
Google Deepmind Engineer - Turning cutting-edge research into products people love. Obsessed with agentic AI & human-AI collaboration.
Joined July 2010
- Tweets 1,587
- Following 435
- Followers 144
- Likes 1,053
63 Photos and videos













Jun 14
Do you guys think it's possible for India to build companies that can genuinely compete with OpenAI and Anthropic?
Or will we mostly remain consumers and users of AI built elsewhere?
16
sarvesh retweeted

Jun 14
If you had to bet $100 on one company achieving AGI first, where are you putting it? 💰

71
5
77
5,982

moving to SF and working on AI seems like the obvious best high level career path
I’m kinda surprised more software engineers aren’t doing this
Most of the people I know and most of my coworkers seem completely fine not doing this which seems odd
38
3
217
59,988

google is playing it smart
in a year, most people won't care about LLM performance gaps, but only speed and cost will matter more
you can see that strategy in their latest releases:
gemini 3.5 flash
gemma 4 12b
diffusion gemma 26b
scalability, cost, and speed will win the AI race
51
21
366
24,553
Jun 10
NotebookLM turning into a proper research agent with Gemini 3.5 is a nice upgrade.
One question → sources, citations, reports, even podcasts and slides.
Turning research directly into action is where the real value is.
1
187
Jun 10
Morning coffee tasted extra good today.
Stepped out for a bit, watched the light hit the plants, and just let the mind settle.
These small pauses are becoming my favorite part of the day. ☕ #SFLife
9

sarvesh retweeted

Jun 9
If you speak with friends in South Bay, having kids sounds scary, they drive all the time for activities, and have no life of their own
If you speak with friends in SF (Noe Valley), it sounds less scary, all activities are a block away and they go on retreats with their husbands and have fun for fun
It seems people choose their own pain and the answer is live in SF
53
10
403
220,797
Jun 9
Hot take: We don't need a more powerful model like Mythos right now.
GPT-5.5 (5.6 coming soon), Opus 4.8, and similar models are already more than capable for most use cases.
What we need to solve is the cost problem. If AI keeps getting significantly more expensive, 99% of developers won't be able to afford these models at scale and will end up going back to manual coding.
104
Jun 8
Nvidia is still the obvious AI trade, but the second-order winners might be the ones selling the picks and shovels behind the picks and shovels.
fool.com/investing/2026/02/1… #Nvidia #Semis #Investing
1
22
Jun 8
I’m more interested in AI tools that remove one annoying weekly task than in broad assistants that do everything. Narrow wins usually show up first.
blog.google/innovation-and-a… #AI #Productivity #Automation
10
Jun 8
Tech stocks are basically trading on one question right now: who captures the AI budget first? Cloud, chips, and infrastructure all still look like the center of gravity.
Source: cnbc.com/2026/05/08/us-tech-… TechStocks #Cloud #Semis
1
11
Jun 8
Tech’s AI story has shifted fast: first it was “automate everything,” now it’s “AI is expensive, use it responsibly.” The reality is somewhere in between — companies are cutting headcount to fund AI, but scaling AI at enterprise level can be surprisingly costly. #AI #BigTech #TechLayoffs
9
Jun 8
Tech companies have moved
From "use AI as much as possible, we need to use AI to automate everything and reduce our employees"
To "The AI bill is coming very high, it's becoming more and more expensive day by day, please use AI responsibly"
And in between laid off thousands of employees to fund AI and finding now that AI is more costly than human.
18
Jun 8
Saying LLMs are "just next-token predictors" dramatically understates what they actually do.
Yes, they predict the next token, but they don't do it one word at a time without thinking ahead. During training, they learn to predict entire sequences, using all the previous context and optimizing for many future tokens at once. In practice, they are constantly planning several steps ahead.
Also, they're trained on an enormous variety of data—not just human-written text, but code, financial data, weather reports, scientific papers, logs, and much more. To make accurate predictions across all these domains, they end up learning the underlying patterns and structures that generate them.
For example, predicting weather-related text requires understanding concepts like geography, seasons, sunlight, and climate cycles. Predicting code requires understanding programming logic. Predicting financial discussions requires understanding economic behavior.
A better way to think about LLMs is not as "next-token predictors" but as general-purpose simulators. Give them a prompt, and they simulate the world, system, or domain implied by that prompt.
It's kind of unbelievable that this works as well as it does—but somehow, it does.
14
sarvesh retweeted

May 21
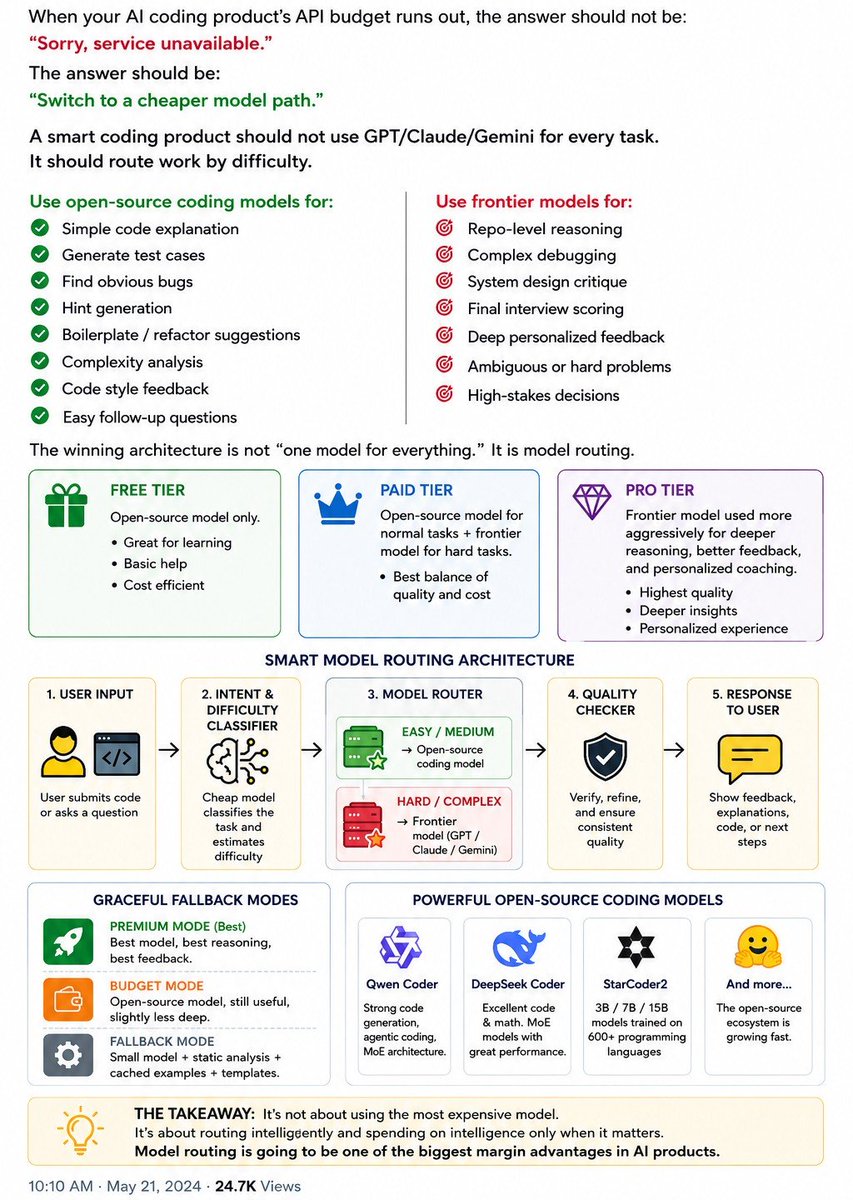
Uber burned through their entire 2026 AI budget in four months.
Their board wasn't happy. Half the dev teams in this country are one quarter away from the same problem.
CostHawk shows the AI spend driving your roadmap and what's drifted elsewhere. Before the board asks.

18
18
147
372,585
sarvesh retweeted

Jun 7
i am begging you to move to san francisco

ALT Richmond farmers market
94
4
330
62,387
Jun 5
Google DeepMind CEO Says AGI Is Coming Fast: 'We Don't Have Long to Prepare' share.google/yprlOmmmgJXQXtq…
1
33