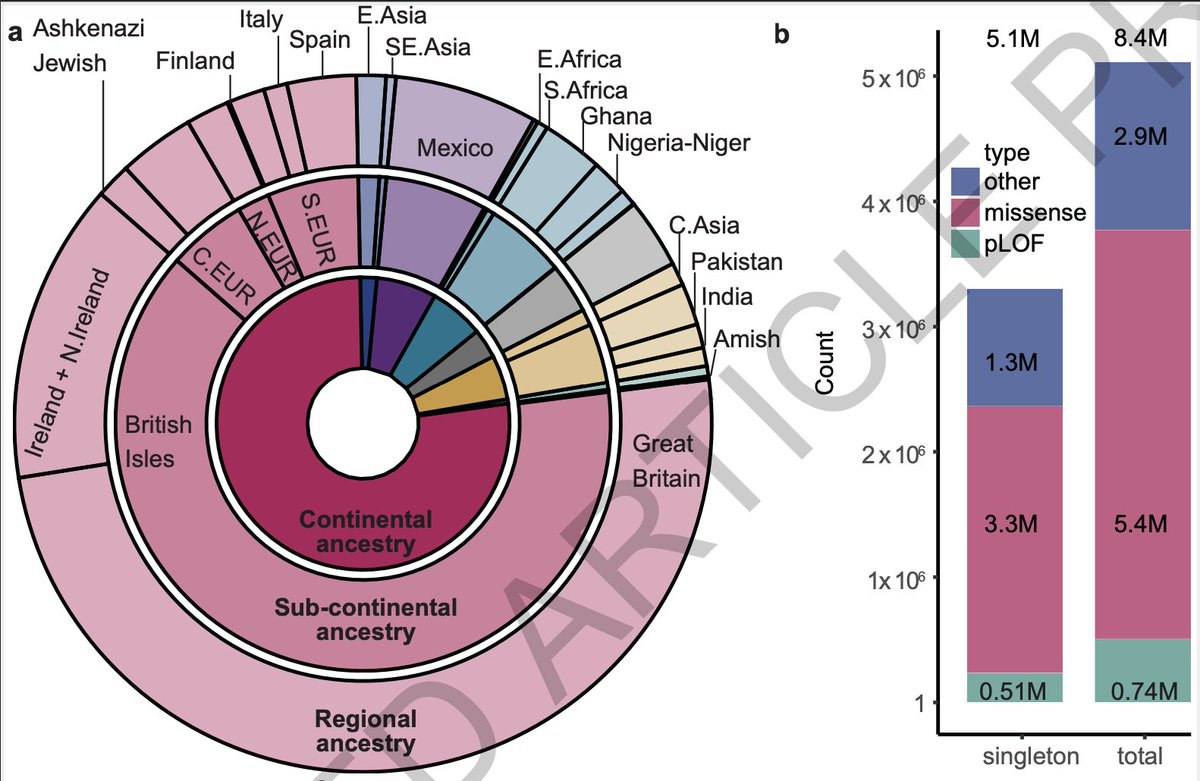
Diversity of samples
The 980k exome dataset come from a diverse set of samples. 23% (n=190k) of the participants are of non-European ancestries, the largest proportion to date for any similar datasets created so far. This includes both outbred populations and special populations enriched with communities with long-standing cultural history consanguineous and endogamous unions.
When it comes to human genetics, diversity is the key to making discoveries. Almost everyone agrees, and the field is embracing it now. But RGC is way ahead of the game. Just a few months ago, RGC partnered with other companies and laid the first foundational stone of what will become in a few years from now the world's largest genomics resource comprising half a million African Americans and Africans (x.com/doctorveera/status/171…).
Variant survey
Human genome is ~3 billion base pairs long. ~1% of which (~30 million base pairs), containing exons, is targeted by exome sequencing. By sequencing 980k exomes, the authors have captured ~16.5 million unique variants. That is, on average, one per every two base pairs across the exome.
The main goal of concentrating on exomes is to capture deleterious spelling errors in the genome, resulting in either loss or substantial decrease or, sometimes, increase in gene function. The authors have identified
- ~1.1 million predicted loss of function variants (pLOFs), ~50% of which are singletons (that is, seen in just one individual)
- ~10 million missense variants, 40% of which are singletons.
As expected, African ancestry groups had more variants (18% more) than any other ancestry group.
Footprints of selection
pLOFs in the human genomes are like bullet holes in aircraft returning from war. The genes untouched or rarely hit by the pLOFs are the most critical genes, without which life is probably impossible.
Studying ~980k exomes, the authors have identified ~4000 genes that are depleted of pLOFs, suggesting they are indispensable. For more than 20% of these genes, we are learning their critical requirement for normal life for the first time. Previous datasets were not able to quantify their mutation constraints because of the shorter length. Most of these genes were not linked to a human disease yet. The current list will inspire many Mendelian discoveries in the near future.
Regional selection
We have 10 times more missense variants than pLOFs, which means we can zoom into within genes and study which parts of a gene are indispensable and which parts aren't.
Not all parts of a protein are critical, but some parts are. For example, DNA binding regions of transcription factor protein, catalytic sites of an enzyme protein, transmembrane domains that forms the pore of channel proteins etc. With a knowledge of ~10 million missense variants from 980,000 humans, such critical regions are now starting to light up, illuminating the most crucial regions of proteins. For example, here is a trace of missense tolerance across different domains of cancer gene KRAS. Human genetics shows that the first 80 amino acids as the most critical region of KRAS, falling under the top 1 percentile of regional missense constrain metric.
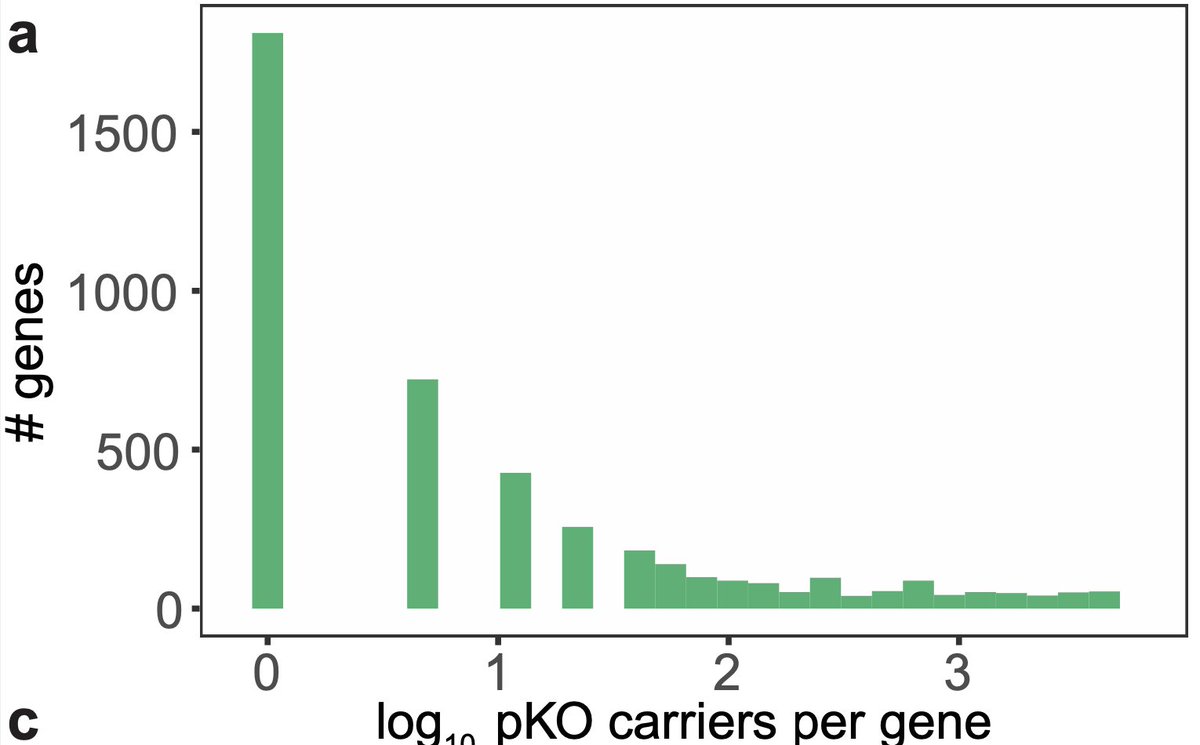
Human knockouts
The function of a gene in an organism is understood, typically, by studying the phenotypic consequences of deleting the gene. We cannot do such experiments in humans. But fortunately, Nature has already done this mutagenesis experiments for us. By studying naturally occurring human knockouts, we can assess the consequences of completely inhibiting a gene. This is crucial data for drug developers, as it informs about safety of drugs that act by inhibiting a gene or its product.
Studying the pLOFs across 980k humans, the authors have found 4.686 genes with at least one human knockout, suggesting that a life without these genes is likely possible. In line with that, the authors find that these genes are the ones that were mutationally least constrained (that is, they are enriched for pLOFs). For >1700 genes, we are learning for the first time humans completely lacking these genes do exist in this world. This is an incredible resource for drug development.
Clinical genetics insights
One of the most important use case of reference variant databases is to help clinical geneticists to identify disease causing variants in the patients. Historically, variant databases have been biased towards European populations. As a result, clinical geneticists struggle when they study exomes of non-European ancestry patients and often label the suspected variants as variants of unknown significance (VUS), because of a lack of proper reference database.
Cross-referencing the clinvar database with RGC dataset, the authors find European ancestry groups had more variants labelled "pathogenic" in Clinvar than African ancestry groups. Conversely, African ancestry groups had more VUS than European ancestry groups. This is not because Africans are protected from pathogenic variants, but simply reflect current databases are ignorant to clinically important variants in non-European ancestry individuals. With growing diverse databases such as the current one from RGC, the situation will soon change.
Conclusion
RGC has created one of the largest reference database for studying human exomes. The implications of this resource are many, spanning all areas of human biology from basic science to drug discovery.
Congrats to all my colleagues (@SunKat_y et al.) on this incredible accomplishment. And thanks to all RGC collaborators and research participants without whom such a dataset wouldn't exist.


22 Oct 2023

Something big happened a few days ago. Industry leaders in the genomics fields (Regeneron, AstraZeneca, Novo Nordisk and Roche) announced their collaboration with the US's largest black medical school, Meharry Medical College, Nashville, to establish what might become the UK Biobank of Africa--the largest genomics database of 500,000 volunteers from African ancestries (businesswire.com/news/home/2…)
The lack of diversity in genomics databases is today's greatest barrier to scientific progress. To break down this barrier, we need scientific minds, money, power and importantly, trust and engagement from the underrepresented communities. That can happen only when academia, industry and underrepresented communities join hands together to change the future.
Just a week ago, the Regeneron Genetics Center (RGC), AstraZeneca and AbbVie published the largest genomics database of Mexican-Americans (N=150,000) in collaboration with academic institutes in Oxford and Mexico (nature.com/articles/s41586-0…) (I'll write a separate post on this).
Now, RGC and other industry partners have established the Diaspora Human Genomics Institute (DHCI). Check out this website (thedhgi.org/) and the launch event.
Note, this is not just a commitment towards establishing a genomics database. The initiative will also ensure to uplift the African communities by funding the education and training of young African and African-American students and researchers in the genomics field.
One of those things about RGC that inspire me most is their commitment to improving diversity in the genomics databases. One of the many reasons why RGC is being flooded with top scientists from all over the world.


13
210
704
124,691

Do oral and non-oral lichen planus share the same genetics? Yes (20) and no (7)! Our new paper @AJHGNews using @FinnGen_FI reveals genetic heterogeneity between the two, with differential risk for autoimmune diseases and oral cancer cell.com/ajhg/fulltext/S0002…. 1/7
1
7
27
6,824
Samuli Ripatti retweeted

29 Apr 2024
The @NordicEMBL Partnership invites applications for postdoctoral fellows through our NORPOD program! Apply for one of 7 postdoctoral positions in molecular medicine! All details: shorturl.at/ijrX5
Application deadline: 31 May 2024
@FIMM_UH @NCMMnews @dandrite @mims_umea
11
20
7,546
Samuli Ripatti retweeted

22 Mar 2024
We are delighted to announce the publication of the #EULIFE charter of independent life science research institutes in @FEBS_Letters! This charter outlines 10 principles required for #researchinstitutes to flourish.
Read the charter here: doi.org/mnhd
@EULIFE_news
1
9
11
5,291
Samuli Ripatti retweeted

20 Mar 2024
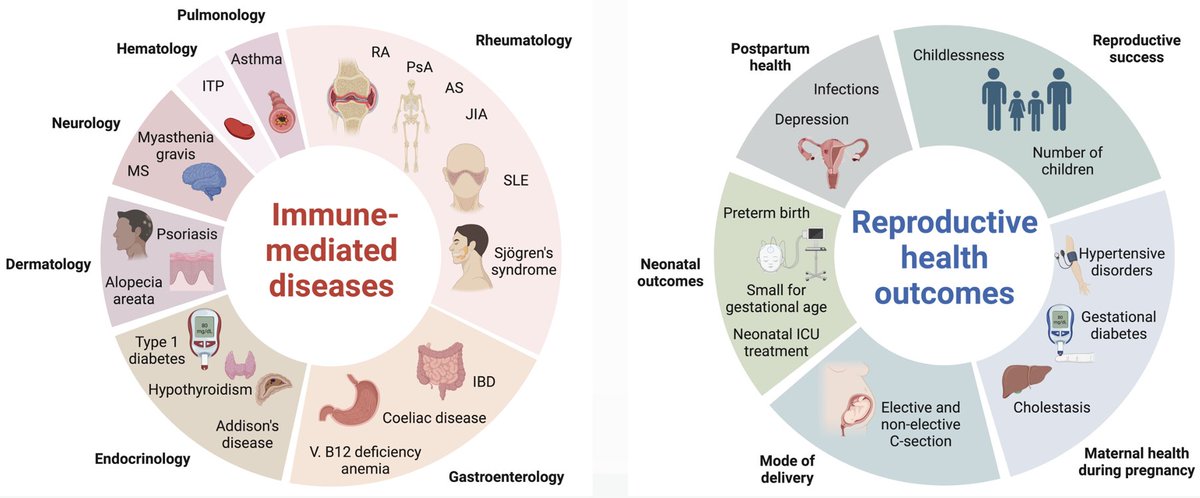
Many diseases (e.g. #T1D, #rheumatoidarthritis, #IBD, #asthma) impact men and women of reproductive age.
In a paper out today @RheumJnl we asked:
What is the impact of immune-mediated diseases on reproductive success and risk of maternal and perinatal outcomes?
📊 An evaluation & comparison across 19 diseases, with a focus on rheumatic diseases
🇫🇮 Population-based, nationwide registry study based on 5,339,804 individuals, from the FinRegistry study
🔗 doi.org/10.1093/rheumatology…
🔹Immune-mediated diseases have widespread impact on reproductive success, maternal health, and pregnancy outcomes. That being said, we saw considerable variation in impacts between diseases. And for most outcomes, the risks were at most moderate across diseases!
🔹Among rheumatic diseases, largest effects on reproductive success were seen in #rheumatoidarthritis, #JIA and #lupus. Lupus and #sjogren had the largest impacts on maternal and perinatal outcomes, moderate risks for other rheumatic diseases
Importance for clinical care:
Individuals with rheumatic diseases and their healthcare providers should actively discuss #familyplanning. This goes for both men and women. Pregnancies in women with rheumatic diseases are carefully followed up and medications tailored appropriately, which help reduce risks.
1
7
27
4,792
Samuli Ripatti retweeted
4 Mar 2024
In our latest paper @JCO_ASCO, we demonstrate how inherited factors perform for risk assessment in real-life breast cancer screening data. A special focus is on a breast cancer polygenic risk score (PRS), which is a more recently identified inherited risk factor.
🙍🏽♀️ 117,252 women in @FinnGen_FI
☢️693,730 breast cancer screenings from the nationwide Mass Screening Registry within @CancerRegFi
doi.org/10.1200/JCO.23.00295
Details follow in the thread:

1
7
40
6,226